qvhighlights-1fps
收藏Hugging Face2026-05-17 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/shaunmarvell/qvhighlights-1fps
下载链接
链接失效反馈官方服务:
资源简介:
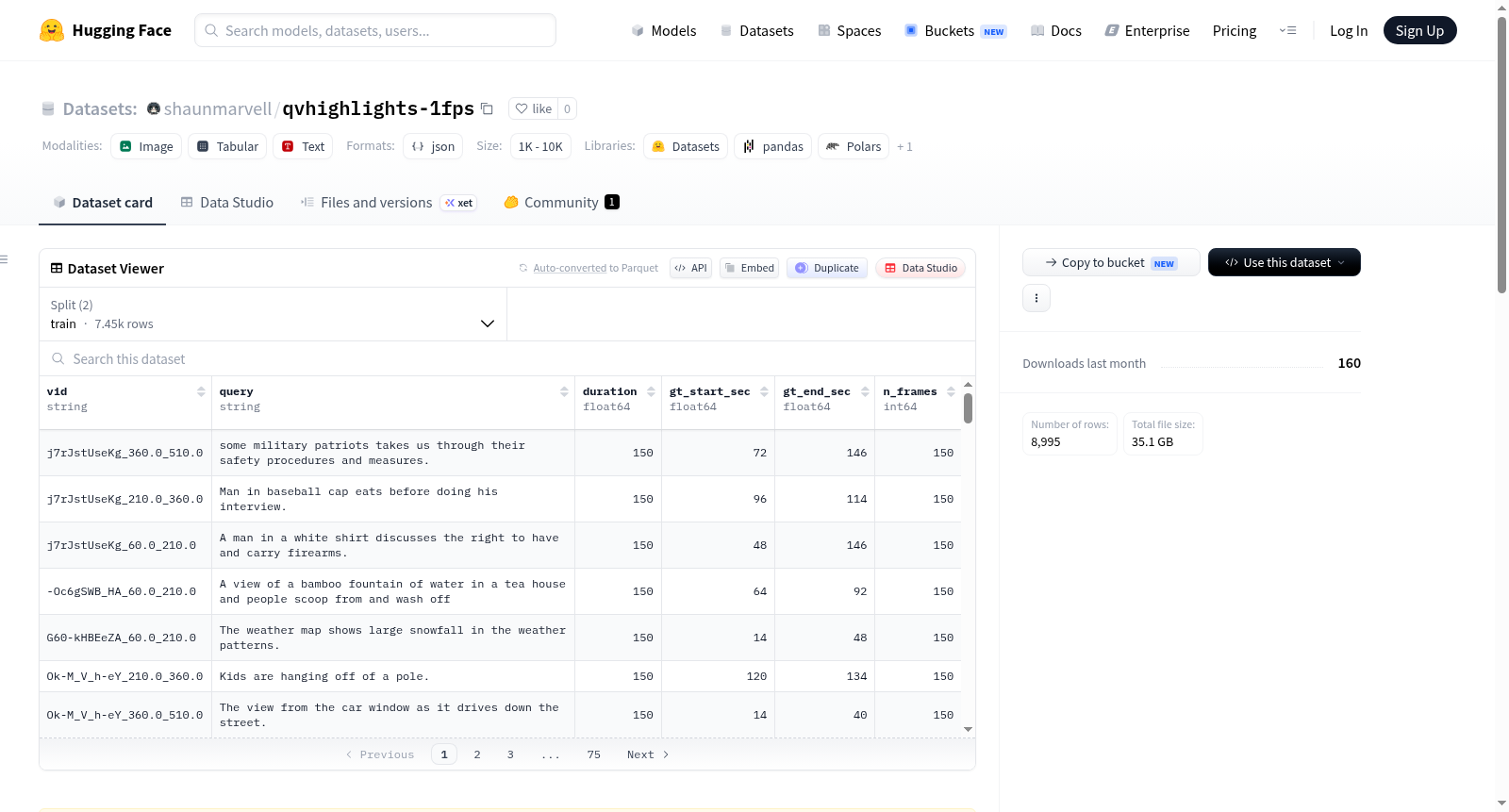
QVHighlights 1fps 是一个为时间视频定位任务设计的预处理视频数据集。该数据集对原始 QVHighlights 视频进行了预处理:视频帧以每秒 1 帧的速率提取,并统一调整为 384×384 分辨率的 JPEG 图像格式,从而在模型训练时无需实时视频解码,提升了效率。数据集包含 7,445 个训练样本和 1,550 个验证样本。每个样本的标注以 JSONL 格式存储,每条记录包含视频 ID(vid)、描述查询语句(query)、视频总时长(duration)、真实起始时间(gt_start_sec)、真实结束时间(gt_end_sec)以及总帧数(n_frames)。视频帧文件以压缩包形式分批次提供,解压后路径结构为 `frames/{vid}/{timestamp:08.3f}.jpg`。本数据集基于 jwnt4/qvhighlights-50frames 的标注和 ayushsdev/qvhighlights-videos 的原始视频构建。
QVHighlights 1fps is a preprocessed video dataset tailored for the temporal video grounding task. This dataset preprocesses the original QVHighlights videos by extracting frames at 1 frame per second (fps), and uniformly resizing all extracted frames to JPEG images with a resolution of 384×384. This removes the requirement for real-time video decoding during model training, thus enhancing training efficiency. It consists of 7,445 training samples and 1,550 validation samples. Annotations for each sample are stored in JSONL format, where each entry includes video ID (vid), natural language query, total video duration (duration), ground-truth start time (gt_start_sec), ground-truth end time (gt_end_sec), and total number of frames (n_frames). The video frame files are provided in batches as compressed packages, with the post-extraction directory structure being `frames/{vid}/{timestamp:08.3f}.jpg`. This dataset is built based on the annotations from jwnt4/qvhighlights-50frames and the raw videos from ayushsdev/qvhighlights-videos.
