alisawuffles/WANLI
收藏Hugging Face2022-11-21 更新2024-03-04 收录
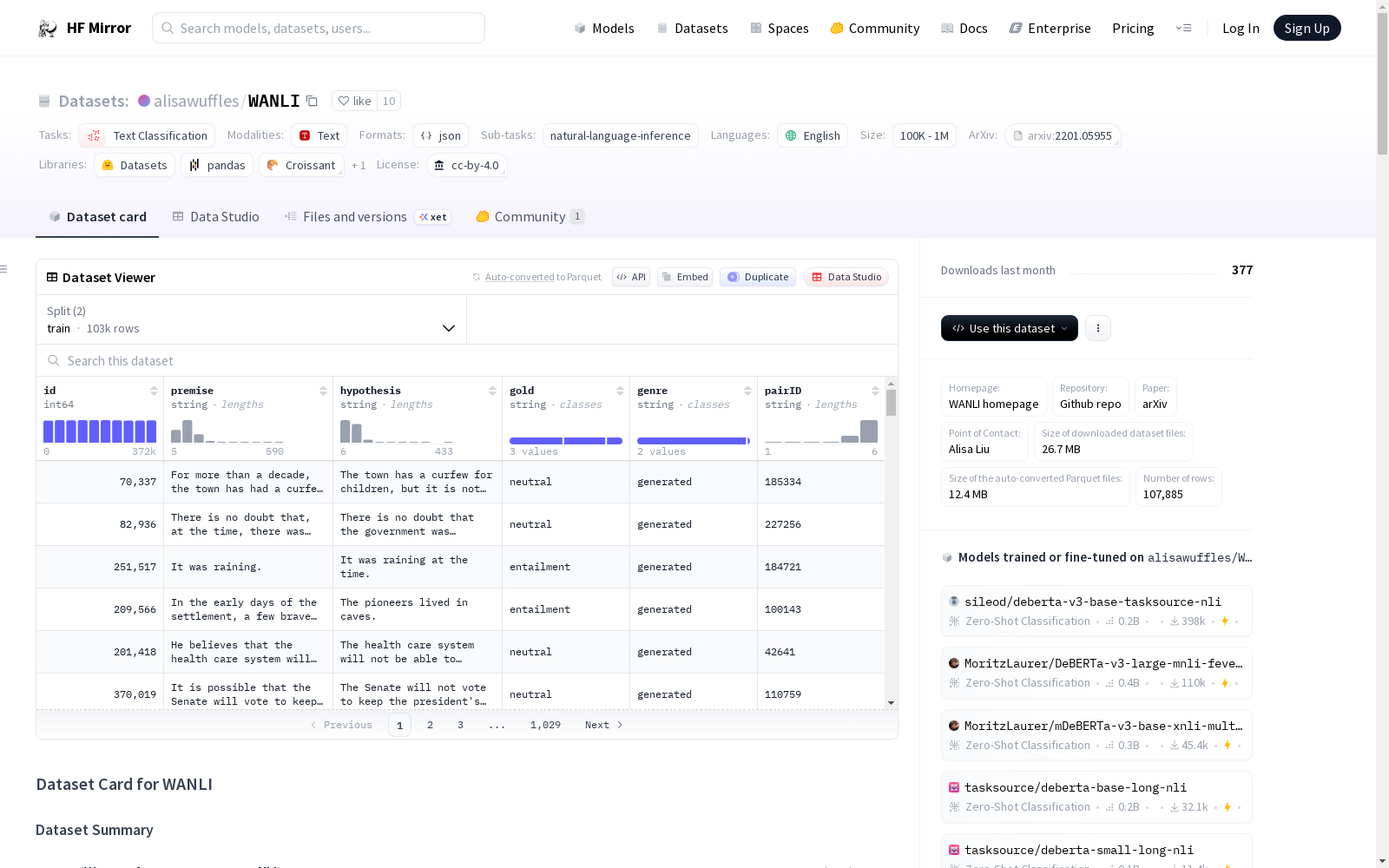
下载链接:
https://hf-mirror.com/datasets/alisawuffles/WANLI
下载链接
链接失效反馈资源简介:
WANLI(Worker-AI Collaboration for NLI)是一个包含108K个英文句子对的数据集,专门用于自然语言推理(NLI)任务。每个例子首先通过识别MultiNLI中具有挑战性推理模式的例子,然后使用GPT-3生成具有相同模式的新例子。生成的例子经过自动过滤,并由人类标注者进行标注和修订。与现有的NLI数据集相比,WANLI在多个域外测试集上表现出更强的泛化能力。数据集由GPT-3生成,并由位于美国的英语母语者进行修订和标注。
提供机构:
alisawuffles
原始信息汇总
数据集概述
数据集名称
- 名称: WANLI
- 全称: Worker-AI Collaboration for NLI
数据集基本信息
- 语言: 英语
- 许可证: CC-BY-4.0
- 多语言性: 单语
- 大小: 100K<n<1M
- 来源: 原创数据集
- 任务类别: 文本分类
- 任务ID: 自然语言推理
数据集内容
- 描述: WANLI是一个包含108K英语句子对的集合,用于自然语言推理任务。每个例子首先在MultiNLI中识别出一个“口袋”的例子,这些例子共享一个具有挑战性的推理模式,然后指示GPT-3根据相同的模式编写新的例子。
- 支持任务: 自然语言推理,确定一个前提是否蕴含(即暗示假设的真实性),两者均以自然语言表达。
- 数据实例结构:
- id: 唯一标识符
- premise: 文本片段
- hypothesis: 可能是真、假或其真值条件可能不可知的文本片段
- gold: 包含
entailment,neutral,contradiction之一 - genre: 包含
generated和generated_revised - pairID: 种子MNLI例子的ID
数据集创建
- 数据收集: 从MultiNLI数据集中自动识别具有挑战性推理模式的例子,使用GPT-3生成新例子,并通过人工标注者进行验证和修订。
- 标注过程: 标注者被要求对未标注的例子进行质量修订(同时尽可能保留原始意图),并分配标签。如果例子需要大量修订或可能被视为冒犯性,则要求丢弃。
