WangchanLION-Curated
收藏Hugging Face2025-07-22 更新2025-07-23 收录
下载链接:
https://huggingface.co/datasets/aisingapore/WangchanLION-Curated
下载链接
链接失效反馈官方服务:
资源简介:
Magostreen是一个包含泰语文档的数据集,文档来源多样,包括百科全书、金融、政府文件、法律、YouTube视频和教育活动等。数据集经过去重处理,分为训练集和验证集,用于自然语言处理任务。所有文档均为开源且拥有允许重分发的版权许可。
Magostreen is a dataset containing Thai language documents. The documents originate from diverse sources, including encyclopedias, finance-related materials, government documents, legal texts, YouTube videos, and educational activities. The dataset has been deduplicated and split into training and validation sets for natural language processing tasks. All documents are open-source and come with copyright licenses that permit redistribution.
提供机构:
AI Singapore
创建时间:
2025-07-09
原始信息汇总
数据集概述:WangchanLION-Curated
基本信息
- 许可证:odc-by
- 语言:泰语 (th)
- 标签:legal, finance, medical
- 数据集名称:Magostreen
- 大小类别:1M<n<10M
数据集结构
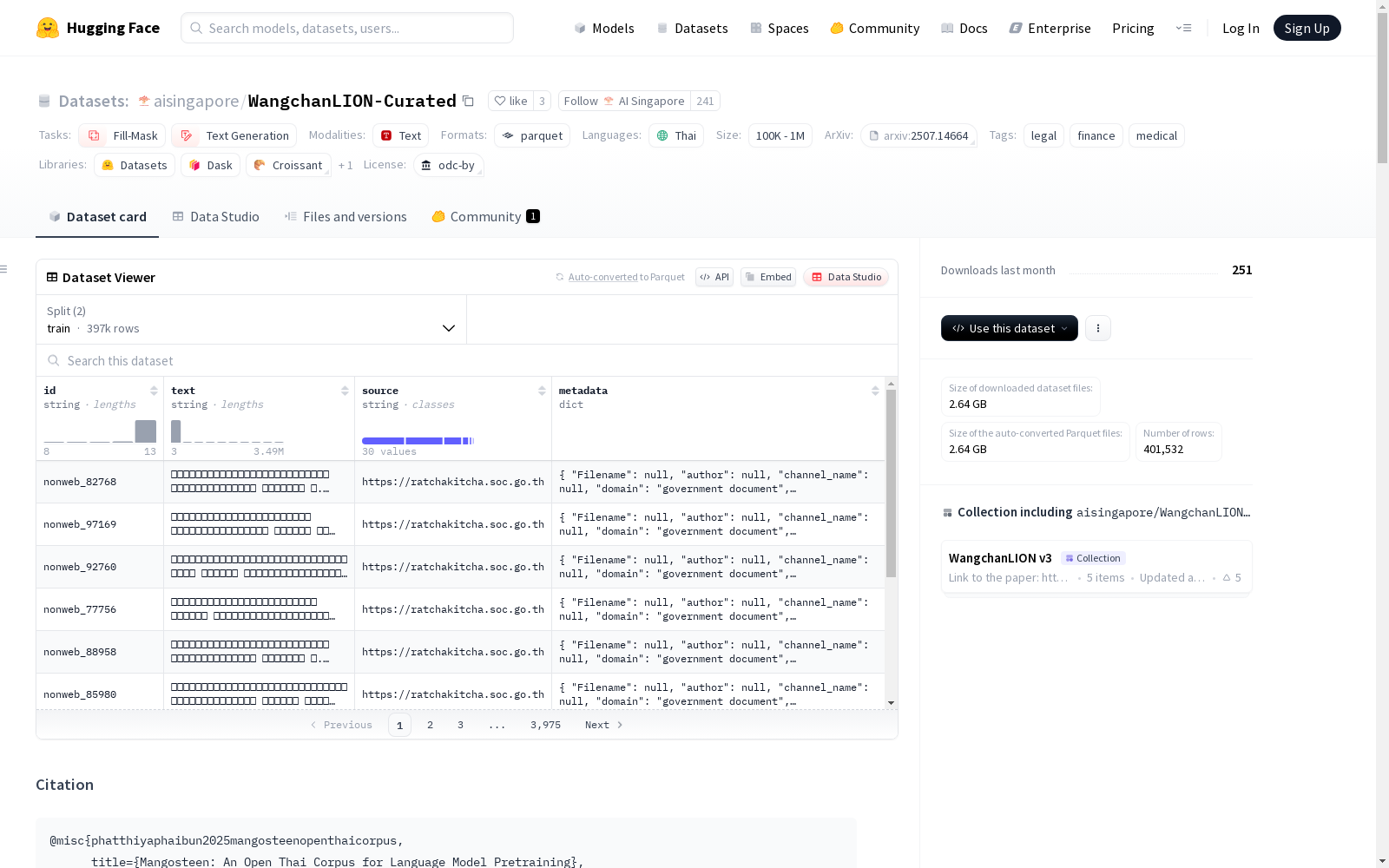
特征
id:字符串类型text:字符串类型source:字符串类型metadata:结构体类型,包含以下字段:Filename:字符串类型author:字符串类型channel_name:字符串类型domain:字符串类型is_subtitle_generated:字符串类型license:字符串类型provenance:字符串类型revid:字符串类型src:字符串类型ticker:字符串类型title:字符串类型url:字符串类型year:float64类型
数据分割
- 训练集:
- 字节数:8,513,541,142
- 样本数:397,488
- 验证集:
- 字节数:83,508,453
- 样本数:4,044
- 下载大小:2,639,043,294
- 数据集大小:8,597,049,595
数据来源与分类
数据来源分析
| 类型 | 来源 | 文档数量 | 单词数量 |
|---|---|---|---|
| 百科全书类 | th.wikibooks.org, th.wikipedia.org 等 | 166,187 | 80,666,790 |
| 金融类 | airesearch/cmdf_vistec | 86,813 | 348,189,390 |
| 政府文件类 | data.go.th, ratchakitcha.soc.go.th 等 | 72,879 | 184,030,056 |
| 法律类 | pythainlp/thailaw-v1.0 等 | 52,343 | 79,715,118 |
| YouTube类 | youtube | 17,837 | 46,613,632 |
| 教育类 | openbase.in.th, pythainlp/thai-it-books 等 | 5,911 | 165,909,425 |
数据域分布
| 域 | 数量 | 比例 |
|---|---|---|
| 百科全书类 | 166,187 | 41.34% |
| 金融类 | 86,813 | 21.59% |
| 政府文件类 | 72,879 | 18.13% |
| 法律类 | 52,343 | 13.02% |
| YouTube类 | 17,837 | 4.43% |
| 教育类 | 5,911 | 1.47% |
许可证分布
| 许可证 | 数量 | 比例 |
|---|---|---|
| CC BY-SA 4.0 | 166,187 | 41.388233% |
