PubMedAbstractsSubset
收藏Hugging Face2025-06-11 更新2025-06-12 收录
下载链接:
https://huggingface.co/datasets/slinusc/PubMedAbstractsSubset
下载链接
链接失效反馈官方服务:
资源简介:
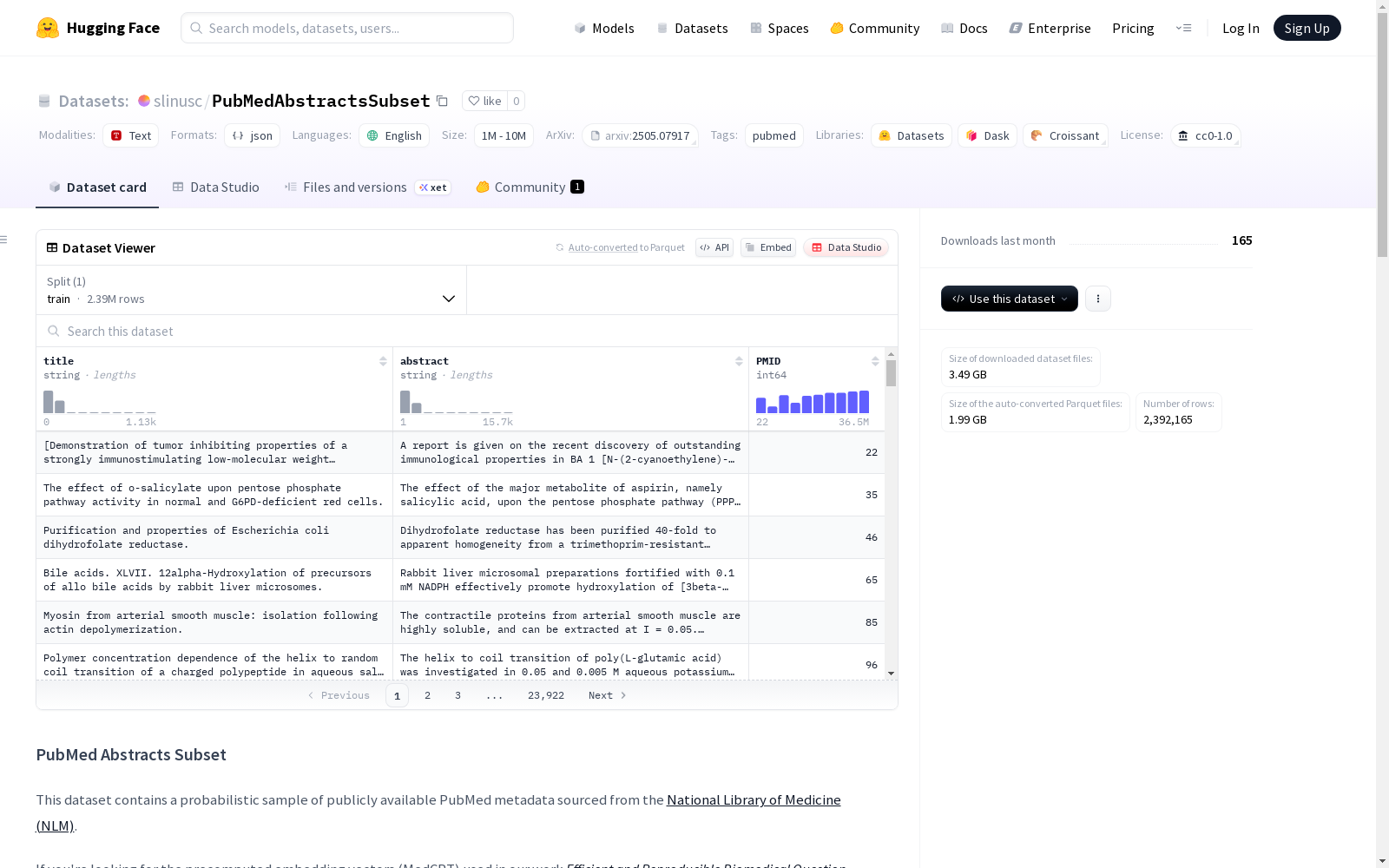
PubMed摘要子集数据集包含从PubMed的公开元数据中概率抽样得到的摘要信息。每个条目包括一个本地唯一标识符、出版物标题、摘要文本和PubMed标识符。数据集分为24个文件,总共包含约239万个样本,格式为.jsonl。
The PubMed Abstract Subset Dataset comprises abstracts probabilistically sampled from PubMed's public metadata. Each entry includes a locally unique identifier, publication title, abstract text, and PubMed identifier. The dataset is split into 24 files, containing approximately 2.39 million samples in total, formatted as .jsonl.
