metamath-qwen2-math
收藏Hugging Face2024-08-27 更新2024-12-12 收录
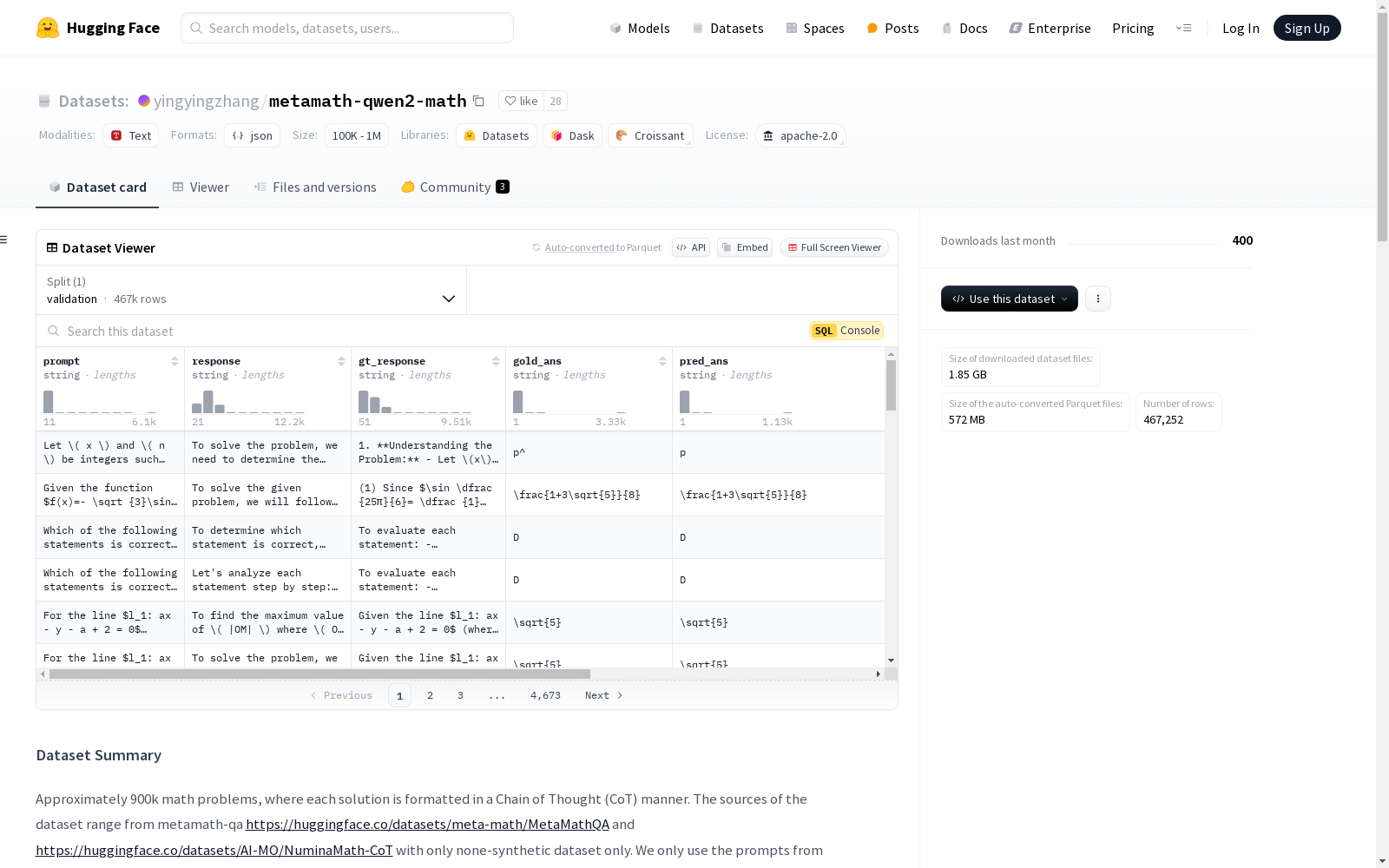
下载链接:
https://huggingface.co/datasets/yingyingzhang/metamath-qwen2-math
下载链接
链接失效反馈资源简介:
该数据集包含约90万个数学问题,每个问题的解答都以思维链(Chain of Thought, CoT)的方式格式化。数据集来源包括metamath-qa和NuminaMath-CoT,但仅使用非合成数据。数据集的构建过程中使用了Qwen2-math-72-instruct和拒绝采样技术,并且解答是基于官方评估代码库进行筛选的。此外,数据集还包括了NuminaMath-CoT的非合成部分,这些部分由Qwen2-math-72-instruct生成的响应组成。通过监督微调(SFT)在qwen2-math-base模型上进行训练,取得了与qwen2-math-instruct相当的性能。
This dataset contains approximately 900,000 mathematical problems, where each problem's solution is formatted using the Chain of Thought (CoT) paradigm. The dataset is sourced from Metamath-QA and NuminaMath-CoT, with only non-synthetic data utilized. During the dataset construction, Qwen2-math-72-instruct and rejection sampling techniques were adopted, and solutions were screened against the official evaluation codebase. Additionally, the dataset incorporates the non-synthetic subset of NuminaMath-CoT, which comprises responses generated by Qwen2-math-72-instruct. Training the qwen2-math-base model via Supervised Fine-Tuning (SFT) yielded performance comparable to that of qwen2-math-instruct.
