PROFASR-BENCH
收藏arXiv2025-12-30 更新2025-12-31 收录
下载链接:
https://huggingface.co/datasets/prdeepakbabu/ProfASR-Bench
下载链接
链接失效反馈官方服务:
资源简介:
PROFASR-BENCH是由研究者Deepak Babu Piskala构建的专业场景语音识别评测数据集,聚焦金融、医疗、法律和技术四大高风险领域。该数据集包含自然语言提示与实体密集的目标话语配对数据,通过合成语音管道生成,确保专业术语覆盖和口音/性别多样性。其核心价值在于支持上下文条件化评估,包含实体感知指标和分片公平性分析,旨在解决传统ASR系统在专业术语识别和上下文利用不足的痛点。数据集采用标准化报告格式,为语音模型的实时领域适应能力提供基准测试框架。
PROFASR-BENCH is a specialized speech recognition evaluation dataset constructed by researcher Deepak Babu Piskala, focusing on four high-risk domains: finance, healthcare, law, and technology. This dataset includes paired data of natural language prompts and entity-dense target utterances, which is generated via a synthetic speech pipeline to ensure coverage of professional terminology and diversity in accents and genders. Its core value lies in supporting context-conditioned evaluation, which covers entity-aware metrics and slice-based fairness analysis, aiming to address the pain points of traditional ASR systems, namely insufficient recognition of professional terms and inadequate utilization of context. The dataset adopts a standardized reporting format and provides a benchmarking framework for evaluating the real-time domain adaptation capabilities of speech models.
创建时间:
2025-12-30
原始信息汇总
ProfASR-Bench 数据集概述
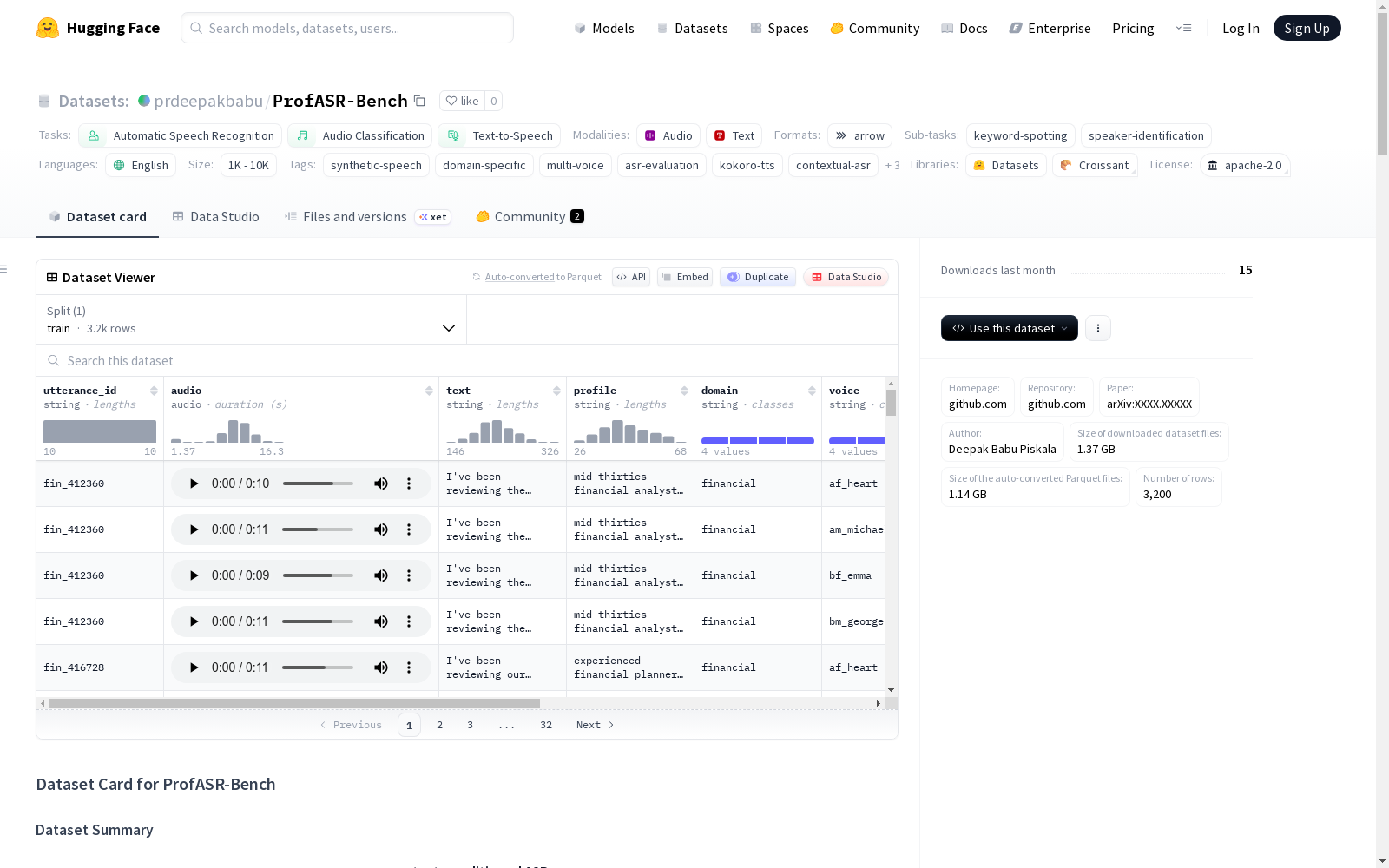
数据集基本信息
- 数据集名称:ProfASR-Bench
- 主页:https://github.com/prdeepakbabu/ProfASR-Bench
- 代码库:https://github.com/prdeepakbabu/ProfASR-Bench
- 论文:https://arxiv.org/abs/XXXX.XXXXX
- 作者:Deepak Babu Piskala
- 许可协议:Apache 2.0 License
- 语言:英语
- 规模:1K<n<10K
- 任务类别:自动语音识别、音频分类、文本转语音
- 任务ID:关键词识别、说话人识别
- 标签:合成语音、领域特定、多说话人、ASR评估、kokoro-tts、上下文ASR、专业谈话、实体识别、提示条件
数据集描述
ProfASR-Bench 是一个用于金融、医学、法律和技术等高风险应用领域的上下文条件自动语音识别的专业谈话评估套件。每个示例将一个自然语言提示(领域线索和/或说话人档案)与一个富含实体的目标话语配对,从而能够对上下文条件识别进行受控测量。
关键发现 - 上下文利用差距:当前系统名义上可提示,但未能充分利用现成的辅助信息。
