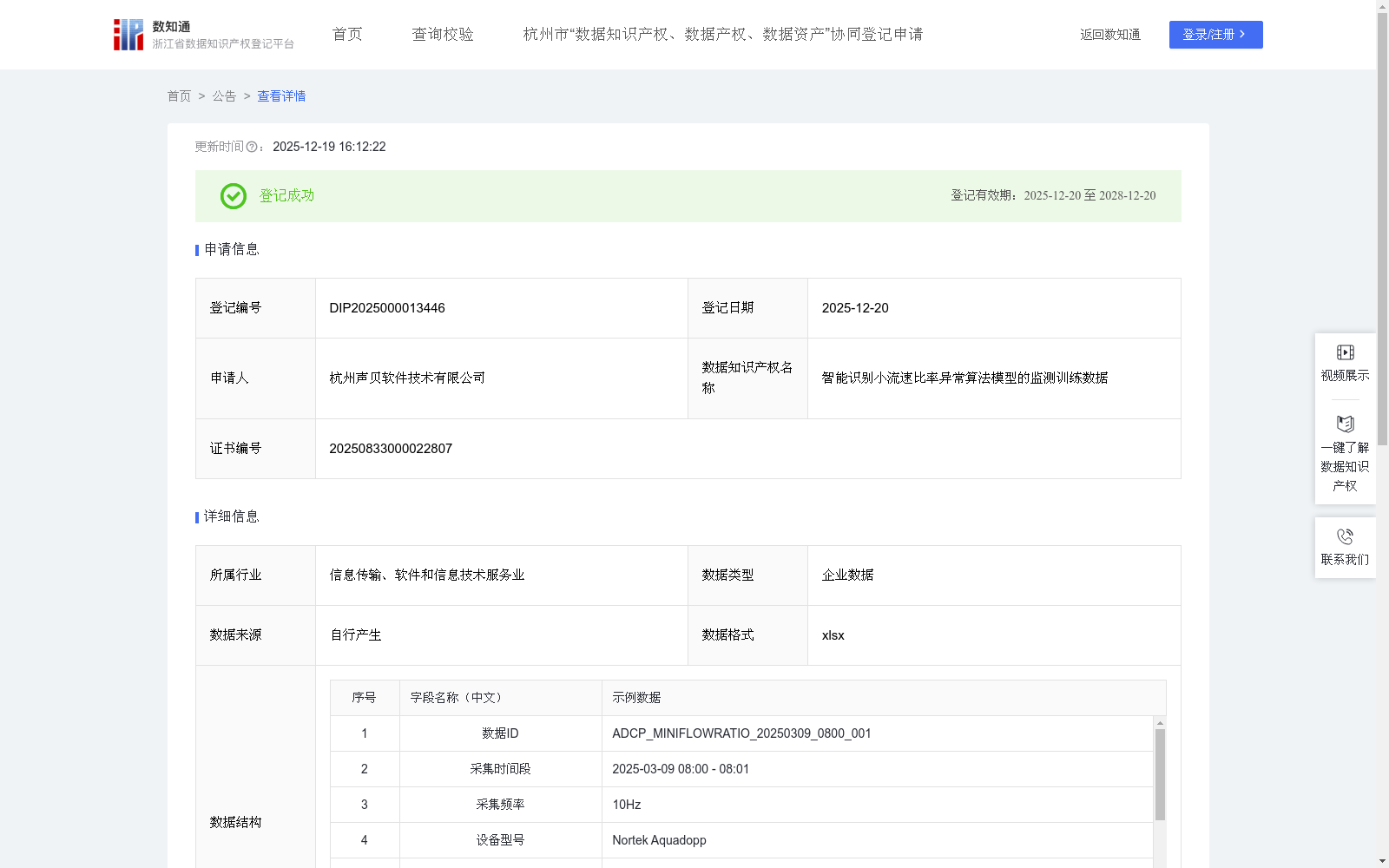
智能识别小流速比率异常算法模型的监测训练数据
收藏浙江省数据知识产权登记平台2025-12-19 更新2025-12-27 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8416745
下载链接
链接失效反馈官方服务:
资源简介:
本数据集主要用于提升AI模型对ADCP设备小流速数据比率异常的识别能力与精确性。通过对该数据集的训练,使AI模型能够精准识别小流速数据异常现象,并可应用于水文监测设备维护、数据质量控制和低流速测量验证等场景。同时,本数据集可为智慧水利系统、生态流量监测平台等建设项目提供决策依据。
1. 数据采集
通过企业自有ADCP设备自行采集监测数据,同步记录数据ID、采集时间段、采集频率、设备型号、地理坐标、总数据条数、小流速数据条数、信号强度、信噪比等数据。
2. 数据预处理与加工
通过数据清洗剔除无效数据,按7:2:1比例划分训练集/验证集/测试集。计算小流速比率(小流速条数/总条数×100%)。
设置多级标注体系:
一级标签:数据正常/小流速异常(小流速比率≥20%)
二级标签:传感器漂移型(小流速比率≥50%且信号强度>60dB)/生物附着型(20%≤小流速比率<50%且信噪比>15dB)/系统噪声型(小流速比率≥20%且信噪比<10dB)
3. 模型选择与初始化
采用小波变换+随机森林模型,初始化参数并优化超参数:学习率0.001-0.0001动态调整,批量大小8-32动态调整,时间步长12-36步动态调整;集成流体动力学约束模块。
4. 模型训练
基于Scikit-learn实施训练,采用特征重要性筛选提升效率。设置训练轮次,数据增强模拟噪声干扰等各类异常场景。设置早停机制(patience=5)。
5. 模型评估
在训练模型的过程中,使用验证集调整超参数,训练完成后在测试集上评估模型表现,评估指标包含:
基础性能指标:准确率、误报率
场景鲁棒性测试:噪声干扰检出率
并设置渐进式测试:单点异常→连续异常
This dataset is primarily developed to improve the capability and accuracy of AI models in recognizing abnormal low-flow velocity data ratios from ADCP equipment. Training on this dataset enables AI models to accurately identify abnormal low-flow velocity phenomena, and can be applied in scenarios such as hydrological monitoring equipment maintenance, data quality control, and low-flow velocity measurement verification. Additionally, this dataset can provide decision-making support for construction projects including smart water conservancy systems and ecological flow monitoring platforms.
1. Data Collection
Self-collected monitoring data using enterprise-owned ADCP equipment, with synchronous recording of data ID, collection time period, collection frequency, equipment model, geographic coordinates, total number of data entries, number of low-flow velocity data entries, signal strength, signal-to-noise ratio (SNR), and other related data.
2. Data Preprocessing and Processing
