paralingua_ru
收藏Hugging Face2026-05-08 更新2026-05-09 收录
下载链接:
https://huggingface.co/datasets/turnipseason/paralingua_ru
下载链接
链接失效反馈官方服务:
资源简介:
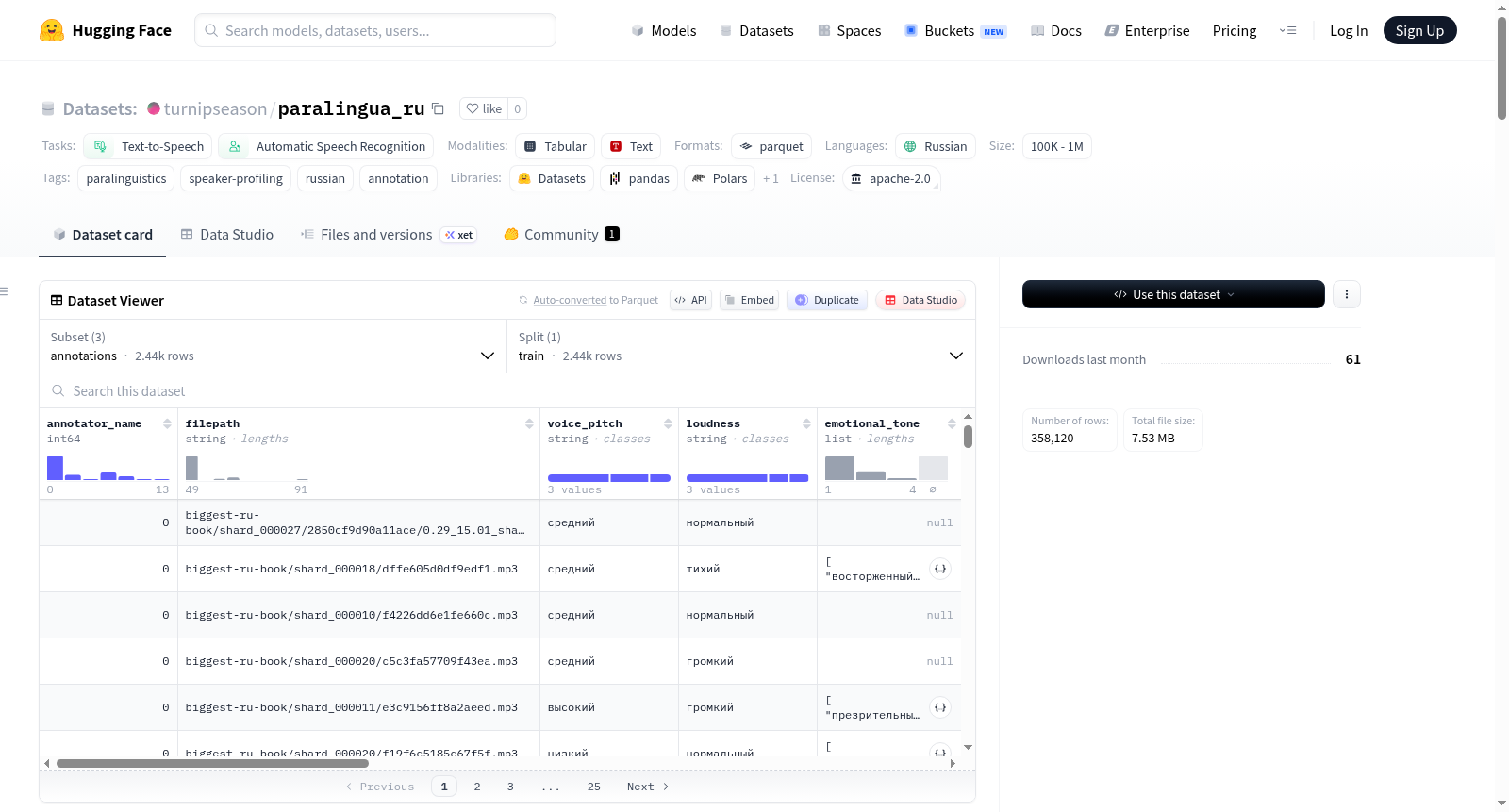
俄罗斯副语言标注数据集是一个包含三个俄语语料库(biggest_ru_book、DeepSpeech和Golos)中说话者副语言特征的手动标注数据集。数据集的主要目的是为语音合成和自动语音识别等任务提供丰富的副语言特征标注。数据内容主要包括音频片段的标注信息,涵盖性别、年龄组、音高、响度、语速、节奏、语音清晰度、说话方式、情感语调、声音特征、语调类型、参与度和标注者置信度等多个维度。每个音频片段可能包含多个标注者的评估。数据集结构包含三个主要文件:标注数据(paralingua_v1.parquet)、说话者特征档案(paralingua_speaker_profiles.parquet)和说话者ID映射(paralingua_speaker_map.parquet)。对于biggest_ru_book语料库中的说话者,数据集还提供了基于所有标注构建的说话者特征档案,包括聚合后的单标签和多标签特征,以及由Gemini UI生成并人工修正的完整声音描述。数据集规模在1K到10K之间,适用于副语言学研究、说话者分析、俄语语音处理等任务。
The Russian Paralinguistic Annotation Dataset is a manually annotated dataset containing paralinguistic features of speakers from three Russian corpora: biggest_ru_book, DeepSpeech, and Golos. The primary purpose of this dataset is to provide rich paralinguistic feature annotations for tasks such as speech synthesis and automatic speech recognition (ASR).
The dataset content mainly includes annotation metadata of audio clips, covering multiple dimensions including gender, age group, pitch, loudness, speaking rate, rhythm, speech clarity, speaking style, emotional tone, voice characteristics, intonation type, engagement, and annotator confidence. Each audio clip may contain evaluations from multiple annotators.
The dataset structure consists of three main files: annotation data (paralingua_v1.parquet), speaker feature profiles (paralingua_speaker_profiles.parquet), and speaker ID mapping (paralingua_speaker_map.parquet). For speakers in the biggest_ru_book corpus, the dataset also provides speaker feature profiles built based on all annotations, including aggregated single-label and multi-label features, as well as complete voice descriptions generated by Gemini UI and manually revised.