| CC0 | 112,871 | 28.110088% |
| CC BY 4.0 | 112,407 | 27.994531% |
| CC BY-NC-SA 4.0 | 4,173 | 1.039270% |
| ODC-BY | 3,769 | 0.938655% |
| 其他 | 2,125 | 0.529223% |
相关资源
- 预训练数据(网页):https://huggingface.co/datasets/aisingapore/WangchanLION-Web
- 预训练模型:https://huggingface.co/aisingapore/WangchanLION-v3
- SFT模型:https://huggingface.co/aisingapore/WangchanLION-v3-IT
- 论文:https://arxiv.org/abs/2507.14664
- 博客:https://sea-lion.ai/sea-lion-wangchanlionv3/
- GitHub:https://github.com/vistec-AI/Mangosteen
搜集汇总
数据集介绍
构建方式
在泰语自然语言处理领域,WangchanLION-Curated数据集通过系统化采集与处理多源文本构建而成。研究团队从维基百科、政府门户、学术期刊及YouTube等42万余个文档中筛选材料,采用光学字符识别技术处理PDF格式文件,并严格遵循去重流程确保数据唯一性。所有文本均经过开源许可验证,最终形成包含训练集和验证集的标准化语料库。
特点
该数据集涵盖百科全书、金融、法律、政府文档、教育及视频字幕六大领域,其中百科全书类占比41.34%,金融文本达21.59%,呈现显著的领域多样性。数据包含丰富的元数据结构,涵盖作者信息、来源渠道、许可协议等13个维度,且全部文本均标注文化安全性和跨语言适用性评估标签,为泰语语言模型研究提供多维度分析基础。
使用方法
研究者可通过HuggingFace平台直接加载数据集,默认配置包含train与validation两个数据分割。每个样本包含原始文本、来源标识及结构化元数据,支持掩码填充和文本生成任务。使用时应遵循ODC-BY许可协议,并可结合论文提供的预处理代码进行领域特异性数据筛选与增强处理。
背景与挑战
背景概述
WangchanLION-Curated数据集由泰国VISTEC人工智能研究所主导构建,于2025年正式发布,旨在解决泰语自然语言处理领域高质量训练数据匮乏的核心问题。该数据集汇聚了百科全书、金融文档、政府文件、法律条文、学术文献及视频字幕等多领域文本,总计超过40万篇经过严格去重与许可验证的语料。作为Mangosteen泰语语料库计划的核心组成部分,它不仅为泰语预训练模型提供了文化适配性强的数据基础,更推动了东南亚语言模型研究的标准化进程。
当前挑战
该数据集致力于解决泰语文本理解与生成任务中因数据稀疏导致的模型泛化能力不足问题,其构建过程面临多重挑战:首先需从异构来源(如PDF、网页、视频字幕)提取文本,其中约5.3%的文档需依赖OCR技术进行高精度转换;其次需协调六类不同领域数据的版权许可,确保CC BY-SA 4.0、CC0等11种许可证的合规使用;最后需应对泰语语言特性带来的分词与语义消歧难题,尤其在法律和政府文档中需保持专业术语的一致性。
常用场景
经典使用场景
在泰语自然语言处理研究中,WangchanLION-Curated数据集作为高质量语料库,主要应用于语言模型的预训练任务。其覆盖百科全书、金融、法律、政府文档等多领域文本,为构建泰语掩码语言模型和文本生成模型提供丰富的语言表征学习素材。该数据集通过严格的去重处理和OCR技术增强,确保了训练数据的多样性和准确性,成为泰语大模型开发的核心基础资源。
实际应用
在实际应用层面,该数据集支撑了泰语智能客服、法律文档分析、金融风险监测等关键场景。基于此训练的模型能够处理泰国政府部门的公文理解、金融机构的风险报告生成以及医疗领域的文献检索等任务。其包含的YouTube转录文本和学术文献资源,进一步增强了模型在口语化表达和专业术语处理方面的实用性,为泰国数字化转型提供语言技术基础设施。
衍生相关工作
该数据集催生了多个里程碑式研究成果,包括WangchanLION-v3预训练模型及其指令微调版本WangchanLION-v3-IT。相关研究团队在此基础上开发了跨语言对齐技术和文化安全评估框架,这些成果发表于arXiv等学术平台。数据集的开源特性还促进了泰国多所高校联合开展的低资源语言模型优化研究,形成了完整的泰语NLP技术生态体系。
以上内容由遇见数据集搜集并总结生成


