ru-alpaca-logic
收藏Hugging Face2024-12-25 更新2024-12-26 收录
下载链接:
https://huggingface.co/datasets/ai-bond/ru-alpaca-logic
下载链接
链接失效反馈官方服务:
资源简介:
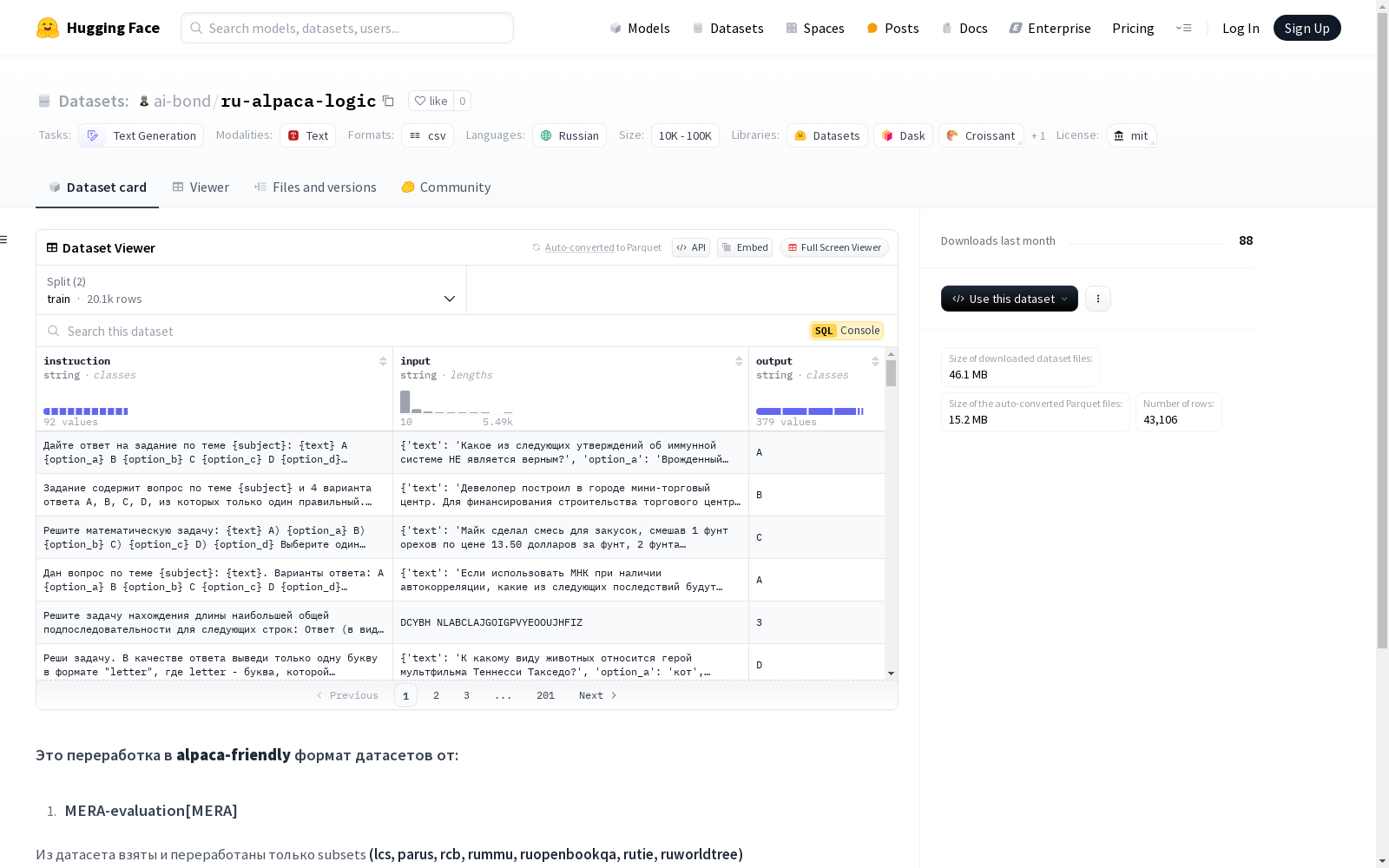
该数据集是一个用于文本生成的俄语数据集,采用MIT许可证。数据集包含三个主要特征:instruction(指令)、input(输入)和output(输出),均为字符串类型。数据集是对MERA-evaluation和Vikhrmodels数据集的重新格式化,以适应alpaca-friendly格式。具体来说,从MERA-evaluation数据集中选取了lcs、parus、rcb、rummu、ruopenbookqa、rutie和ruworldtree等子集,并对Vikhrmodels中的law_mc数据集进行了重新格式化。训练集中包含20088个input_ids,最大长度为1801,当上下文长度为1024时,有18次溢出。
This is a Russian text generation dataset licensed under the MIT License. It includes three core fields: instruction, input, and output, all of string data type. This dataset is reformatted from the MERA-evaluation and Vikhrmodels datasets to fit the alpaca-friendly format. Specifically, subsets including lcs, parus, rcb, rummu, ruopenbookqa, rutie, and ruworldtree are selected from the MERA-evaluation dataset, and the law_mc dataset from Vikhrmodels is also reformatted. The training split contains 20088 input_ids, with a maximum sequence length of 1801, and there are 18 overflow cases when the context length is set to 1024.