The dataset has a scale between 1K and 10K, and is suitable for tasks such as paralinguistic research, speaker analysis, and Russian speech processing.
创建时间:
2026-04-28
原始信息汇总
数据集概述
数据集名称:Russian Paralinguistic Annotation Dataset(俄语副语言标注数据集)
数据集链接:https://huggingface.co/datasets/turnipseason/paralingua_ru
许可协议:Apache-2.0
任务类别:文本转语音(text-to-speech)、自动语音识别(automatic-speech-recognition)
语言:俄语
数据集大小:约 1,000 到 10,000 条样本
数据集标签:副语言学、说话人画像、俄语、标注
数据来源
该数据集基于三个俄语语音语料库构建:
- biggest_ru_book:俄语有声读物
- DeepSpeech ru:播客、YouTube 视频
- Golos:众包语料库
标注内容
每个音频片段由人工标注以下特征:
| 字段 | 描述 | 示例值 |
|---|---|---|
gender |
说话人性别 | 男、女 |
age_group |
年龄组 | 青年、成年、老年 |
voice_pitch |
音高 | 低、中、高 |
loudness |
音量 | 轻声、正常、大声 |
tempo |
语速 | 慢、适中、快 |
rhythm |
节奏 | 流畅、断续 |
speech_clarity |
发音清晰度与音频质量 | 清晰、含糊、音频质量差 |
speech_manner |
说话方式 | 标签列表 |
emotional_tone |
情感色彩 | 标签列表 |
voice_characteristics |
嗓音特征 | 丝绒感、沙哑等 |
intonation |
语调类型 | 陈述、疑问等 |
engagement |
参与度 | 积极、消极 |
confidence |
标注者置信度(1-3) | 3 |
数据集结构
数据集包含三个配置(config):
-
annotations
- 文件:
paralingua_v1.parquet - 说明:每条记录为一个音频片段的标注,一个音频可能有多个不同标注者的评分。关键字段包括
annotator_name(标注者 ID)和speaker_id(说话人 ID,若未知则为-1)。
- 文件:
-
speaker_profiles
- 文件:
paralingua_speaker_profiles.parquet - 说明:为
biggest_ru_book中的说话人生成的综合性嗓音画像,聚合了该说话人所有标注信息。包含以下列:
- 文件:
| 列名 | 说明 |
|---|---|
speaker_id |
说话人 ID |
n_annotations |
该说话人的总标注数 |
gender_label / gender_conf / gender_uncertain / gender_dist / gender_n |