支持的任务
- 主要任务:上下文条件自动语音识别
- 次要任务:
- 实体感知的ASR评估
- 分片公平性分析
- 对抗鲁棒性测试
- 领域适应研究
数据集结构
数据实例
每个数据实例包含:
- 音频:高质量WAV文件(22kHz采样率)
- 文本/真实转录:真实转录文本
- 提示:用于上下文条件处理的先前句子
- 元数据:领域、语音、说话人档案、ASR难度分数、命名实体
数据字段
- utterance_id:每个话语的唯一标识符
- audio:采样率为22050 Hz的音频文件
- text/truth:真实转录文本
- profile:说话人档案
- domain:专业领域
- voice:语音档案
- asr_difficulty:ASR转录难度分数
- sentences:句子序列
- prompt:提示序列
- truth:真实转录
语音档案
| 语音ID | 口音 | 性别 | 描述 |
|---|---|---|---|
af_heart |
美式 | 女性 | 高品质 |
am_michael |
美式 | 男性 | 温暖可信 |
bf_emma |
英式 | 女性 | 专业且温暖 |
bm_george |
英式 | 男性 | 清晰明确 |
数据划分
- train:3200个示例
评估协议:上下文阶梯
ProfASR-Bench支持在5种提示条件下进行系统评估:
| 条件 | 描述 |
|---|---|
| NO-PROMPT | 控制基线 |
| PROFILE | 仅说话人属性 |
| DOMAIN+PROFILE | 领域线索 + 说话人属性 |
| ORACLE | 黄金转录作为提示 |
| ADVERSARIAL | 不匹配的领域提示 |
数据集创建
数据来源
- 文本生成:Claude 3.7 Sonnet,使用领域特定提示
- 语音合成:Kokoro 82M TTS
- 实体覆盖:>97%的类型化实体分配
个人和敏感信息
数据集不包含任何个人信息,所有内容均为合成生成。说话人档案是为上下文真实性创建的虚构角色。
使用注意事项
社会影响
- 积极影响:
- 为高风险专业环境提供更好的ASR系统
- 通过合成生成减少隐私问题
- 促进可重复的ASR研究
已知限制
- 合成性质:生成的语音可能缺乏某些人类语音特征
- 领域覆盖:仅限于四个专业领域
- 语音多样性:四个语音档案可能无法捕捉完整的说话人变化
- 语言:仅限英语数据集
引用
bibtex @article{piskala2025profasrbench, title={ProfASR-Bench: A Professional-Talk ASR Dataset for High-Stakes Applications Exposing the Context-Utilization Gap}, author={Piskala, Deepak Babu}, journal={arXiv preprint arXiv:XXXX.XXXXX}, year={2025}, url={https://arxiv.org/abs/XXXX.XXXXX} }
搜集汇总
数据集介绍
构建方式
在专业语音识别领域,构建高质量评估数据集需兼顾领域术语的密集性与语境信息的可控性。PROFASR-BENCH采用系统化的合成流程生成,首先基于金融、医疗、法律和技术四大高风险领域设计专业场景与人物角色,利用指令调优的大语言模型生成富含命名实体的正式文本。随后通过神经文本转语音系统,以程序化方式控制语音的口音与性别变体,生成高质量音频。每个样本均包含自然语言提示与目标话语的配对,并经过自动验证以确保文本与音频在专业语域、实体覆盖及提示一致性方面的质量,最终形成结构化的评估语料库。
特点
该数据集的核心特征在于其针对高风险专业场景的深度定制化设计。其话语中密集分布着领域关键实体,如药物名称、法律条款、金融指标与技术协议,从而能够有效测试模型在信息承载单元上的识别能力。数据集提供了标准化的语境阶梯,涵盖从无提示到完整领域与人物组合的多种条件,支持在相同话语上进行配对比较。此外,数据集整合了口音与性别的切片元数据,以及实体感知的标注体系,使得评估不仅能反映整体词错误率,更能深入揭示模型在关键实体识别上的表现与潜在的公平性差距。
