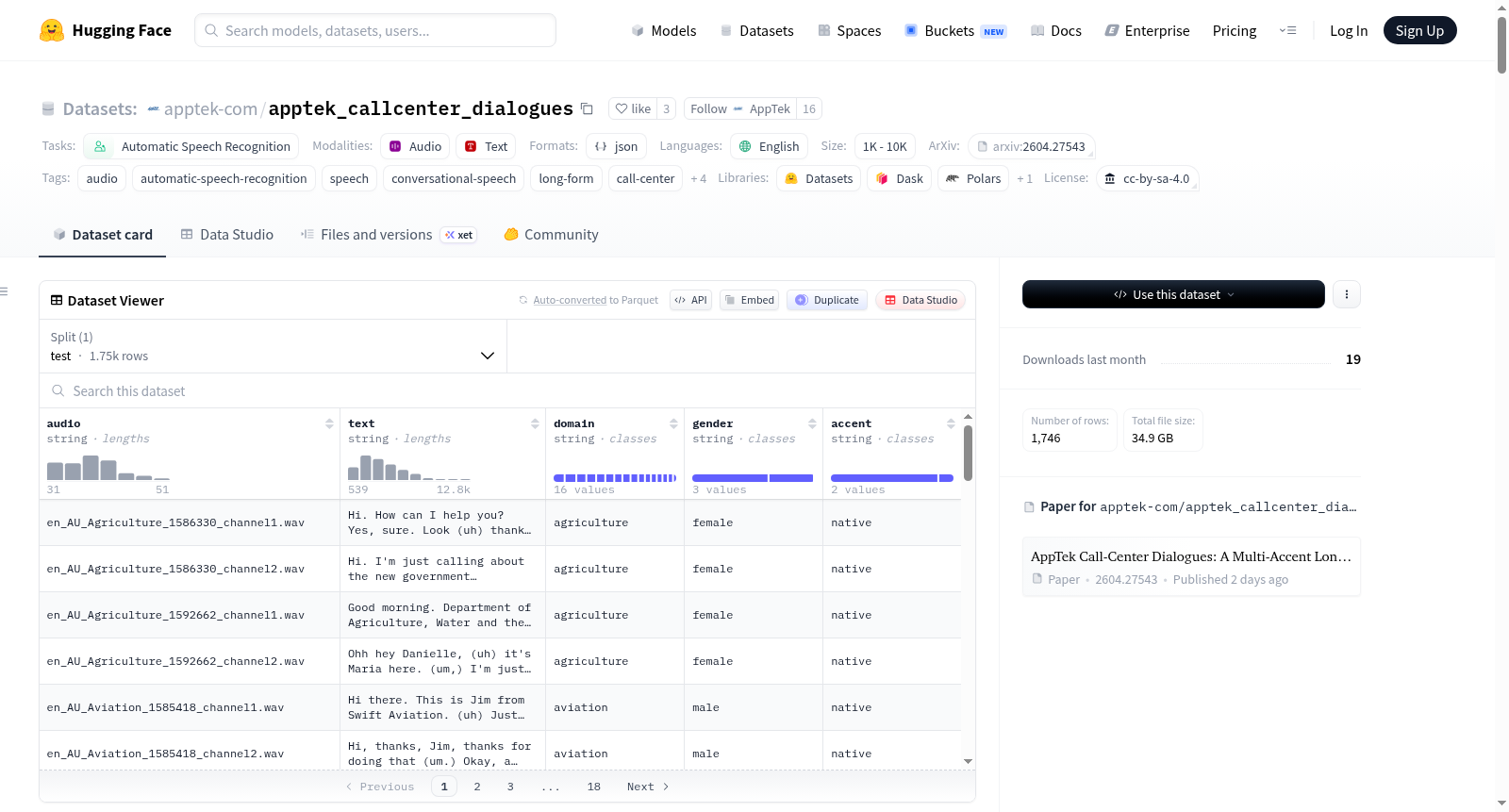
AppTek Call-Center Dialogues
收藏AppTek Call-Center Dialogues 数据集详情
数据集概述
AppTek Call-Center Dialogues 是一个面向英语自动语音识别(ASR)的长篇对话语音基准数据集,涵盖多种英语口音和服务领域,专为评估模型在真实呼叫中心场景下的表现而设计。
- 总时长: 128.6 小时
- 口音组: 14 个
- 服务领域: 16 个
- 对话时长: 5–15 分钟(长篇形式)
- 音频格式: 分声道音频(每文件一个说话人)
数据集用途
直接用途
- ASR 基准测试
- 长篇转录评估
- 口音鲁棒性分析
- 对话式 AI 评估
- 对分割敏感的 ASR 评估
非预期用途
- 不用于训练或微调 ASR 或基础模型
- 不适用于需要真实客户数据的应用
数据集结构
数据组织
数据集按口音组组织:
<accent>/ audio/ test.jsonl
每个对话包含两个单声道音频文件(每个说话人一个)。
数据特征
| 指标 | 数值 |
|---|---|
| 总时长 | 128.6 小时 |
| 说话人数 | 156 |
| 口音组数 | 14 |
| 领域数 | 16 |
| 对话数 | 873 |
| 音频文件(声道) | 1,746 |
| 平均对话长度 | 10.4 分钟 |
| 对话长度范围 | 5–15 分钟 |
| 每种口音时长 | ~8–11 小时 |
数据字段
- audio: 音频文件名
- text: 逐字转录文本
- domain: 服务场景
- gender: 说话人性别
- accent: 口音元数据
数据实例
json { "audio": "en_ZA_Agriculture_1582346_channel1.wav", "text": "Good morning, thank you for calling...", "domain": "agriculture", "gender": "female", "accent": "native" }
数据划分
| 划分 | 大小 |
|---|---|
| test | 128.6 小时(1,746 个文件) |
口音编码
| 编码 | 口音 |
|---|---|
| en-AU | 澳大利亚英语 |
| en-CA | 加拿大英语 |
| en-CN | 中式英语 |
| en-GB | 英式英语 |
| en-GB_SCT | 苏格兰英语 |
| en-GB_WLS | 威尔士英语 |
| en-IE | 爱尔兰英语 |
| en-IN | 印度英语 |
| en-MX | 墨西哥英语 |
| en-SG | 新加坡英语 |
| en-US_Aave | 非裔美国英语 |
| en-US_General | 标准美式英语 |
| en-US_Southern | 美国南部英语 |
| en-ZA | 南非英语 |
创建与标注
数据来源
- 角色扮演的客服与客户对话
- 通过 VoIP 平台录制
- 时长:每会话 5–15 分钟(平均 10.4 分钟)
- 设备:笔记本电脑(53%)、手机(42%)、平板(5%)
- 环境:家中(78%)、室内公共场所(19%)、户外(3%)