创建时间:
2024-08-19
原始信息汇总
数据集概述
数据集总结
该数据集包含约90万道数学题目,每道题目的解答以思维链(Chain of Thought, CoT)方式格式化。数据来源包括metamath-qa(https://huggingface.co/datasets/meta-math/MetaMathQA)和NuminaMath-CoT(https://huggingface.co/datasets/AI-MO/NuminaMath-CoT),仅使用非合成数据。我们仅从metamath-qa中提取提示,并使用Qwen2-math-72-instruct和拒绝采样生成响应,解答基于官方评估代码库(https://github.com/QwenLM/Qwen2-Math)进行筛选。对于NuminaMath-CoT,我们仅采用非合成数据集,包括aops_forum、amc_aime、cn_k12、olympiads、gsm8k和math。我们更新了基于metamath-qa的数据集,并添加了由Qwen2-math-72-instruct生成的numina-cot响应部分,这部分显著提升了基于Qwen2-math-base的sft模型的性能。
数据来源细分
| 来源 | 提示数量 | 样本数量 |
|---|---|---|
| GSM_Rephrased | 59216 | 121800 |
| GSM_SV | 29238 | 60794 |
| GSM_FOBAR | 16480 | 34243 |
| GSM_AnsAug | 7173 | 14733 |
| MATH_Rephrased | 18694 | 88256 |
| MATH_SV | 4386 | 23760 |
| MATH_FOBAR | 4802 | 26073 |
| MATH_AnsAug | 5563 | 26751 |
| 总计 | 145552 | 396410 |
结果
| 模型 | gsm8k | MATH | svamp | asdiv | mawps | carp_en | tabmwp | minerva_math | gaokao2023en | olympiadbench | college_math | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| qwen2-math-7b-instruct | 89.3 | 74.4 | 94.3 | 94.9 | 98.4 | 60.2 | 92.6 | 33.5 | 63.4 | 37.5 | 46.2 | 71.3 |
| qwen2-math-1.5b-instruct | 84.2 | 70.4 | 93.3 | 93.9 | 98.4 | 60.3 | 84.3 | 27.6 | 59.5 | 32.3 | 44.6 | 68.1 |
| qwen2-math-7b-sft | 90.4 | 73.3 | 91.1 | 94.6 | 97.1 | 57.1 | 90.8 | 29.0 | 60.5 | 34.4 | 43.2 | 69.2 |
| qwen2-math-7b-sft-with-numina-verified | 90.2 | 74.9 | 92.2 | 94.3 | 97.8 | 60.6 | 92.7 | 33.8 | 63.9 | 35.7 | 45.6 | 71.1 |
| qwen2-math-1.5b-sft | 83.5 | 67.2 | 86.6 | 92.7 | 96.2 | 55.2 | 82.1 | 20.2 | 54.0 | 26.5 | 41.9 | 64.2 |
| 模型 | amc23 | aime24 |
|---|---|---|
| qwen2-math-7b-instruct | 55.0 | 6.7 |
| qwen2-math-1.5b-instruct | 40.0 | 3.3 |
| qwen2-math-7b-sft | 55.0 | 6.7 |
| qwen2-math-7b-sft-with-numina-verified | 50.0 | 13.3 |
| qwen2-math-1.5b-sft | 32.5 | 6.7 |
训练超参数
我们使用huggingface-transformers训练模型,使用8块H800 GPU,以下是实验中使用的超参数:
| 超参数 | 值 |
|---|---|
| learning-rate | 5e-6 |
| num_train_epochs | 3.0 |
| per_device_train_batch_size | 2 |
| gradient_accumulation_steps | 16 |
| numbers_of_gpus | 8 |
