ReasonVQA
收藏arXiv2025-07-22 更新2025-07-24 收录
下载链接:
https://duong-tr.github.io/ReasonVQA
下载链接
链接失效反馈官方服务:
资源简介:
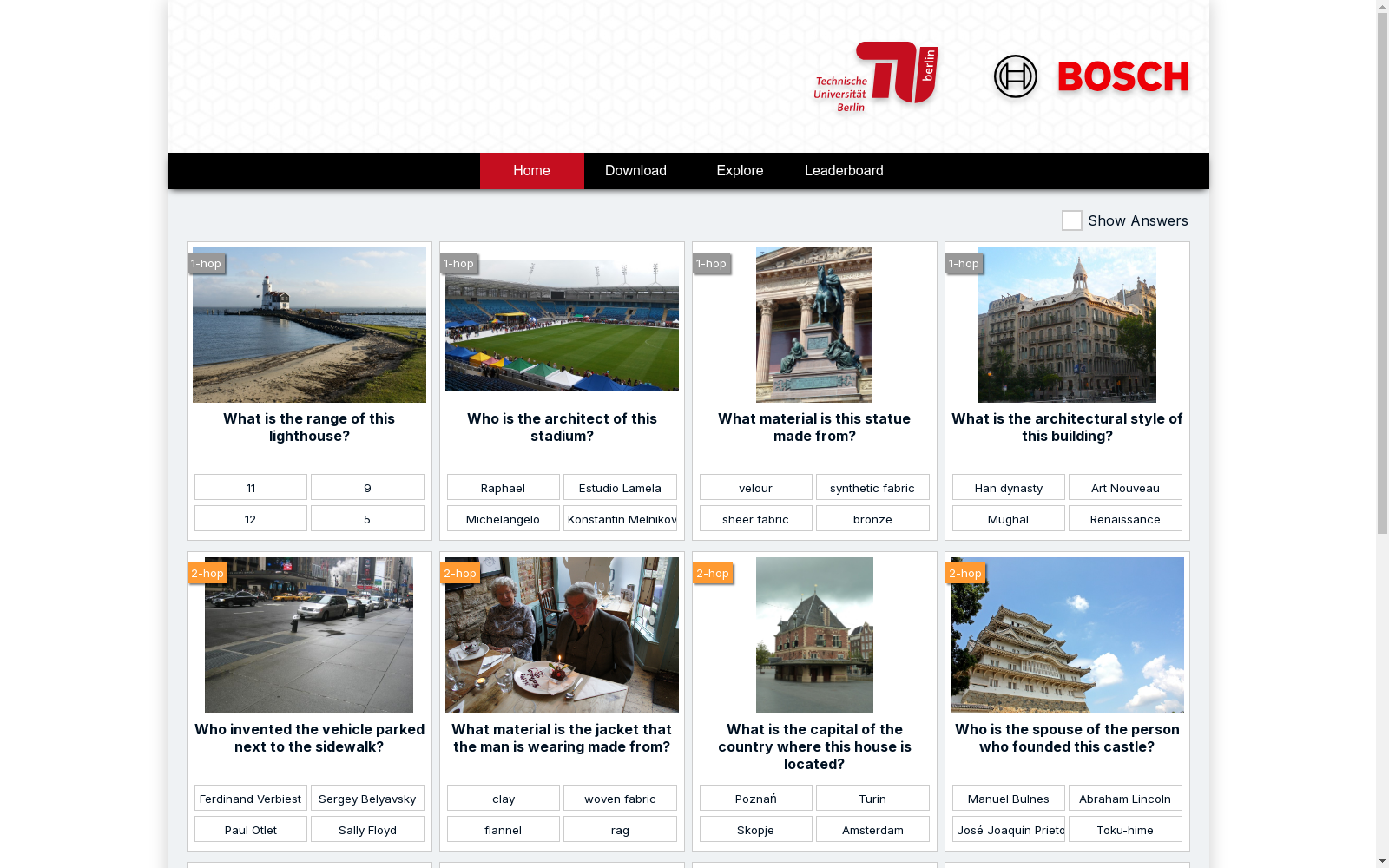
ReasonVQA是一个针对视觉问答任务的新数据集,它集成了结构化的百科全书知识,并通过低成本框架构建,能够生成复杂的多跳问题。该数据集包含大量问题,分为1跳、2跳和3跳三个复杂度级别,要求模型具备强大的多跳推理能力。数据集构建过程包括外部知识整合、问题生成和数据集构建三个步骤。数据集利用了Wikidata和Visual Genome等知识库和图像数据源,并通过模板生成问题和选项,同时进行了答案分布平衡和数据集分割,以减少偏差并提高模型的挑战性。
ReasonVQA is a novel dataset tailored for visual question answering (VQA) tasks. It integrates structured encyclopedic knowledge and is built using a low-cost framework, enabling the generation of complex multi-hop questions. This dataset contains a large volume of questions categorized into three complexity levels: 1-hop, 2-hop, and 3-hop, which require models to possess strong multi-hop reasoning capabilities. The development pipeline of this dataset includes three key steps: external knowledge integration, question generation, and dataset construction. The dataset leverages knowledge bases and image data sources such as Wikidata and Visual Genome, generates questions and answer options via template-based methods, and conducts answer distribution balancing and dataset splitting to reduce biases and enhance the challenge for models.