说话人信息
- 最小年龄: 18 岁
- 说话人数: 156
- 性别分布: 女性 102 人,男性 54 人
- 年龄分布: 18–30 岁 76 人,30–50 岁 56 人,50–70 岁 24 人
标注过程
- 完全手动转录(无预生成 ASR 输出)
- 多阶段质量保证流程
- 自动一致性检查:约 10% 的片段被标记复审,其中约 40% 被修正
- 标注人员: 85 名专业标注员,母语或高度熟悉目标口音
评估方法
评估指标
使用 词错误率(WER),通过 jiwer 计算。
评分协议
标准化归一化流程:
- 预处理:去除特定犹豫标记和部分单词
- 归一化:Whisper EnglishTextNormalizer
- 后处理:数据集特定单词映射(数字、时间、词汇变体)
- 最终处理:小写化、去除标点、空白归一化、分词
推荐分割方法
- 推荐工具: Silero VAD
- 最小静默时长: 10.0 秒
- 最小语音时长: 0.25 秒
- 最大语音时长: 30 秒
- 平均片段长度: ~16.5 秒
示例基准结果
| 模型 | WER (%) |
|---|---|
| Qwen3-ASR (1.7B) | 8.3 |
| Parakeet v3 (0.6B) | 9.2 |
| Canary-Qwen (2.5B) | 9.2 |
| Granite Speech (8B) | 11.9 |
| Whisper Large v3 | 15.0 |
偏见、风险与局限
- 角色扮演的交互(非真实客户通话)
- 领域覆盖有限(仅服务场景)
- 口音标签为粗粒度离散分类
- 不同口音组间人口统计不平衡
- 某些口音由有限说话人样本代表
引用
BibTeX:
@misc{beck2026apptekcallcenterdialoguesmultiaccent, title={AppTek Call-Center Dialogues: A Multi-Accent Long-Form Benchmark for English ASR}, author={Eugen Beck and Sarah Beranek and Uma Moothiringote and Daniel Mann and Wilfried Michel and Katie Nguyen and Taylor Tragemann}, year={2026}, eprint={2604.27543}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2604.27543}, }
APA: Beck, E., Beranek, S., Moothiringote, U., Mann, D., Michel, D., Nguyen, K., & Tragemann, T. (2026). AppTek Call-Center Dialogues: A Multi-Accent Long-Form Benchmark for English ASR. https://arxiv.org/abs/2604.27543
许可证
- 许可协议: CC BY-SA 4.0
- 策划方: AppTek.ai
- 资助方: AppTek.ai
- 发布方: AppTek.ai