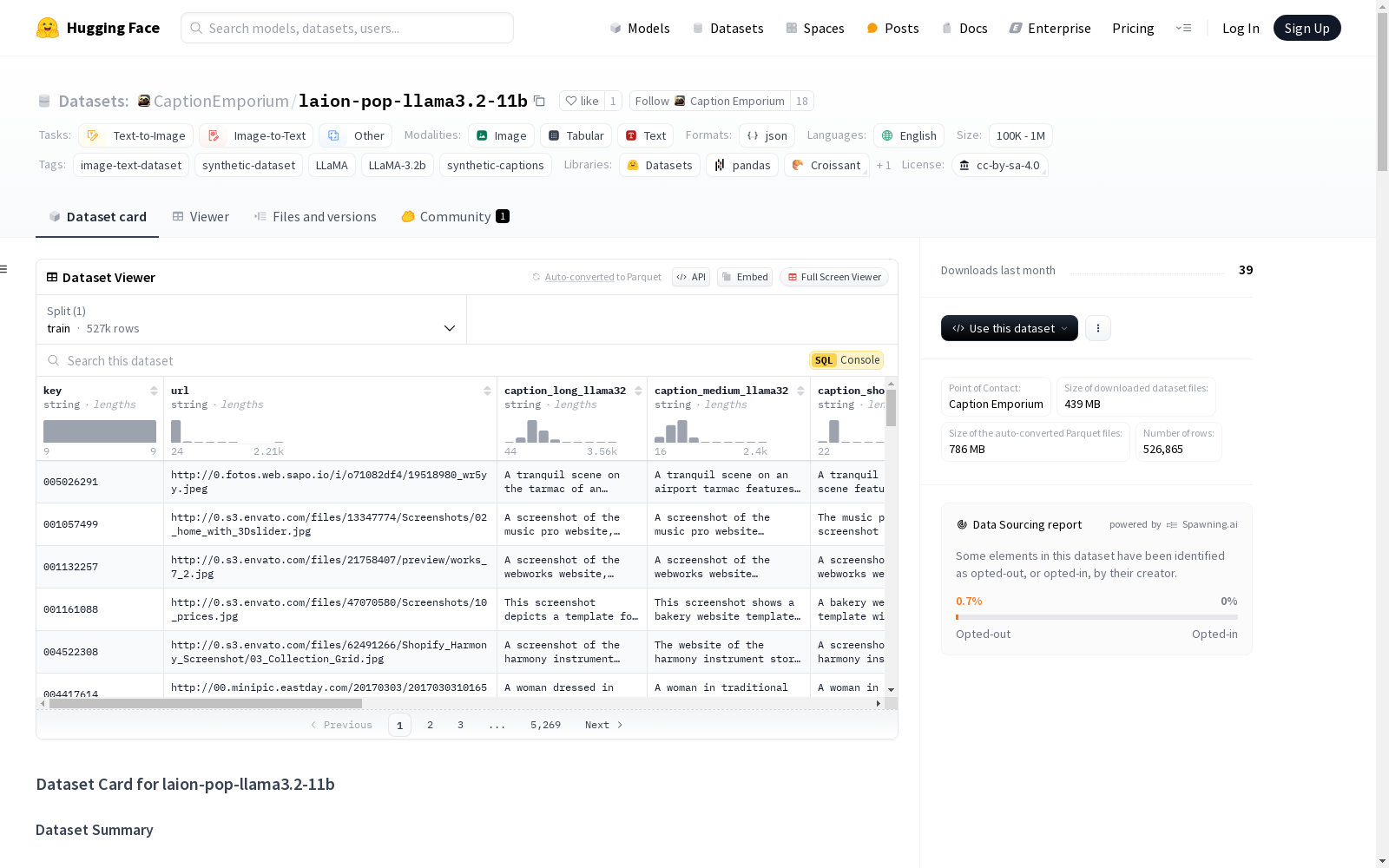
laion-pop-llama3.2-11b
收藏数据集卡片:laion-pop-llama3.2-11b
数据集描述
数据集概述
- 数据集名称: laion-pop-llama3.2-11b
- 数据类型: 图像文本数据集
- 数据来源: laion/laion-pop
- 数据规模: 1,580,595 条合成描述
- 过滤标准: 仅包含 SFW(适合工作环境)图像,过滤掉
nsfw_prediction大于或等于 0.995 的图像 - 描述生成模型:
- 描述基础: 使用原始图像的
alt_text字段进行描述生成
语言
- 主要语言: 英语
- 其他语言: 偶尔包含图像中的其他语言文本
预期用途
- 用于训练文本到图像模型和其他机器学习任务
数据分割
| 数据集名称 | 训练集大小 |
|---|---|
| laion-pop-llama3.2-11b | 526865 |
数据集创建
数据集生成
-
生成提示: py prompt_gen = lambda txt :f""" 请使用尽可能多的段落详细描述这张图片。如果你看到文本或物体,请详细描述它们以及前景和背景的任何其他方面。作为提示,这里是图像的 alt-text,可能与图像有关,也可能无关:
提示:
{txt}不要在描述中引用 alt-text。
开始描述: """
-
描述简化: py prompt_shorten = lambda img_prompt: f""" 你有两个任务:从长描述中准备一个长段落描述和一个短描述。
描述供你提炼
以下是要提炼的描述。
{img_prompt}任务
- 将其提炼成一个足够描述图像所有细节的长段落。删除任何冗余的行或描述。
- 将其提炼成一个最多 25 个单词的单句。删除任何冗余的行或描述。
请仅写两个描述,每行一个。 """
数据实例
-
示例行: py {alt_txt: Aviões Caravela e Super, Portela (A. Cunha, 1965), alt_txt_similarity: 0.5682529211044312, caption_long_llama32: A tranquil scene on the tarmac of an airport, showcasing aircraft and their surroundings.
in the foreground, on the left side, a white van with a logo and the word "manutencao" in white letters is parked, facing right. to its left, a propeller plane is positioned, with a smaller plane in front of it, featuring the words "aviôes caravela" and "super" in red text, accompanied by a row of red dots along its body. two more planes, similar in design, are visible in the distance, with a white, low-slung structure between them, possibly a fueling station. the background of the image features a hazy, flat landscape, likely a grassy field, and the horizon, with buildings visible in the distance. the sky above is a gradient of blue and yellow, suggesting either dawn or dusk. the overall atmosphere is one of serenity, with the vehicles and aircraft arranged in a harmonious and organized manner.,caption_medium_llama32: A tranquil scene on an airport tarmac features a white van with the logo "manutencao" parked next to a propeller plane, with