创建时间:
2026-05-09
搜集汇总
数据集介绍
构建方式
QVHighlights 1fps数据集是对原始QVHighlights数据集进行预处理后的版本,专为时序视频定位任务而设计。其构建过程首先从原始视频中按每秒一帧(1fps)的速率提取图像帧,随后将所有帧统一缩放至384×384像素的JPEG格式,从而在训练阶段彻底规避了实时视频I/O操作所带来的开销。数据集的标注以JSONL格式存储,每一行包含视频标识符、文本查询语句、视频总时长、目标起始与结束时间戳以及帧总数等关键信息。为便于分布式训练与数据加载,提取出的图像帧被组织成多个tar归档包,每个包涵盖约1000个训练样本,验证集则单独打包,所有tar文件解压后均遵循“frames/{vid}/{timestamp}.jpg”的目录结构。
特点
该数据集的核心特点在于其高效性与简洁性。通过统一采用1fps的帧率与固定的384×384分辨率,数据规模得到有效控制,同时保留了足以完成时序定位任务的时间分辨率。预处理后的直接图像存储方式使得训练过程无需依赖视频解码库,极大地简化了数据流水线。此外,数据集提供了完整的训练与验证划分,其中训练集包含7445条标注,验证集包含1550条标注,覆盖了多样化的视频场景与自然语言查询。数据以tar归档形式分发,兼顾了存储效率与加载灵活性,研究者可根据实际需求选择性地解压特定批次。
使用方法
使用该数据集时,研究者可首先解压所需的tar归档文件,获取以视频标识符和精确时间戳命名的JPEG图像序列。随后,通过解析JSONL标注文件,将每个文本查询与其对应的视频帧序列及时间区间关联起来。在模型训练阶段,可直接从磁盘按路径读取指定帧,构造包含视觉特征与文本嵌入的输入对。常见的使用范式包括预提取帧特征并缓存,或采用在线数据增强策略。数据集的设计兼容PyTorch等主流框架,用户可自定义DataLoader按批次加载帧序列,并结合时序定位模型(如基于Transformer的结构)进行训练与评估。
背景与挑战
背景概述
QVHighlights-1fps数据集是针对时序视频定位任务精心预处理后的版本,诞生于对视频理解领域高效训练需求的回应。该数据集由研究机构通过优化原始QVHighlights视频资源构建而成,核心研究问题聚焦于如何在不依赖实时视频输入输出的前提下,实现基于自然语言查询的精准时间片段定位。其采用1帧每秒的采样率将视频重采样为384×384的JPEG图像,极大简化了训练过程中的数据加载复杂度。自发布以来,该数据集以其标准化的预处理流程和清晰的标注格式,为视频定位模型的可复现研究提供了实质性支撑,在多媒体分析与自然语言交叉领域产生了积极影响。
当前挑战
该数据集所应对的领域问题在于时序视频定位任务中,模型需从长时间未裁剪的视频中精确识别与自然语言描述对应的起止时间点,这对视觉与语言的跨模态对齐能力提出高要求。构建过程中的挑战包括如何在大规模视频数据中实现统一、高效的帧采样以平衡存储开销与信息保留,以及设计可靠的人工标注流程以保证时间边界标注的客观一致性。此外,将原始视频降采样至1fps可能丢失高频动作语义,如何在显著降低计算代价的同时维持定位精度的竞争力,仍是后续研究需要攻克的难点。
常用场景
经典使用场景
QVHighlights-1fps数据集专为时序视频定位任务而设计,其核心作用在于将原始视频以每秒一帧的频率采样,并统一缩放至384×384像素的JPEG格式。这一预处理策略极大地简化了模型训练流程,使研究者无需在运行时处理复杂的视频输入输出操作。数据集包含7445条训练标注与1550条验证标注,每条标注均记录了视频片段标识、自然语言查询、视频总时长、目标片段的起止时间以及帧数信息。借助这一精细化的帧级结构,模型能够以更低的计算开销学习视频帧与文本查询之间的语义对齐关系,从而高效地完成长视频中关键片段的定位任务。
解决学术问题
该数据集解决了时序视频定位研究中长期存在的数据加载瓶颈与训练效率低下问题。传统方法需在训练时实时解码视频流,不仅耗费大量I/O资源,还因视频编码差异导致预处理结果不一致。QVHighlights-1fps通过提供统一的帧级缓存,消除了这类变量对模型性能的干扰,使研究者得以聚焦于定位算法的改进与创新。其标准化格式赋予了实验结果更高的可重复性,促进了不同模型之间的公平对比。此外,数据集对自然语言查询与时间边界的精确标注,为细粒度视频理解、多模态语义融合等前沿课题提供了坚实的数据基石,推动了跨模态检索与定位技术的理论进展。
衍生相关工作
围绕QVHighlights-1fps数据集,学界已衍生出多项里程碑式的研究工作。其中,基于Transformer的两阶段定位模型通过将帧特征与语言嵌入进行跨模态交互,在时序边界预测上取得了显著提升;另一类工作则探索了对比学习范式,利用正负样本对构建帧级与句子级的相似度矩阵,从而在不依赖复杂后处理的情况下实现高精度定位。这些衍生工作不仅验证了数据集在标准评估协议下的有效性,还推动了多模态基础模型的发展,促使后续研究将时序定位任务与其他视觉语言任务(如视频描述生成与问答)进行联合训练,形成了更具泛化能力的统一框架。
以上内容由遇见数据集搜集并总结生成


