fenrix-financial-news-lake
收藏Hugging Face2026-06-30 更新2026-07-01 收录
下载链接:
https://huggingface.co/datasets/Scottswi/fenrix-financial-news-lake
下载链接
链接失效反馈官方服务:
资源简介:
FENRIX Financial News Lake是一个为FENRIX研究项目构建的归一化金融新闻数据湖。该数据集基于FNSPID数据集,包含13,057,514篇金融新闻文章,文章被归一化到一个规范的模式中,并包含来源追溯信息。数据时间跨度从1914年9月16日到2020年6月11日,以Parquet格式存储,大小约为1.9 GB。数据模式包括关键字段:article_id(数据湖内的唯一ID)、source_id(来源标识符,例如fnspid)、title(文章标题)、body_text(完整的文章正文,当可用时)、published_at_utc(发布时间戳)、tickers_raw(提及的股票代码JSON数组)和canonical_url(去重键)。数据来源单一,全部来自fnspid源。数据集采用CC BY-NC 4.0许可证(按来源许可),但聚合了第三方内容,每个来源有自己的许可证条款,其中一些限制为非商业用途,仅用于学术研究。该数据集适用于金融新闻分析、自然语言处理、时间序列分析等研究任务。
FENRIX Financial News Lake is a normalized financial news data lake constructed for the FENRIX research project. This dataset is based on the FNSPID dataset and contains 13,057,514 financial news articles, normalized into a canonical schema with source traceability. The data spans from September 16, 1914, to June 11, 2020, stored in Parquet format with a size of approximately 1.9 GB. The schema includes key fields: article_id (unique ID within the data lake), source_id (source identifier, e.g., fnspid), title (article title), body_text (full article body when available), published_at_utc (publication timestamp), tickers_raw (JSON array of mentioned stock tickers), and canonical_url (deduplication key). The data source is singular, entirely from the fnspid source. The dataset uses the CC BY-NC 4.0 license (by source), but it aggregates third-party content, each with its own licensing terms, some restricting non-commercial use and for academic research only. It is suitable for research tasks such as financial news analysis, natural language processing, and time series analysis.