提供机构:
博世人工智能中心, 柏林工业大学, 弗劳恩霍夫FOKUS研究所
创建时间:
2025-07-22
搜集汇总
数据集介绍
构建方式
ReasonVQA数据集通过集成结构化百科全书知识,采用低成本框架自动生成复杂的多跳问题。构建过程分为三个关键步骤:外部知识集成、问题生成和数据集构建。首先,将图像中的标注对象与外部知识图谱中的实体进行链接;其次,通过知识图谱遍历半自动生成多跳问题;最后,通过平衡答案分布和数据集分割确保训练集与测试集的答案分布一致。该方法显著降低了人工标注成本,同时支持大规模数据扩展。
使用方法
该数据集支持两种评估模式:开放式回答和多项选择。研究者可通过零样本评估测试模型的多模态推理能力,或通过微调提升模型性能。使用需注意:1)建议采用语义相似度匹配评估开放式回答;2)多跳问题需结合外部知识图谱进行推理;3)平衡版数据集(ReasonVQA-B)适用于偏差敏感性研究。数据集提供20个预定义知识域筛选功能,便于开展领域特异性研究。
背景与挑战
背景概述
ReasonVQA是由Bosch人工智能中心与柏林工业大学等机构的研究团队于2025年提出的视觉问答(VQA)基准数据集。该数据集通过结构化百科全书知识的自动集成,构建了包含420万个复杂多跳问题的规模,较现有知识增强型VQA数据集扩大了一个数量级。其核心创新在于融合视觉场景图与Wikidata知识图谱,要求模型进行跨模态的多步推理,例如回答"这座教堂所在国家的首都是哪里"这类需要串联地理与建筑知识的复合问题。该数据集采用低成本半自动框架构建,利用Visual Genome和Google Landmarks v2的图像资源,通过模板化方法生成问题,显著提升了VQA任务对世界知识依赖和逻辑推理能力的评估维度。
当前挑战
ReasonVQA针对两大挑战领域提出解决方案:在领域问题层面,传统VQA数据集局限于物体识别和属性问答,而该数据集要求模型整合分散在多段落文本中的外部知识进行多跳推理,现有最先进模型的准确率平均下降达23.5%。在构建过程中,研究团队需解决知识图谱与视觉标注的异构对齐问题,通过WordNet synset实现视觉概念与Wikidata实体的映射;同时设计182个主模板和100个子句模板来平衡问题复杂度与语法正确性,最终通过迭代式答案分布平衡算法将头部答案比例降低33.4%,有效缓解了模型通过答案频率偏差取巧的问题。多跳问题生成中3-hop问题的语义连贯性维护,以及场景图信息引入带来的上下文一致性保障,均是构建过程中的关键技术难点。
常用场景
经典使用场景
ReasonVQA数据集在视觉问答(VQA)领域中被广泛用于评估模型的多跳推理能力和外部知识整合能力。该数据集通过结合结构化知识图谱(如Wikidata)和视觉场景图,生成了包含1-hop、2-hop和3-hop问题的复杂问题集。经典使用场景包括测试模型在需要多步推理和外部知识支持的任务中的表现,例如回答“这座教堂所在国家的首都是哪里?”这类问题。
解决学术问题
ReasonVQA解决了视觉问答领域中模型缺乏多跳推理和外部知识整合能力的核心问题。传统VQA数据集主要关注简单的物体识别和属性问答,而ReasonVQA通过引入结构化知识和多跳问题,推动了模型在复杂推理任务中的研究。其意义在于为学术界提供了一个可扩展、低成本的基准数据集,促进了知识增强型VQA模型的发展。
实际应用
在实际应用中,ReasonVQA可服务于智能助手、教育系统和跨模态信息检索等领域。例如,在智能导游系统中,模型可通过分析图像中的地标(如教堂)并结合知识图谱,回答游客关于建筑历史、地理位置等多跳问题。此外,其自动化构建框架可快速适配医疗、零售等垂直领域,生成领域特定的视觉问答数据。
数据集最近研究
最新研究方向
近年来,视觉问答(VQA)领域的研究逐渐从简单的对象识别和属性问答转向需要多跳推理和外部知识支持的复杂问题。ReasonVQA数据集的推出填补了这一研究空白,其通过自动整合结构化百科全书知识,生成了包含多跳问题的海量数据集。该数据集不仅规模远超现有同类数据集,还通过严格的平衡处理减少了答案分布的偏差,为评估模型在多跳推理和知识利用能力方面提供了高标准基准。当前,基于ReasonVQA的前沿研究主要集中在探索多模态大语言模型(如GPT-4o、Qwen2.5-VL)在复杂知识推理任务中的性能极限,以及通过微调策略(如LoRA)提升模型对跨模态知识关联的理解。这些研究不仅推动了VQA模型在医疗、教育等垂直领域的应用,也为构建更接近人类认知水平的通用人工智能提供了重要实验平台。
相关研究论文
- 1ReasonVQA: A Multi-hop Reasoning Benchmark with Structural Knowledge for Visual Question Answering博世人工智能中心, 柏林工业大学, 弗劳恩霍夫FOKUS研究所 · 2025年
以上内容由遇见数据集搜集并总结生成