性别相关 |
voice_pitch_label / voice_pitch_conf / voice_pitch_uncertain / voice_pitch_dist / voice_pitch_n |
音高相关 |
age_group_label / age_group_conf / age_group_uncertain / age_group_dist / age_group_n |
年龄组相关 |
voice_char_tags / voice_char_support / voice_char_n |
嗓音特征标签及支持度 |
manner_timbral_tags / manner_timbral_support |
说话方式标签及支持度 |
speaker_description |
由 Gemini UI 生成并经人工校正的完整说话人嗓音描述 |
- speaker_map
- 文件:
paralingua_speaker_map.parquet - 说明:仅针对
biggest_ru_book语料库,提供原始文件路径与speaker_id之间的映射。列包括filepath(音频文件路径)和speaker_id(说话人 ID)。
- 文件:
聚合逻辑(说话人画像)
- 单标签特征(如性别、音高、年龄组):取多数投票的标签作为最终结果,置信度 = 多数标签票数 / 该字段非空总票数;若置信度 < 0.7,则标记为
uncertain = True。 - 多标签特征(如嗓音特征、说话方式):计算每个标签在所有标注中出现的比例(
tag_support),仅保留tag_support ≥ 0.4的标签。 - 说话人描述:基于聚合特征和一段音频,使用 Gemini UI 生成结构化描述,再结合额外 4 段随机音频进行人工校正。
其他说明
- DeepSpeech ru 和 Golos 语料库的音频缺失原始说话人 ID,因此未包含在说话人映射文件和画像文件中。
- 一个说话人可能对应多个音频片段,且一个标注者可能为同一说话人的多个片段进行标注。
搜集汇总
数据集介绍
构建方式
本数据集源自三个俄语语音语料库——biggest_ru_book、DeepSpeech与Golos,通过人工标注的方式对每一段音频的副语言特征进行精细刻画。标注维度涵盖性别、年龄组、音高、响度、语速、节奏、发音清晰度、言语风格、情感色彩、嗓音特质、语调类型、投入度及标注者自信度。每个音频片段可能由多位标注者独立评价,最终形成多重标注数据。标注者与说话者的身份通过唯一ID进行关联,其中biggest_ru_book语料库的说话者ID进一步借助文件路径及CAM++模型聚类映射至原始数据集。
特点
数据集以三重结构组织:核心标注文件记录每个音频片段的细粒度副语言属性;说话者映射文件提供biggest_ru_book中音频路径与说话者ID的对应关系;说话者画像文件则对同一说话者的所有标注进行聚合,生成其不变的语音特征轮廓。聚合逻辑巧妙区分了单标签与多标签属性:对于性别、音高等单标签特征,采用多数投票并计算置信度;对于嗓音特质与言语风格等多标签特征,仅保留支持度不低于40%的标签。此外,数据集还包含由Gemini UI生成并经人工修正的说话者综合描述。
使用方法
用户可通过HuggingFace加载该数据集的三个配置:annotations、speaker_profiles与speaker_map。annotations配置提供原始标注数据,适用于训练副语言属性分类或回归模型。speaker_profiles配置可直接用于说话者画像分析或作为语音合成系统的说话者条件输入。speaker_map配置则便于将biggest_ru_book语料库中的音频文件与其说话者ID进行关联,从而支持跨语料库的说话者身份统一管理。数据格式为Parquet,便于高效读写与集成到现代数据处理流水线中。