- 标注者: 要求具有98%的HIT批准率,总共10,000个批准的HIT,并位于美国。最终有62名工人参与了数据集的创建。
使用考虑
- 社会影响: 该数据集旨在探索工人-AI协作在数据集策展中的潜力,训练更强大的NLI模型,并提供对现有系统的更具挑战性的评估。
- 偏见讨论: 大型预训练语言模型生成的文本可能延续社会危害和包含有毒语言。为此,要求标注者丢弃任何可能被视为冒犯性的例子。
搜集汇总
数据集介绍
构建方式
在自然语言推理领域,数据集的构建往往面临模式单一与多样性不足的挑战。WANLI数据集采用了一种创新的工人-人工智能协作范式进行构建。其流程始于对MultiNLI数据集的深入分析,通过数据集制图技术自动识别出蕴含复杂推理模式的示例簇。随后,以这些示例簇作为上下文,引导GPT-3语言模型生成具有相同模式的新句子对。生成的候选数据经过自动筛选,保留最有益于模型训练的部分,最终交由众包工作者进行质量审核、必要修订及黄金标签标注,从而实现了大规模高效生成与人工精准校验的有机结合。
特点
WANLI数据集展现出若干显著特征,使其在自然语言推理任务中独树一帜。该数据集规模达十万余条,全部为英文语料,其核心优势在于通过生成模型引入了前所未有的语言多样性与复杂的推理模式。实证研究表明,相较于规模为其四倍的MultiNLI数据集,使用WANLI进行模型训练能在多个域外测试集上取得更优的性能,例如在HANS和对抗性NLI测试集上分别提升11%和9%的准确率。此外,数据集不仅提供最终标注结果,还完整保留了原始生成内容、人工修订记录及工作者匿名标识,为深入研究模型行为与标注过程提供了丰富的元数据支持。
使用方法
该数据集主要用于自然语言推理任务的模型训练与评估。研究者可通过加载标准化的JSON Lines格式文件便捷获取训练集与测试集,每个数据实例包含前提、假设、蕴含关系标签及来源类型等关键字段。在模型开发流程中,可直接将WANLI作为监督学习的数据源,用以训练判别文本间逻辑关系的分类模型。鉴于其增强的泛化能力,所得模型常作为强基线或用于提升下游任务的性能。同时,其附带的详细标注日志为分析标注者间一致性、研究修订模式或探测数据偏差提供了宝贵资源,支持更细粒度的学术探究。
背景与挑战
背景概述