创建时间:
2025-06-11
原始信息汇总
PubMed Abstracts Subset (10%) 数据集概述
📄 数据集描述
- 内容:包含所有公开可用的PubMed元数据的概率样本(10%子集)
- 数据条目:
id:本地唯一标识符title:出版物标题abstract:摘要文本PMID:PubMed标识符
- 数据量:约239万样本
- 文件结构:24个
.jsonl文件,每个文件约10万条目
🔍 访问方式
选项1:使用Hugging Face datasets加载(流式)
python from datasets import load_dataset dataset = load_dataset("slinusc/PubMedAbstractsSubset", streaming=True)
选项2:使用Git和Git LFS克隆
bash git lfs install git clone https://huggingface.co/datasets/slinusc/PubMedAbstractsSubset
📦 数据格式
- 格式:JSON Lines (
.jsonl) - 示例结构: json { "id": "pubmed23n1166_0", "title": "...", "abstract": "...", "PMID": 36464820 }
📚 来源与许可
- 来源:美国国家医学图书馆(NLM)的PubMed公共领域元数据
- 许可证:CC0-1.0
- 使用政策:符合NLM数据使用政策
🏷️ 版本信息
- 当前版本:v1.0(初始版本)
📬 联系方式
- 维护者:@slinusc
- 问题反馈:通过Hugging Face数据集页面提交讨论或拉取请求
搜集汇总
数据集介绍
构建方式
在生物医学文献挖掘领域,PubMedAbstractsSubset数据集通过概率抽样方法从美国国家医学图书馆的公开元数据中系统构建。该过程严格遵循NLM数据使用政策,确保数据来源的合法性与权威性。数据集以24个JSONL文件形式组织,每个文件包含约10万条经过结构化处理的文献记录,总计约239万篇文献的标题、摘要及PubMed标识符,为大规模生物医学文本分析提供了高质量基础。
使用方法
研究者可通过Hugging Face datasets库的流式加载功能高效访问数据,避免全量加载的内存压力,特别适合分布式计算环境。对于本地化处理需求,用户可借助Git LFS技术完整克隆数据集,并通过标准JSONL解析工具进行逐行处理。该数据集可直接应用于生物医学文本分类、信息抽取和问答系统构建,其预计算嵌入版本更能显著提升检索增强生成系统的开发效率与可复现性。
背景与挑战
背景概述
PubMedAbstractsSubset数据集由Stuhlmann等研究人员于2025年创建,源自美国国家医学图书馆的公开文献元数据。该数据集聚焦于生物医学信息检索与自然语言处理领域,核心研究问题在于提升医学文献的检索效率与问答系统的可复现性。通过整合约239万篇文献的标题与摘要信息,为医学知识挖掘和智能问答系统提供了高质量语料基础,显著推动了生物医学人工智能应用的发展。
当前挑战
该数据集主要应对生物医学领域复杂术语理解和长文本语义匹配的挑战,需解决医学术语多样性、同义词变异及上下文相关性判断等问题。构建过程中面临大规模数据清洗与标准化难题,包括摘要格式不一致、特殊字符处理以及文献质量筛选等技术障碍,同时需确保数据分布的代表性与医学主题的全面覆盖。
常用场景
经典使用场景
在生物医学信息抽取领域,PubMedAbstractsSubset数据集为研究者提供了大规模结构化文献摘要资源。该数据集最经典的应用场景是构建生物医学文献检索系统,通过标题和摘要文本训练深度检索模型,实现高效的相关文献推荐。研究人员利用其丰富的语义信息开发智能文献筛选工具,显著提升学术文献调研效率,为系统性综述和元分析研究提供数据支撑。
解决学术问题
该数据集有效解决了生物医学自然语言处理中的标注数据稀缺问题。通过提供数百万篇经过专业标注的学术摘要,支持了生物医学实体识别、关系抽取和文本分类等核心任务的模型训练。其标准化格式消除了数据预处理障碍,使得研究人员能够专注于算法创新,显著推进了生物医学文本挖掘技术的发展,为临床决策支持系统提供理论基础。
实际应用
在临床实践场景中,该数据集支撑了智能医学问答系统的开发。医疗机构利用其训练的检索增强生成模型,能够快速从海量文献中提取相关医学证据,辅助医生进行诊断决策。制药公司则借助该数据集进行药物重定位研究,通过文献挖掘发现潜在的治疗方案,加速药物研发进程。这些应用切实改善了医疗信息服务的效率和质量。
数据集最近研究
最新研究方向
PubMedAbstractsSubset数据集作为生物医学文本挖掘的重要资源,正推动检索增强生成(RAG)技术在智能问答系统领域的突破性进展。基于该数据集训练的MedCPT嵌入向量显著提升了文献检索的精准度和效率,为临床决策支持系统提供了可靠的知识溯源能力。当前研究聚焦于跨模态医学信息融合、证据链自动生成及低资源语言适配等前沿方向,这些探索不仅加速了医学人工智能的可解释性发展,更在全球公共卫生事件应急响应中展现出关键价值。
以上内容由遇见数据集搜集并总结生成


