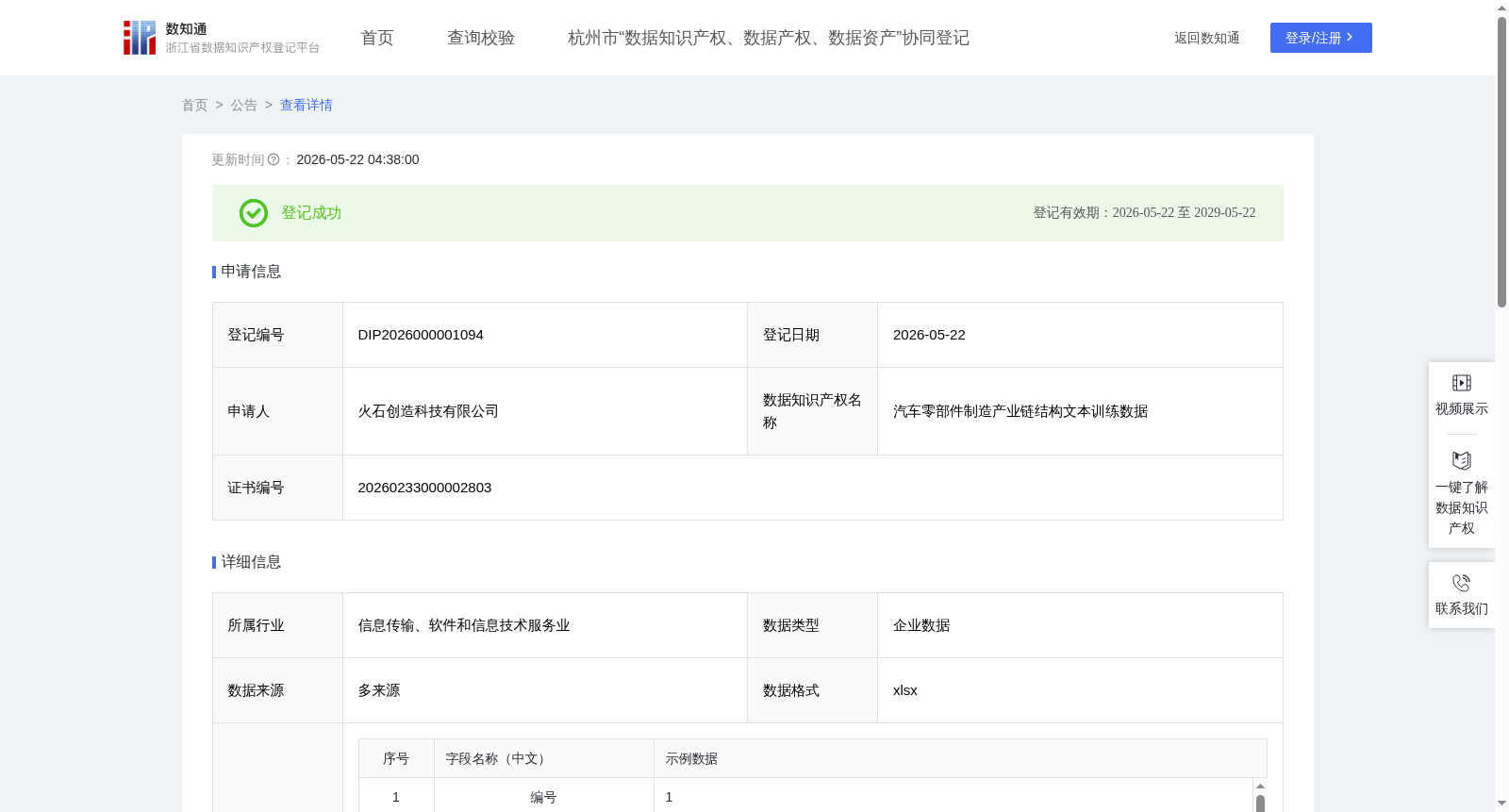
汽车零部件制造产业链结构文本训练数据
收藏浙江省数据知识产权登记平台2026-05-22 更新2026-05-24 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8447684
下载链接
链接失效反馈官方服务:
资源简介:
本数据集服务于汽车零部件产业链智能分类与产业图谱构建模型的训练与开发,通过关联企业文本与产品系统标签,为汽车产业分析提供核心数据工具。其主要应用于:
供应链寻源与采购优化:赋能整车厂或一级供应商,精准识别与匹配动力系统、底盘系统、电子电气等不同领域的零部件制造商,优化供应链布局与采购决策。产业集聚与技术布局分析:辅助政府及产业研究机构,分析区域在发动机配套、底盘系统、汽车电子等细分领域的产业完整度、技术研发能力与竞争格局,为产业规划提供依据。技术趋势与投资研判:支持投资机构与行业分析师,跟踪线控底盘、汽车芯片、智能感知系统等前沿技术领域的研发动态、企业分布与市场集中度。一、加工前数据说明
本数据集旨在构建用于汽车零部件产业链智能分析的人工智能模型训练语料。在加工前,数据已进行严格的匿名化与去标识化处理。原始企业名称被统一替换为不可逆的规范标识符,并彻底移除所有的个人及商业敏感信息,确保数据完全符合隐私保护与安全合规要求,为模型训练提供了洁净、可靠的输入基础。
二、数据处理规则
数据处理严格遵循 “体系先行、业务匹配、特征抽取” 的核心规则,形成了一套从分类框架构建到最终标签生成的完整流程:1.首先,依据汽车产业专业分类标准,预先定义了从“汽车零部件制造”(一级节点)出发,按整车系统划分为“动力系统”、“汽车底盘”、“电子电气”、“基础零部件”、“三电系统”(二级节点),并进一步细分为“点火起动系统”、“制动系统”、“传动系统”、“智能驾驶”、“电子元器件”等具体子系统(三级节点)及其对应的核心零部件(四级节点)的树状分类体系,为数据加工提供了专业、清晰的框架。2.业务匹配:采用“自动化规则匹配与人工校验相结合”的策略。首先,依托Spark大数据处理框架,对海量企业简介文本进行分布式清洗、分词与关键词匹配,通过预构建的汽车零部件产业语义规则库(涵盖“发电机、起动机、制动钳、变速器、传感器、汽车芯片、注塑件、冲压件”等数千个专业术语)自动计算并推荐初步分类节点。随后,由具备汽车工程或零部件产业知识的标注专家进行审核与最终判定,确保企业归入最贴切的系统与零部件节点。3.特征抽取:在完成业务匹配的同时,从同一段企业简介文本中,系统性地抽取代表其核心产品与技术的关键术语与名词性短语,经过去重与标准化格式化,组合成“正向词”特征串,作为对分类标签的语义补充。
三、加工后数据内容
加工后的数据集为一条条结构化的“文本-标签”数据。每条数据均包含经过脱敏处理的原始企业描述文本,以及与之对应、经人工校验的完整分类标签(一至四级节点)、高度细化的业务特征词(正向词)与产业标签。数据内容全面覆盖了传统燃油车及新能源、智能网联汽车的各类关键零部件制造企业,形成了一个分类体系专业、产品特征鲜明、可直接用于汽车零部件产业链分析、供应商智能分类、技术布局研究等模型训练与评估的高质量专用数据集。
This dataset is developed for the training and deployment of intelligent classification and industrial knowledge graph construction models for the automobile parts industry chain. By associating enterprise texts with product system tags, it provides a core data tool for automotive industry analysis. Its core applications are as follows:
1. Supply Chain Sourcing and Procurement Optimization: Empower original equipment manufacturers (OEMs) or first-tier suppliers to accurately identify and match component manufacturers in fields such as power systems, chassis systems, and electrical and electronic systems, so as to optimize supply chain layout and procurement decisions.
2. Industrial Agglomeration and Technology Layout Analysis: Assist governments and industrial research institutions in analyzing the industrial completeness, technological R&D capabilities and competitive landscape of regions in subdivided fields such as engine supporting, chassis systems and automotive electronics, so as to provide a basis for industrial planning.
3. Technology Trend and Investment Judgment: Support investment institutions and industry analysts to track R&D trends, enterprise distribution and market concentration in cutting-edge technology fields such as x-by-wire chassis, automotive chips and intelligent perception systems.
### 1. Pre-processing Data Description
This dataset aims to build training corpora for AI models used in intelligent analysis of the automobile parts industry chain. Before processing, the data has undergone strict anonymization and de-identification processing. Original enterprise names are uniformly replaced with irreversible standardized identifiers, and all personal and commercial sensitive information is completely removed, ensuring that the data fully complies with privacy protection and security compliance requirements, providing a clean and reliable input foundation for model training.