使用方法
使用PROFASR-BENCH进行评估时,研究者可遵循其配套的标准化协议进行系统测试。评估首先需将模型置于不同的提示条件下运行,包括无提示、仅人物档案、领域加档案、完美提示及对抗性提示等,以量化语境利用的效果。在指标计算上,除传统的词错误率和句错误率外,应重点采用实体感知的指标,如实体词错误率与实体F1分数,以捕捉模型在关键术语上的识别精度。分析过程需包含基于口音与性别的切片报告,并计算配对置信区间,从而确保结果在不同模型家族与解码策略间具有可比性,最终系统性地诊断语境利用差距。
背景与挑战
背景概述
自动语音识别技术在通用基准上已取得显著进展,但在金融、医疗、法律与技术等高风险专业领域,其性能仍面临严峻考验。这些领域的话语通常包含密集的专业术语与实体名称,且对关键信息的识别错误容忍度极低。为系统评估上下文条件化ASR模型在此类场景下的能力,研究人员于2025年发布了PROFASR-BENCH数据集。该数据集由Deepak Babu Piskala等人构建,旨在通过配对自然语言提示与富含实体的目标话语,模拟真实交互系统中可用的上下文信息,从而精确衡量模型利用侧信息进行语音识别的效果。其核心研究问题聚焦于如何通过提示条件化机制,提升ASR系统在专业话语中对领域关键实体的识别准确率,弥补现有基准在上下文评估方面的不足。
当前挑战
PROFASR-BENCH数据集致力于解决高风险专业领域自动语音识别中的核心挑战:模型难以有效利用可用的上下文信息来准确识别领域特定术语与关键实体,如药物名称、法律条款或金融代码。尽管当前ASR系统在形式上支持提示输入,但评估揭示出显著的上下文利用差距,即轻量级文本提示对平均词错误率改善微乎其微,甚至提供完美转录文本作为提示也收效甚微。在构建过程中,挑战主要源于如何平衡数据真实性、可控性与合规性。为保障专业领域数据的可公开获取并实现严格的实验控制,数据集采用合成语音生成,需精心设计提示-话语对以确保语境连贯性,同时覆盖多领域、多口音与性别的切片以支持公平性分析,并建立实体中心化评估指标以更真实地反映实际应用风险。
常用场景
经典使用场景
在自动语音识别领域,专业场景下的高精度转录需求日益凸显,PROFASR-BENCH数据集应运而生,成为评估上下文条件化ASR系统性能的核心工具。该数据集通过构建金融、医疗、法律和技术四大高风险领域的实体密集话语,并配以自然语言提示(如领域线索或说话者档案),系统性地模拟了真实交互系统中上下文信息的可用性。其经典使用场景在于为研究人员提供一个标准化测试平台,用以量化轻量级上下文对专业术语识别效果的影响,尤其是在控制条件下比较无上下文与有上下文配置的识别准确度差异。
衍生相关工作
围绕PROFASR-BENCH所揭示的上下文利用鸿沟,学术界已衍生出一系列旨在增强ASR系统上下文融合能力的研究工作。这些工作主要沿两个方向展开:一是改进模型架构,如Deep-CLAS等研究通过设计更深层的上下文编码器和注意力机制来提升对稀有词汇的识别;二是探索新的训练与解码策略,例如引入辅助偏置损失函数以聚焦于上下文相关词元,或开发约束解码算法来显式利用提示信息。这些衍生工作共同推动了提示条件化ASR从简单的前缀式 conditioning 向更精细、可控的上下文利用机制演进。
数据集最近研究
最新研究方向
在专业高风险的自动语音识别领域,PROFASR-BENCH数据集的推出揭示了当前模型在上下文利用方面存在的显著差距。该数据集聚焦于金融、医疗、法律和技术等关键行业,通过构建包含丰富实体术语的语音样本与自然语言提示的配对,系统评估了模型在上下文条件识别中的表现。研究发现,即便提供黄金转录文本作为提示,主流模型如Whisper在平均词错误率上改善微乎其微,而对抗性提示也未能可靠地降低性能,这一现象被定义为“上下文利用鸿沟”。前沿研究正致力于探索更强的融合机制,如学习相关性门控、短语编码器以及约束解码策略,以提升模型对关键实体的识别精度,同时推动实体感知度量和分片公平性分析,确保语音识别系统在高风险应用中的可靠性与安全性。
相关研究论文
- 1PROFASR-BENCH: A Benchmark for Context-Conditioned ASR in High-Stakes Professional Speech · 2025年
以上内容由遇见数据集搜集并总结生成