创建时间:
2026-06-30
原始信息汇总
FENRIX Financial News Lake 数据集概述
基本信息
- 数据集性质:私有数据集,仅供团队访问,属于 FENRIX 研究项目的标准化金融新闻数据湖。
- 数据规模:包含 13,057,514 篇文章。
- 数据来源:仅来源于 FNSPID 数据集。
- 时间范围:1914-09-16 至 2020-06-11。
- 数据大小:标准化后约 1.9 GB(Parquet 格式)。
- 许可证:CC BY-NC 4.0,需遵循各来源许可条款,建议仅用于学术研究。
数据模式(Schema)
- 关键字段:
article_id:数据湖内唯一文章标识符。source_id:来源标识符(例如 "fnspid")。title:文章标题。body_text:文章正文(如有)。published_at_utc:发布时间(UTC)。tickers_raw:提及的股票代码 JSON 数组。canonical_url:去重键。
来源清单
| 来源标识符 | 记录数 | 许可证 |
|---|---|---|
| fnspid | 13,057,514 | CC BY-NC 4.0 |
许可与溯源
- 数据集聚合来自第三方来源的内容,每个来源有其独立的许可条款,部分来源限制商业使用,建议仅用于学术研究。
使用方式
- 可通过
datasets库加载: python from datasets import load_dataset ds = load_dataset("Scott-Switzer/fenrix-financial-news-lake", split="train") print(len(ds))
引用建议
-
如研究中使用了本数据集,请引用:
@software{fenrix_financial_news_lake_2026, author = {FENRIX Team}, title = {FENRIX Financial News Lake}, year = {2026}, url = {https://huggingface.co/datasets/Scott-Switzer/fenrix-financial-news-lake} }
搜集汇总
数据集介绍
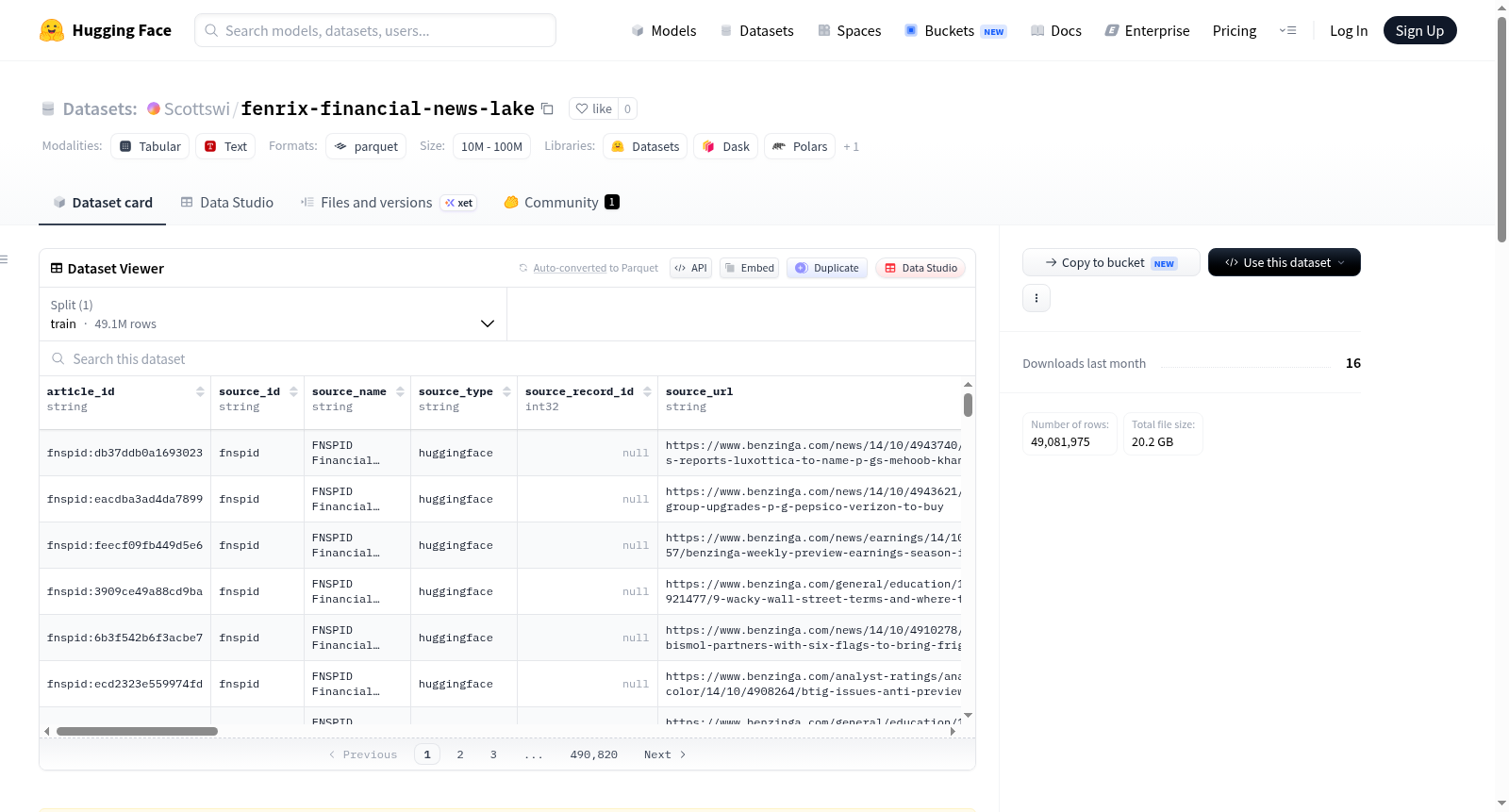
构建方式
在金融新闻分析领域,高质量、大规模且结构化的语料库是驱动模型训练与实证研究的基础。FENRIX Financial News Lake数据集正是为此而生,它作为FENRIX研究项目的标准化金融新闻数据湖,汇聚了来自FNSPID数据集的逾1300万篇金融新闻文章。这些文章覆盖了从1914年至2020年跨越一个多世纪的时间范围,构建过程着重于数据归一化处理,所有原始数据均被转换为统一的规范模式,并通过source_id字段实现来源溯源追踪。数据集以约1.9 GB的Parquet格式高效存储,确保了数据加载与查询的性能。
特点
该数据集最显著的特点在于其庞大的规模与长期的时间跨度,逾1300万篇详尽记录了百年间金融市场的动态。数据遵循统一的规范化模式,包含article_id、source_id、title、body_text、published_at_utc等关键列,其中的canonical_url字段专为去重设计,保证了数据的简洁性。tickers_raw字段以JSON数组形式列出文章提及的股票代码,极大便利了金融事件与股价关联的研究。数据集采用CC BY-NC 4.0许可协议,明确限定于学术研究使用,体现了对原始来源版权与使用规范的尊重。