自然语言推理作为自然语言处理领域的核心任务之一,旨在探究前提与假设之间的逻辑关系,其发展长期受限于数据集的规模与多样性。2022年,华盛顿大学与艾伦人工智能研究所的研究团队联合发布了WANLI数据集,该数据集通过创新的人机协作模式,利用GPT-3模型生成并经由众包标注者修订,构建了包含10.8万条英文句对的高质量语料。WANLI的诞生不仅为模型训练提供了更具挑战性的推理模式,更在跨领域泛化能力上展现出显著优势,例如在HANS和对抗性NLI测试集上分别提升11%与9%的性能,从而推动了自然语言推理研究向更稳健、更泛化的方向发展。
当前挑战
WANLI数据集致力于应对自然语言推理任务中模型泛化能力不足的核心挑战,传统数据集如MultiNLI虽规模庞大,但存在模式重复与语言多样性有限的问题,导致模型易于过拟合表面特征而非学习深层推理逻辑。在构建过程中,研究团队面临双重困难:一是如何精准识别MultiNLI中蕴含复杂推理模式的样本子集,并引导GPT-3生成具有相同模式却语言多样的新样本;二是确保生成文本的质量与安全性,需通过人工审核剔除可能包含冒犯性内容或隐性社会偏见的例子,同时维持标注者间较高的一致性,这一过程对算法设计与人工协作流程提出了精细化的要求。
常用场景
经典使用场景
在自然语言推理领域,WANLI数据集以其独特的生成机制成为模型训练与评估的经典资源。该数据集通过识别MultiNLI中具有挑战性的推理模式,并利用GPT-3生成新颖的句子对,再经人工标注与修订,构建了富含多样推理结构的语料库。研究者通常将其用于训练和微调预训练语言模型,以提升模型在复杂逻辑关系识别上的泛化能力,尤其在处理隐含语义和对抗性样本时展现出显著优势。
解决学术问题
WANLI数据集有效应对了传统NLI数据集中存在的模式重复与语言多样性不足的学术难题。通过结合大规模语言模型的生成能力与人类标注者的修订智慧,该数据集提供了更丰富的推理场景,帮助模型克服对表面线索的依赖,从而深入理解语言的内在逻辑。其设计显著提升了模型在跨领域测试集上的鲁棒性,例如在HANS和Adversarial NLI等基准上实现了性能突破,推动了自然语言理解中泛化与抗干扰研究的发展。
衍生相关工作
WANLI数据集的创新方法论催生了一系列围绕人机协作数据构建的经典研究。其基于数据集制图与上下文示例生成的框架,启发了后续工作如数据增强策略的优化与低资源场景下的语料合成。同时,该数据集在评估模型鲁棒性方面的贡献,促进了对抗性NLI测试基准的完善,以及针对模型偏差检测与缓解技术的研究。这些衍生工作共同推动了自然语言处理领域向更高效、更稳健的数据驱动范式演进。
以上内容由遇见数据集搜集并总结生成


