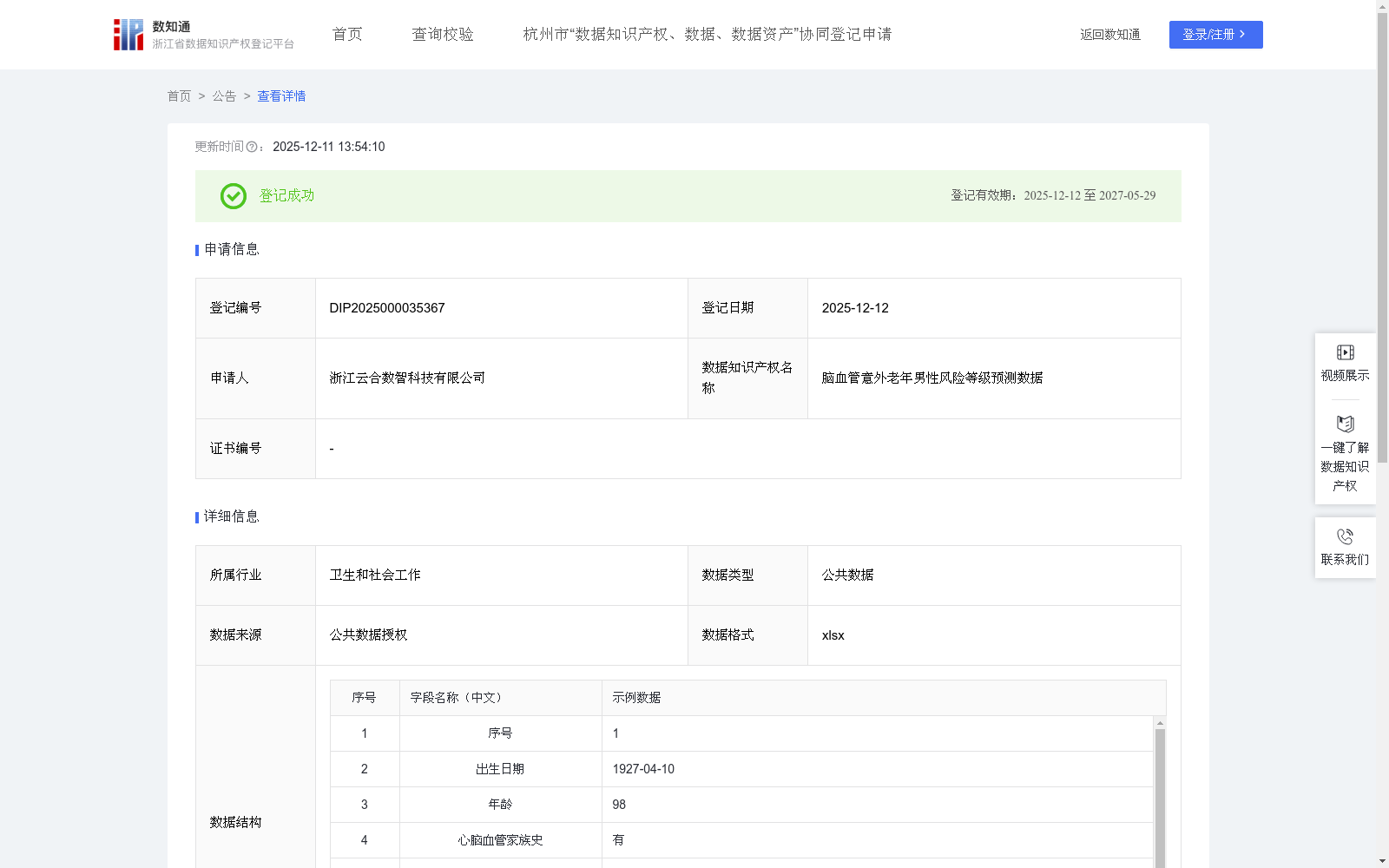
脑血管意外老年男性风险等级预测数据
收藏浙江省数据知识产权登记平台2025-12-11 更新2025-12-12 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8412737
下载链接
链接失效反馈官方服务:
资源简介:
本数据及配套算法规则在地域上,可覆盖温州全市域的老年(60岁以上)男性人群的脑血管意外风险等级;适用于人群的风险筛查,以及定期风险监测场景。
主要服务于卫健委或者其他医疗机构进行脑血管意外风险人群的早期筛查和后续的健康纳管。
解决问题:运用数据及算法规则,可准确预测个体发生脑血管意外的风险等级,提前识别高危人群,改变传统 “被动治疗” 模式,实现脑血管意外的早发现、早预防;通过动态监测风险变化,及时发现高风险人群,提前预防,降低重症风险;为公共卫生部门制定脑血管意外防治政策提供数据支持,优化医疗资源分配。整体过程如下:
1、数据采集:原始数据通过公共数据授权运营获取,主要包括患者ID,性别、出生日期、临床诊疗数据(高血压、脑血管意外、心脑血管家族史)、检查检验数据(总胆固醇、甘油三酯)、体检数据(总胆固醇、甘油三酯、抽烟、饮酒)等数据。
2、数据处理:
a)将不同类型数据按照对应患者id进行关联;
b) 根据出生日期计算年龄;
c) 对缺失值进行填充、异常值进行过滤或者替换,清洗后的数据通过标签化或归一化等进行数据标准化,获取数据特征;
d) 对患者ID进行编号处理,生成自增的序号。
3、算法加工:
算法加工过程包括模型训练和风险预测,构建的模型的功能主要是用于个体的脑血管意外的患病风险预测,使用标准化后的数据特征作为输入数据对模型进行训练和调优,主要包括心脑血管家族史,高血压,吸烟,饮酒,总胆固醇,甘油三酯等数据特征。模型的参数在其他需要说明的信息中给出。使用训练好的模型对全域人群的脑血管意外风险进行预测,并将预测的风险等级根据情况定为高危、中危、低危三个等级。
This dataset and supporting algorithm rules cover the stroke risk stratification for all elderly males (aged 60 and above) in the entire administrative region of Wenzhou. It is applicable for population risk screening and regular risk monitoring scenarios, and mainly serves the National Health Commission (NHC) or other medical institutions to conduct early screening of stroke risk populations and subsequent health management.
Problem Solved: By leveraging the dataset and algorithm rules, the risk stratification of individual stroke can be accurately predicted, and high-risk groups can be identified in advance. This changes the traditional "passive treatment" model, enabling early detection and prevention of stroke. Through dynamic monitoring of risk changes, high-risk populations can be identified timely for early intervention, reducing the risk of severe illness. It also provides data support for public health departments to formulate stroke prevention and control policies and optimize the allocation of medical resources.