Invalid data is eliminated through data cleaning, and the dataset is divided into training, validation and test sets at a ratio of 7:2:1. The low-flow velocity ratio is calculated as (number of low-flow velocity data entries / total number of data entries) × 100%.
A multi-level annotation system is established:
Primary label: Normal data / Low-flow velocity abnormality (low-flow velocity ratio ≥ 20%)
Secondary label: Sensor drift type (low-flow velocity ratio ≥ 50% and signal strength > 60 dB) / Biofouling type (20% ≤ low-flow velocity ratio < 50% and SNR > 15 dB) / System noise type (low-flow velocity ratio ≥ 20% and SNR < 10 dB)
3. Model Selection and Initialization
A wavelet transform + random forest model is adopted, with parameter initialization and hyperparameter optimization: dynamically adjusting the learning rate within 0.001-0.0001, dynamically adjusting the batch size within 8-32, and dynamically adjusting the time step within 12-36 steps; a hydrodynamic constraint module is integrated.
4. Model Training
Training is implemented based on Scikit-learn, with feature importance screening used to improve efficiency. Training epochs are set, and data augmentation is performed to simulate various abnormal scenarios such as noise interference. An early stopping mechanism is configured (patience=5).
5. Model Evaluation
During the model training process, the validation set is used to adjust hyperparameters. After training is completed, the model performance is evaluated on the test set. The evaluation metrics include:
Basic performance metrics: Accuracy, false alarm rate
Scenario robustness test: Noise interference detection rate
Progressive testing is also set up: Single-point abnormality → Continuous abnormality
提供机构:
杭州声贝软件技术有限公司
创建时间:
2025-08-03
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是用于训练智能识别小流速比率异常算法模型的监测训练数据,包含581条每日更新的结构化数据,覆盖ADCP设备采集的小流速信息、多级异常标签及模型超参数。其核心目标是提升AI模型在水文监测场景中对小流速异常现象的识别精度与鲁棒性,支持设备维护、数据质量控制等应用,并已通过区块链存证确保数据可信。
以上内容由遇见数据集搜集并总结生成


