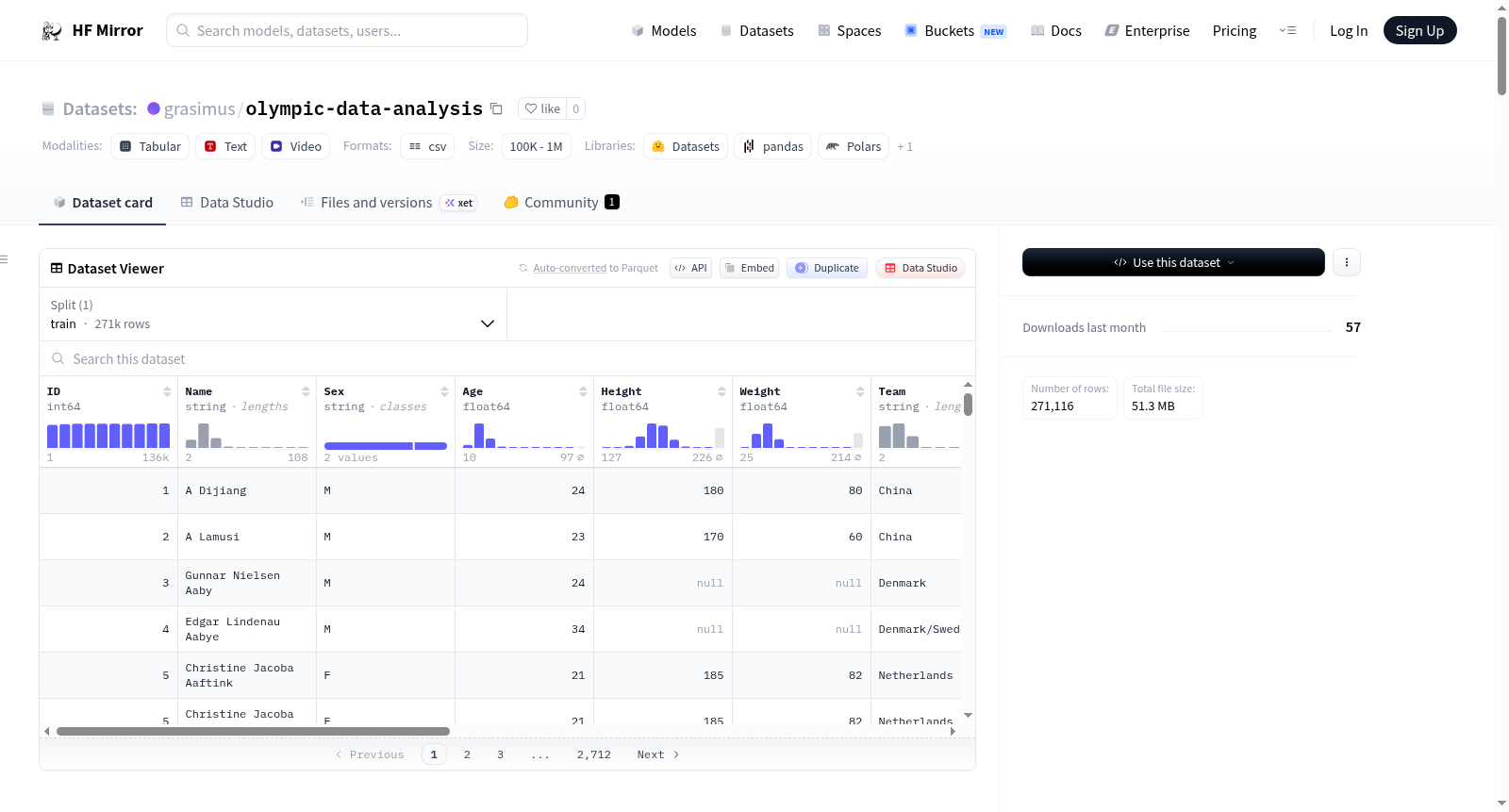
grasimus/olympic-data-analysis
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/grasimus/olympic-data-analysis
下载链接
链接失效反馈官方服务:
资源简介:
---
size_categories:
- 100K<n<1M
---
<video src="https://huggingface.co/datasets/grasimus/olympic-data-analysis/resolve/main/video3909235417.mp4" controls="controls" style="max-width: 720px;"></video>
# The analysis behind the glory: 120 Years of Data
## Project Overview
In this project, I performed a comprehensive Exploratory Data Analysis (EDA) on a dataset covering 120 years of Olympic history. My main goal was to transform a messy, historical dataset into a clean, analyzed resource to uncover the key physical, demographic, and geopolitical factors that determine an athlete's success.
## Dataset Description
The dataset provides a wide view of Olympic athletes over a century, from basic demographics to physical attributes and medal outcomes.
* **Demographics:** Age, Sex, Team/Country, Year.
* **Physical Metrics:** Height, Weight.
* **Contextual Data:** Sport, Event.
* **Target Variable:** Has_Medal (Created feature: 1 for winning any medal, 0 for none).
## Phase 1: Data Cleaning & Preprocessing
This historical dataset was naturally messy, containing missing records from early 1900s games and human data-entry errors. I followed a chronological process to clean it:
1. **Feature Engineering (Target Variable):** I converted the categorical "Medal" column into a binary `Has_Medal` integer column. This is crucial for calculating mathematical probabilities and success rates later in the project.
2. **Handling Missing Data (Smart Imputation):** I identified thousands of rows missing `Height` and `Weight`. Instead of using a generic average, I filled these missing values using the specific Mean of the athlete's **Sport and Sex**.
3. **Outlier Detection & Filtering:** I discovered extreme physiological anomalies, such as an adult athlete listed at 28kg being 1.83 meters, and participants with recorded ages over 80 during intense active competition years. I filtered these out as corrupted historical data.
**Why I chose Smart Imputation over Dropping Rows:** I decided to handle the massive amount of missing physiological data by imputing values based on Sport and Sex, rather than simply dropping the rows entirely. I chose this approach because dropping every athlete with a missing weight would have drastically reduced my dataset size and erased the history of athletes from earlier eras where measurements weren't strictly documented. By using targeted group averages (e.g., filling a missing female gymnast's height only with the average height of other female gymnasts), I preserved the massive scale of the dataset while ensuring the imputed numbers were biologically realistic. This allowed me to neutralize missing data without distorting the statistical realities of each distinct sport.
## The Gender Revolution: A Century of Change
**How has female participation in the Olympic Games evolved over the past 120 years, and does the data reflect broader social changes?**
The visualization below clearly maps a massive historical shift. From near-zero female participation at the dawn of the modern games, we see a steady climb, culminating in a dramatic acceleration towards equality in recent decades. The data isn't just about sports; it's a mirror of global social progress.