背景与挑战
背景概述
Russian Paralinguistic Annotation Dataset(paralingua_ru)是由俄罗斯研究团队构建的一个面向俄语语料库的副语言特征标注数据集,创建于近年,旨在系统性地刻画语音信号中除语义内容之外的声学与表达属性。该数据集源自三大俄语公开语音资源——biggest_ru_book、DeepSpeech与Golos,聚焦于说话人副语言特征的细粒度标注,涵盖性别、年龄、音高、响度、语速、韵律、清晰度、情感基调、参与度及标注者自信度等多维标签,并进一步为biggest_ru_book中的说话人生成了包含聚合特征与自然语言描述的说话人画像。该数据集填补了俄语副语言研究领域高质量、多维度标注资源的空白,为文本转语音(TTS)、自动语音识别(ASR)中的说话人建模、情感语音合成及说话人个性分析等任务提供了基准数据,对推动低资源语言副语言信息处理具有重要示范意义。
当前挑战
该数据集所应对的核心领域挑战在于副语言特征的识别与建模:语音中既有传递语义的言语信息,也有指示身份、情绪、态度与语境衍生的非语义线索,两者耦合紧密且高度依赖文化背景。构建过程面临多重实际困难:首先,标注标准需兼顾主观性与一致性,如情感色调和声线特征的标签设计难以避免歧义;其次,多源语料库的异构性增加了整合难度,DeepSpeech与Golos中说话人标识缺失迫使研究者在biggest_ru_book中通过文件路径匹配及CAM++模型聚类来补全映射;最后,标注成本高昂,单一音频片段需多人交叉验证以确保信度,而说话人画像的生成需聚合碎片化标注结果,并辅以AI生成与人工校正,流程繁复且难以规模化推广。
常用场景
经典使用场景
Russian Paralinguistic Annotation Dataset(简称paralingua_ru)是一个专为俄语副语言特征研究而构建的高质量标注数据集,其核心应用场景聚焦于说话人特征的多维度建模。该数据集整合了biggest_ru_book、DeepSpeech和Golos三大俄语语音语料库,通过人工标注的方式,为每段音频赋予性别、年龄组、音高、响度、语速、节奏、吐字清晰度、说话方式、情感色彩、嗓音特质、语调类型、参与度及标注者信心等十余类标签,为研究者提供了丰富的副语言信息基础。经典使用方式包括基于标注数据训练说话人画像预测模型,或将其作为多任务学习的基准,探索语音特征与副语言属性间的深层关联。
实际应用
在实际应用层面,paralingua_ru数据集具有广泛的落地价值。基于其丰富的副语言标签,可以开发面向俄语用户的智能语音助手和虚拟人物系统,使其具备感知用户情绪、年龄及说话风格的能力,从而实现更具人性化的交互体验。此外,该数据集还可用于构建语音伪造检测系统——通过分析音高、响度、节奏等副语言特征的一致性,识别合成语音或深度伪造音频。在俄语有声内容创作领域,如有声书录制和播客制作,该数据集辅助的说话人画像工具能够帮助制作方精准匹配声优与角色或内容风格,提升作品的表现力与感染力。
衍生相关工作
围绕paralingua_ru数据集,已衍生出多项具有影响力的研究工作。其中,基于该数据构建的说话人画像聚合方法——通过多数投票与置信度阈值机制提取单一标签、以及基于支持度筛选多标签特征——为副语言标注数据的后处理提供了范式参考。此外,研究者利用数据集中的说话人映射信息,结合CAM++聚类技术实现了音频与说话人身份的精准关联,为无ID信息的语音语料库的身份重识别任务开辟了新路径。更进一步,由数据集引导的LLM生成式说话人描述方法,通过Gemini UI生成并结合人工校正,生成了结构化、富有细节的说话人档案,为跨模态语音研究提供了创新思路。
以上内容由遇见数据集搜集并总结生成