创建时间:
2024-12-17
搜集汇总
数据集介绍
构建方式
ru-alpaca-logic数据集是通过对多个现有数据集进行重新加工和整合而构建的。具体而言,该数据集从MERA-evaluation数据集中选取了lcs、parus、rcb、rummu、ruopenbookqa、rutie和ruworldtree等子集,并对其进行了alpaca-friendly格式的转换。此外,Vikhrmodels数据集中的law_mc部分也被重新格式化以适应需求。最终,数据集包含了20088条训练样本,其中最长输入长度为1801个字符,且在上下文长度为1024的情况下,仅有18条数据溢出。
特点
ru-alpaca-logic数据集的特点在于其专注于俄语文本生成任务,并采用了alpaca-friendly格式,便于模型训练和评估。数据集包含三个主要字段:instruction(指令)、input(输入)和output(输出),这些字段为模型提供了明确的上下文和生成目标。此外,数据集的多样性和复杂性体现在其涵盖了多个子集,涵盖了从逻辑推理到开放域问答的广泛任务类型,为模型提供了丰富的训练素材。
使用方法
ru-alpaca-logic数据集的使用方法相对直观,适用于文本生成模型的训练和评估。用户可以通过加载数据集的train和test分割,分别用于模型的训练和测试阶段。每条数据包含的instruction、input和output字段为模型提供了明确的上下文和生成目标,用户可以根据需要调整模型的输入输出格式。此外,由于数据集已经过预处理,用户可以直接将其应用于现有的文本生成框架,如Hugging Face的Transformers库,以快速实现模型的训练和评估。
背景与挑战
背景概述
ru-alpaca-logic数据集是一个专注于俄语文本生成任务的数据集,其构建灵感源自于alpaca-friendly格式,旨在为俄语自然语言处理领域提供高质量的指令-输入-输出三元组数据。该数据集由多个子集整合而成,包括MERA-evaluation和Vikhrmodels等来源,涵盖了逻辑推理、阅读理解、法律问答等多个领域。其创建时间为近期,主要研究人员或机构未明确提及,但其核心研究问题在于提升俄语文本生成模型的逻辑推理能力和多任务处理能力。该数据集的发布为俄语NLP领域的研究者提供了宝贵的资源,推动了俄语语言模型在多任务学习中的发展。
当前挑战
ru-alpaca-logic数据集在解决俄语文本生成任务时面临多重挑战。首先,俄语作为一种形态丰富且语法复杂的语言,其文本生成任务需要模型具备较高的语言理解和逻辑推理能力,这对数据集的多样性和质量提出了严格要求。其次,在数据集构建过程中,如何从多个来源的子集中筛选、整合并重新格式化数据,确保其符合alpaca-friendly格式,是一项复杂且耗时的工作。此外,数据集中存在部分输入文本长度过长的问题,导致在模型训练时可能产生溢出,这对数据处理和模型优化提出了额外的技术挑战。这些挑战不仅影响了数据集的构建效率,也对后续模型的训练和评估提出了更高的要求。
常用场景
经典使用场景
在自然语言处理领域,ru-alpaca-logic数据集主要用于文本生成任务,特别是在俄语环境下的逻辑推理和问答系统开发。该数据集通过提供结构化的指令、输入和输出,使得研究人员能够训练和评估模型在理解和执行复杂逻辑任务方面的能力。
衍生相关工作
基于ru-alpaca-logic数据集,研究人员已经开发出多种先进的俄语文本生成模型和逻辑推理系统。这些工作不仅提升了俄语NLP领域的技术水平,还为其他语言的自然语言处理研究提供了宝贵的参考和借鉴。
数据集最近研究
最新研究方向
在自然语言处理领域,ru-alpaca-logic数据集以其独特的俄语文本生成任务引起了广泛关注。该数据集整合了MERA-evaluation和Vikhrmodels中的多个子集,经过alpaca-friendly格式的重新加工,特别适用于逻辑推理和问答系统的训练与评估。当前研究热点集中在如何利用该数据集提升俄语语言模型在复杂逻辑推理任务中的表现,尤其是在法律和开放领域问答中的应用。这一研究方向不仅推动了俄语NLP技术的发展,也为跨语言模型的优化提供了新的视角和实验平台。
以上内容由遇见数据集搜集并总结生成