使用方法
用户可以通过Hugging Face的datasets库便捷地加载该数据集。在Python环境中,仅需调用`load_dataset("Scott-Switzer/fenrix-financial-news-lake", split="train")`即可获得训练集的全部样本。数据集加载后,用户可以自由访问各字段,利用article_id进行唯一标识,通过body_text获取全文内容,并利用tickers_raw解析与股票代码相关的金融信息。对于学术研究,引用该数据集时应参考其提供的BibTeX条目,以确保贡献的恰当归属。
背景与挑战
背景概述
FENRIX Financial News Lake是一个专为FENRIX研究项目构建的标准化金融新闻数据湖,由FENRIX团队于2026年创建,收录了来自FNSPID数据集的超过1300万篇文章,时间跨度从1914年至2020年,涵盖百年金融信息。该数据集的核心研究问题在于如何将异构的金融新闻源统一为规范化的模式,并保留来源溯源能力,以支持金融文本挖掘与量化分析领域的研究。通过提供约1.9 GB的Parquet格式数据,它显著降低了金融自然语言处理研究中的数据预处理门槛,为情感分析、事件驱动交易策略及市场信息提取等方向提供了坚实基础,已在学术研究领域产生重要影响。
当前挑战
该数据集所解决的领域问题在于金融新闻数据的异质性与不可比性——原始数据来源分散、格式不一,缺乏统一的标识符和时间戳,阻碍了跨语料库的联合分析与模型训练。为此,构建过程中需应对多项挑战:一是将13M+篇源自单一来源FNSPID的文章精炼为通用规范模式,确保title、body_text、published_at_utc等关键字段的完整性与一致性;二是设计有效的去重机制,通过canonical_url实现无重复索引;三是管理复杂的许可溯源问题,确保CC BY-NC 4.0等第三方条款在聚合后的合规使用;四是维护大规模时间序列数据的可查询性,支持从1914年至2020年间任意子区间的快速检索。
常用场景
经典使用场景
该数据集汇聚了超过1300万篇来自FNSPID来源的金融新闻文章,时间跨度自1914年至2020年,覆盖百年金融历史。经典使用场景包括金融文本的预训练与微调、事件驱动的股票走势预测、以及基于新闻情感的因子建模。研究者可利用其丰富的元数据(如发布时间、提及的股票代码)进行时间序列分析与多模态金融推理任务。
衍生相关工作
该数据集源自FNSPID项目,其规范化设计催生了多项经典工作,包括基于百万级金融新闻的预训练语言模型(如FinBERT的扩展版)、事件-股价关联知识图谱的构建方法,以及异构新闻源的联合分析框架。后续研究还在此基础上开发了时效性感知的新闻表示学习模型,推动了金融时间序列与自然语言处理的交叉创新。
数据集最近研究
最新研究方向
该数据集汇集了FNSPID来源中超过1300万篇金融新闻文章,时间跨度从1914年至2020年,覆盖了百年金融史上的重大事件与市场波动。当前前沿研究方向聚焦于利用时序金融新闻进行大规模事件驱动的量化分析,特别是结合自然语言处理技术从历史媒体报道中挖掘市场情绪演变、危机传播模式以及资产定价的长期叙事影响。该数据湖的规范化架构与标普500公司代码映射,为构建可复现的金融语言模型、回测基于新闻的算法交易策略以及研究信息扩散对市场微观结构的作用提供了坚实基础,在计算金融与经济学交叉领域具有里程碑式的意义。
以上内容由遇见数据集搜集并总结生成