a smaller "Aviôes Caravela Super" plane in front of it. The image also includes two more planes in the distance, a low-slung structure, and a hazy landscape with buildings and a blue-yellow sky., caption_short_llama32: A tranquil airport scene features a white van, propeller plane, and smaller "Aviôes Caravela Super" plane, set against a hazy landscape and blue-yellow sky., cogvlm_caption: an airport tarmac during what appears to be the early evening or dawn, with the sky painted in hues of pink and blue. Several airplanes are parked, with one prominently displaying the British Airways logo. In the foreground, theres a vehicle labeled WATERWAY and a few ground support equipment items scattered around. The overall atmosphere of the image is calm and serene, capturing a moment of stillness in the bustling world of aviation., exif: {"Image ExifOffset": "26", "EXIF ColorSpace": "sRGB"}, height: 873.0, key: 005026291, llava_caption: a row of four airplanes parked on a runway. The airplanes are lined up next to each other, with two of them being larger and two of them being smaller. The airplanes are positioned in a way that they are all visible in the frame, with one of the larger airplanes partially covering the smaller one. The sky in the background is cloudy, adding to the overall atmosphere of the scene. The image is a black and white photograph, which gives it a classic and timeless appearance., nsfw_prediction: 7.049842679407448e-05, url: http://0.fotos.web.sapo.io/i/o71082df4/19518980_wr5yy.jpeg, width: 1280.0}
偏见讨论
- 偏见来源: 数据集内容和 LLaMA 3.2 的训练数据
已知限制
- 描述准确性: 描述未经过手动验证,可能存在错误
- 基础描述: 使用 alt-text 可能导致基于建议性的幻觉
- 安全性: 仅使用
nsfw_prediction过滤图像,可能仍存在不安全的图像
附加信息
数据集策展人
- Caption Emporium
- laion
许可信息
引用信息
@misc{laion-pop-llama3.2-11b, author = { Caption Emporium }, title = {laion-pop-llama3.2-11b}, year = {2024}, publisher = {Huggingface}, journal = {Huggingface repository}, howpublished = {url{https://huggingface.co/datasets/CaptionEmporium/laion-pop-llama3.2-11b}}, }