The overall process is as follows:
1. Data Collection: The raw data is obtained through authorized public data operation, mainly including patient ID, gender, date of birth, clinical diagnosis and treatment data (hypertension, stroke, family history of cardiovascular and cerebrovascular diseases), laboratory test data (total cholesterol, triglycerides), physical examination data (total cholesterol, triglycerides, smoking, alcohol consumption) and other related data.
2. Data Processing:
a) Correlate different types of data according to the corresponding patient ID;
b) Calculate age based on the date of birth;
c) Fill in missing values, filter or replace outliers, and perform data standardization such as labeling or normalization on the cleaned data to obtain data features;
d) Number the patient IDs to generate auto-incrementing serial numbers.
3. Algorithm Processing:
The algorithm processing includes model training and risk prediction. The constructed model is mainly used for predicting individual stroke risk. The standardized data features are used as input data for model training and tuning, mainly including family history of cardiovascular and cerebrovascular diseases, hypertension, smoking, alcohol consumption, total cholesterol, triglycerides and other data features. The model parameters are given in other required information. The trained model is used to predict the stroke risk of the entire population, and the predicted risk level is classified into three categories: high-risk, medium-risk and low-risk according to the situation.
提供机构:
浙江云合数智科技有限公司
创建时间:
2025-11-25
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是用于预测老年男性脑血管意外风险等级的公共数据,包含500条记录,每周更新,涵盖出生日期、年龄、心脑血管家族史、高血压、抽烟、饮酒、总胆固醇、甘油三酯等字段,输出风险等级为高危、中危或低危。它主要应用于温州全市域60岁以上男性人群的风险筛查和监测,服务于医疗机构和公共卫生部门,旨在通过算法模型实现脑血管意外的早期发现和预防,优化医疗资源分配。
以上内容由遇见数据集搜集并总结生成