### 2. Data Processing Rules
The data processing strictly follows the core rules of "system first, business matching, feature extraction", forming a complete process from classification framework construction to final tag generation:
1. Framework Construction: Based on professional classification standards of the automotive industry, a tree-shaped classification system is pre-defined, starting from "Automobile Parts Manufacturing" (first-level node), divided into second-level nodes such as "Power System", "Automobile Chassis", "Electrical and Electronic Systems", "Basic Parts" and "Three-electric System" according to vehicle systems, and further subdivided into specific subsystems (third-level nodes) such as "Ignition and Starting System", "Brake System", "Transmission System", "Intelligent Driving", "Electronic Components" and their corresponding core components (fourth-level nodes), providing a professional and clear framework for data processing.
2. Business Matching: Adopt a strategy combining "automated rule matching and manual verification". First, relying on the Spark big data processing framework, distributed cleaning, word segmentation and keyword matching are performed on massive enterprise profile texts. A pre-built semantic rule base for the automobile parts industry (covering thousands of professional terms such as "generator, starter, brake caliper, transmission, sensor, automotive chip, injection molded part, stamping part") is used to automatically calculate and recommend preliminary classification nodes. Subsequently, annotation experts with knowledge of automotive engineering or the parts industry conduct reviews and final judgments to ensure that enterprises are classified into the most appropriate system and component nodes.
3. Feature Extraction: While completing business matching, key terms and noun phrases representing their core products and technologies are systematically extracted from the same enterprise profile text. After deduplication and standardized formatting, they are combined into "positive word" feature strings, which serve as semantic supplements to the classification tags.
### 3. Post-processing Data Content
The post-processed dataset consists of structured "text-tag" data entries. Each entry includes the desensitized original enterprise description text, as well as the corresponding manually verified complete classification tags (first to fourth-level nodes), highly refined business feature words (positive words) and industry tags. The data comprehensively covers all types of key component manufacturing enterprises in traditional fuel vehicles, new energy vehicles and intelligent connected vehicles, forming a high-quality dedicated dataset with professional classification system and distinct product features, which can be directly used for model training and evaluation such as automobile parts industry chain analysis, supplier intelligent classification and technology layout research.
提供机构:
火石创造科技有限公司
创建时间:
2026-02-28
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是面向汽车零部件制造产业链的文本训练数据,包含1000条经匿名化和人工校验的结构化记录,每条数据涵盖企业简介、四级分类节点(如制动系统、制动钳)、业务特征词(正向词)及产业标签。数据按产业链专业分类体系构建,支持供应链寻源、产业集聚分析及技术趋势研判等应用场景,为汽车零部件产业链智能分类与产业图谱构建模型提供高质量训练语料。
以上内容由遇见数据集搜集并总结生成