---
## National Efficiency: Quality over Quantity
**Which countries are the most "efficient" at the Olympics? Is it just about sending the largest delegation, or do some nations convert athletes to medals at a much higher rate?**
Simply counting total medals is biased toward massive countries like the US or the former USSR that send huge delegations. By calculating the "Conversion Rate" (total medals divided by unique participants), we reveal the true sporting powerhouses. The graph below shows the top 15 most efficient nations.

---
## The Age Factor: Is There a "Prime" Olympic Age?
**At what age do athletes peak in the Olympic games, and does winning a medal correlate with a specific age bracket?**
The KDE (Kernel Density Estimate) distribution reveals a distinct "Gold Zone" between the ages of 22 and 27. The density of medalists drops sharply after age 30. However, the long "tail" on the right side of the graph highlights fascinating "Veteran Anomalies" in sports like Equestrian or Shooting, where precise experience outweighs raw physical athleticism.

---
## Youth vs. Experience: Who Actually Wins?
**We often hear about teenage prodigies in the Olympics, especially in gymnastics. But statistically, do minors (under 18) or adults have a better "conversion rate" (medals per athlete)?**
While young athletes capture our imagination, the data proves the power of physical maturity. Not only do adults make up the vast majority of competitors (over 95%), but they also have a significantly higher conversion rate. The visualizations below demonstrate that years of physical development, mental resilience, and experience yield a higher return on investment (ROI) than the raw agility of youth.

---
## The Physical Paradox: Is There a "Perfect" Olympic Body?
**Do general physical attributes like Height and Weight correlate with winning a medal?**
The correlation heatmap below reveals a surprising "paradox." Look at the bottom row (`Has_Medal`): the correlation with Height (0.08) and Weight (0.08) is almost zero! Does this mean physical size doesn't matter in the Olympics? Not at all. It means that looking at the Olympics as a single macro-dataset is heavily misleading.

## Resolving the Paradox: Physical Clustering
**By isolating four distinct sports, the scatter plot below reveals clear "Physical Identities" (clusters). Gymnasts are concentrated in the bottom-left (short and light), while Basketball players dominate the top-right (tall and heavy). The "Perfect Olympic Body" doesn't exist in general—it is entirely sport-dependent.**

---
## The Outlier Advantage: Do You Need to be an Anomaly?
**Does being a physical "anomaly" give you an advantage, and in which sports is this most critical?**
By calculating the exact deviation of medalists from their specific *Event* and *Sex* averages, the horizontal bar chart below reveals the top 10 sports that heavily reward physical extremes. Unsurprisingly, "open" sports without weight classes—like Basketball and Volleyball—top the list. In these arenas, being a massive physical outlier is a distinct statistical advantage.