| model_max_length | 4096 |
| weight_decay | 0.0 |
| warmup_ratio | 0.03 |
| lr_scheduler_type | linear |
AI搜集汇总
数据集介绍
构建方式
metamath-qwen2-math数据集构建于约90万道数学问题之上,每道问题的解答均以思维链(Chain of Thought, CoT)的形式呈现。数据来源主要包括metamath-qa和NuminaMath-CoT,其中仅采用非合成数据集。通过Qwen2-math-72-instruct模型生成响应,并结合拒绝采样技术进行筛选,确保解答质量。NuminaMath-CoT部分则涵盖了aops_forum、amc_aime、cn_k12、olympiads、gsm8k和math等非合成数据。数据集进一步通过Qwen2-math-72-instruct生成响应,显著提升了基于Qwen2-math-base的监督微调模型性能。
特点
该数据集的特点在于其广泛覆盖了多种数学问题类型,包括GSM8K、MATH、SVAMP等,且每道问题的解答均以思维链形式呈现,便于模型理解和推理。数据集还通过Qwen2-math-72-instruct生成响应,确保了解答的高质量和多样性。此外,数据集的非合成部分经过严格筛选,确保了数据的真实性和可靠性。通过监督微调,该数据集在多个数学任务上表现出色,与官方模型性能接近。
使用方法
metamath-qwen2-math数据集主要用于数学问题求解模型的监督微调。用户可通过Hugging Face平台下载数据集,并结合Qwen2-math-base模型进行训练。训练过程中,建议使用与官方模型相同的超参数设置,如学习率为5e-6,训练轮数为3.0等。数据集中的numina_cot_qwen2.verified.jsonl文件需进行过滤,以去除空解答的提示。通过该数据集训练的模型在GSM8K、MATH等数学任务上表现出色,用户可根据需求进一步优化模型性能。
背景与挑战
背景概述
metamath-qwen2-math数据集是一个专注于数学问题求解的大规模数据集,包含了约90万道数学问题及其链式思维(Chain of Thought, CoT)格式的解答。该数据集由多个来源整合而成,包括MetaMathQA和NuminaMath-CoT等非合成数据集,并通过Qwen2-math-72-instruct模型生成解答。数据集的主要目标是通过监督微调(SFT)提升数学问题求解模型的性能,特别是在复杂数学推理任务中的表现。该数据集的构建和发布由QwenLM团队主导,旨在推动数学推理领域的研究与应用。通过该数据集训练的模型在多个数学基准测试中表现优异,展示了其在数学问题求解领域的潜力。
当前挑战
metamath-qwen2-math数据集在构建和应用过程中面临多重挑战。首先,数学问题的多样性和复杂性要求解答生成模型具备高度的推理能力,尤其是在链式思维格式的解答生成中,模型需要准确捕捉问题的逻辑结构。其次,数据集的构建依赖于多个来源的非合成数据,如何有效整合和筛选这些数据以确保其质量和一致性是一个重要挑战。此外,尽管通过监督微调(SFT)取得了显著进展,但与使用GRPO等强化学习方法的模型相比,性能差距仍然存在,这需要通过进一步的优化策略(如DPO/PPO等)来缩小。最后,数据集中包含的证明部分(PROOFs)需要额外的过滤和处理,以确保解答的完整性和准确性。
常用场景
经典使用场景
在数学问题求解领域,metamath-qwen2-math数据集被广泛应用于训练和评估数学问题解答模型。该数据集包含了约90万道数学问题,每个问题的解答均以思维链(Chain of Thought, CoT)的形式呈现,这使得模型能够模拟人类的解题过程,逐步推导出答案。通过这种方式,模型不仅能够提高解题的准确性,还能增强其解释能力,使得解答过程更加透明和可理解。
解决学术问题
metamath-qwen2-math数据集解决了数学问题求解模型在复杂问题上的表现不足的问题。通过提供大量经过精心设计的数学问题和详细的解答过程,该数据集帮助研究者训练出能够处理从基础到高级数学问题的模型。此外,数据集的多样性和广泛性使得模型能够在不同的数学领域,如代数、几何、概率等,展现出优异的性能,从而推动了数学教育和技术的发展。
衍生相关工作
基于metamath-qwen2-math数据集,研究者们已经开发了多个先进的数学问题解答模型,如qwen2-math-7b-instruct和qwen2-math-1.5b-instruct。这些模型在多个数学竞赛和评估基准上取得了优异的成绩,如GSM8K、MATH和AMC等。此外,这些模型的研究和应用还推动了数学问题求解技术的发展,为未来的教育技术和人工智能研究提供了宝贵的资源和参考。
以上内容由AI搜集并总结生成