---
## Closing Thoughts: The Blueprint of a Champion
After diving into 120 years of Olympic history, it’s clear that winning isn’t just about "training harder"—it’s about a perfect alignment between a person's biology and the specific demands of their sport.
**The "Winning Formula" identified in this data:**
Through this research, I’ve shown that success is rarely random. It happens in the "Gold Zone" of the mid-20s, and it heavily favors those who fit a specific physical mold. While we often think of the Olympics as a broad competition, my analysis proves it is actually a collection of highly specialized niches. From the "Anomaly Advantage" in Basketball to the strict physical conformity of Gymnastics, the data tells a story of extreme specialization.
---
### Technical Stack:
Pandas & Numpy: Data cleaning and Feature Engineering.
Matplotlib & Seaborn: Professional EDA and statistical plotting.
提供机构:
grasimus
搜集汇总
数据集介绍
构建方式
该数据集基于跨越120年的奥林匹克历史数据构建,涵盖从1896年至2016年的运动员信息。构建过程涉及对原始历史数据的深度清洗与预处理,包括处理早期赛事记录缺失及人工录入错误。通过特征工程将奖牌类别转化为二元目标变量,并采用基于运动项目与性别的智能插补方法填补身高体重等生理指标的缺失值,同时过滤了生理异常与年龄异常等历史数据噪声,从而在保留数据集规模的前提下提升了数据的生物学合理性与统计可靠性。
特点
数据集覆盖了逾一个世纪的奥林匹克运动员数据,包含人口统计学特征如年龄、性别、国家与参赛年份,以及身高、体重等生理指标,同时涵盖运动项目、赛事等上下文信息。其核心特点在于通过衍生变量“是否获奖牌”构建了可用于概率计算与成功率分析的二分类目标,并借助可视化分析揭示了女性参与度演变、国家奖牌转化效率、运动员年龄峰值分布以及运动项目特异性生理聚类等深层规律,为跨学科研究提供了丰富维度。
使用方法
该数据集适用于体育科学、社会学及数据科学领域的探索性分析与建模研究。使用者可基于清洗后的结构化数据,进行运动员表现预测、国家体育效率评估或历史趋势分析。通过集成Pandas、NumPy等工具进行数据操作,并利用Matplotlib、Seaborn等库实现统计可视化,研究者能够深入探讨生理特征与运动表现的关联、社会因素对体育参与的影响,或构建机器学习模型以识别影响竞技成功的关键因素。
背景与挑战
背景概述
奥林匹克数据分析数据集源于对现代奥运会120年历史记录的深度挖掘,由数据科学家grasimus于近期构建并公开。该数据集旨在系统梳理自1896年首届雅典奥运会至2016年里约奥运会的运动员参赛信息,涵盖人口统计学特征、生理指标、运动项目及奖牌获得情况等多维度变量。核心研究问题聚焦于揭示影响运动员竞技成功的多重因素,包括年龄峰值、性别参与演变、国家参赛效率以及运动特异性生理特征等。通过整合跨世纪的历史数据,该资源为体育科学、运动生理学及社会变迁研究提供了实证基础,推动了基于大数据的竞技体育规律探索。
当前挑战
该数据集首要挑战在于解决历史体育数据中的异质性与缺失性问题。早期奥运会记录存在大量生理指标(如身高、体重)的空白,且伴随人为录入错误与异常值,需采用基于运动项目与性别的智能插补策略以保持数据规模与生物合理性。其次,构建过程需克服跨世纪数据标准化难题,包括统一不同届次奥运会的项目分类、奖牌记录格式及国家名称演变,确保时间序列的一致性。此外,分析层面需应对运动项目间的高度特异性,避免将整体相关性误用于细分领域,例如揭示“生理悖论”背后不同运动对体型需求的本质差异。
常用场景
经典使用场景
在体育科学与历史数据分析领域,olympic-data-analysis数据集常被用于探索运动员表现与多维因素间的关联。研究者通过该数据集进行探索性数据分析,揭示年龄、性别、生理指标及国家背景如何影响奥运奖牌获取概率,从而构建运动员成功的预测模型。
解决学术问题
该数据集有效解决了体育统计学中关于运动员表现决定因素的长期争议,如生理特征与运动成绩的相关性、年龄对竞技峰值的影响,以及性别平等在体育参与中的演进轨迹。其意义在于提供了跨越120年的纵向证据,为运动科学、社会学及数据挖掘领域的假设检验奠定了实证基础。
衍生相关工作
基于该数据集衍生的经典工作包括国家效率指标构建、运动员生理聚类分析,以及跨时代性别参与度研究。这些成果进一步推动了体育数据标准化进程,并为后续研究如竞技表现预测、运动人才挖掘等提供了方法论参考。
以上内容由遇见数据集搜集并总结生成


