opencs2_dataset_wds
收藏Hugging Face2026-05-09 更新2026-05-10 收录
下载链接:
https://huggingface.co/datasets/blanchon/opencs2_dataset_wds
下载链接
链接失效反馈官方服务:
资源简介:
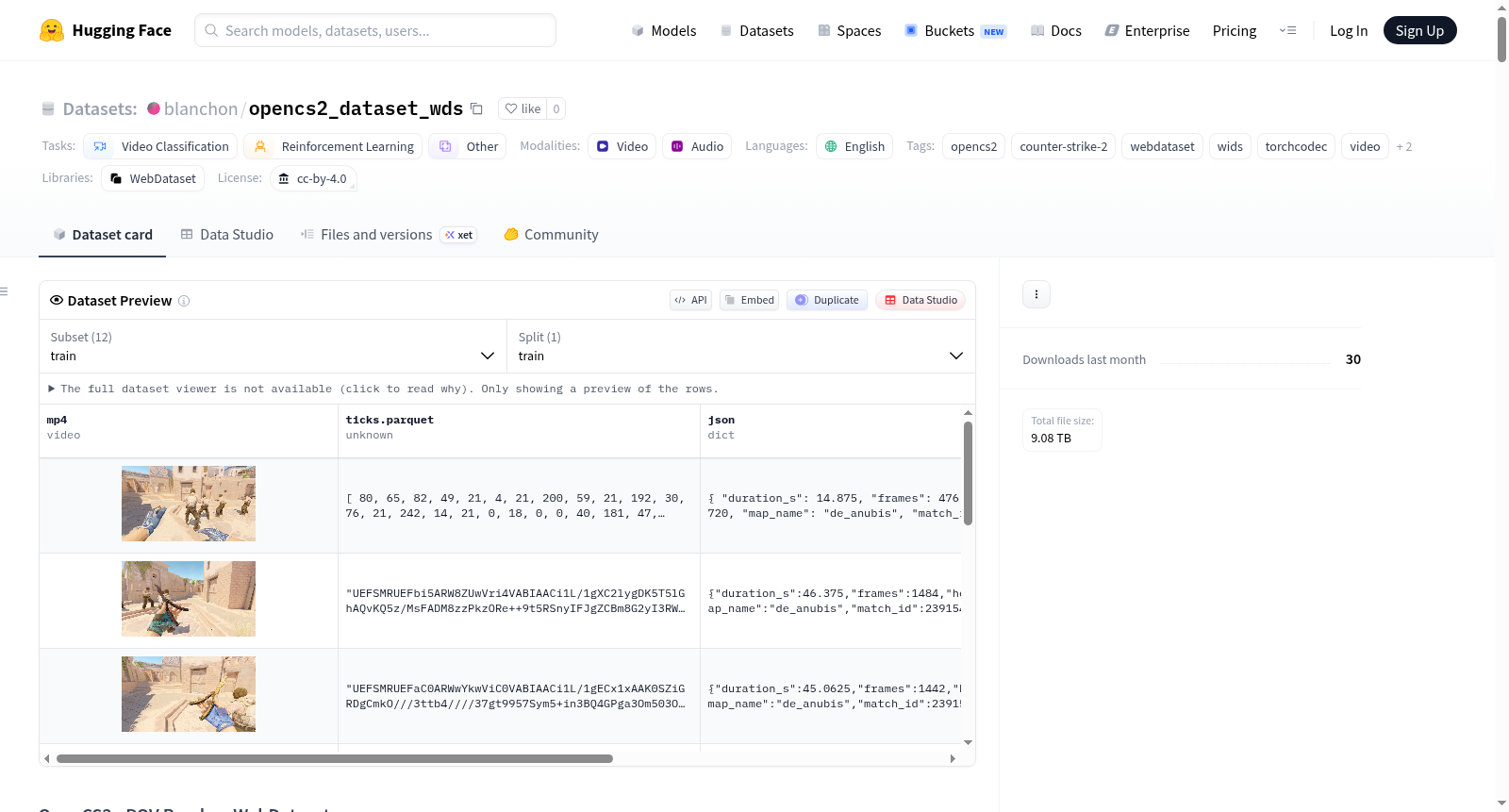
OpenCS2 WebDataset是一个用于训练的数据集,采用WebDataset格式打包。数据集包含多个配置项,分别对应不同的数据文件和用途。主要数据文件包括:1. `shards/*.train.tar`:每个POV round包含一个MP4文件、一个`ticks.parquet`文件和一个JSON sidecar文件;2. `index/wds_samples.parquet`:记录MP4和ticks数据的tar字节偏移量;3. `ticks/**/*.parquet`:提供快速过滤的tick数据,独立于tar文件。数据集当前包含169,960个POV样本,分布在2,711个shards中,适用于需要处理视频和时序数据的机器学习任务。
OpenCS2 WebDataset is a training dataset packaged in WebDataset format. The dataset includes multiple configurations corresponding to different data files and purposes. Main data files include: 1. `shards/*.train.tar`: each POV round contains an MP4 file, a `ticks.parquet` file, and a JSON sidecar file; 2. `index/wds_samples.parquet`: records the tar byte offsets for MP4 and ticks data; 3. `ticks/**/*.parquet`: provides fast-filtered tick data independent of tar files. The dataset currently contains 169,960 POV samples distributed across 2,711 shards, suitable for machine learning tasks involving video and time-series data processing.
创建时间:
2026-05-09
原始信息汇总
根据您提供的数据集详情页面,以下是该数据集的概述:
数据集名称
OpenCS2 WebDataset
数据集详情页地址
https://huggingface.co/datasets/blanchon/opencs2_dataset_wds
数据集配置与文件结构
该数据集包含四个配置,每个配置对应不同的数据文件:
| 配置名称 | 分割 | 文件路径 | 说明 |
|---|---|---|---|
train |
train | shards/*.train.tar |
每个POV轮次包含一个MP4视频文件、一个ticks.parquet文件和一个JSON侧车文件 |
wds_index |
train | index/wds_samples.parquet |
记录MP4和ticks数据在tar包中的字节偏移量 |
pov_rounds |
train | index/pov_rounds.parquet |
存储POV轮次的相关索引信息 |
ticks |
train | ticks/**/*.parquet |
将ticks数据镜像到tar分片之外,便于在访问媒体文件前进行快速过滤 |
当前索引构建情况
- 总计 169,960 个 POV样本
- 分布在 2,711 个 分片(shards)中
搜集汇总
数据集介绍
构建方式
OpenCS2 WebDataset基于blanchon/opencs2_dataset进行封装,采用WebDataset格式组织数据。数据集的构建以POV回合为基本单元,每个回合的样本被存储为独立的tar归档文件,其中包含一个MP4视频文件、一个ticks.parquet时间序列数据文件以及一个JSON元数据文件。所有tar文件按分片(shard)分布,共计2,711个分片,涵盖169,960个POV样本。此外,为支持高效数据过滤与索引,数据集还构建了索引文件,包括wds_samples.parquet记录tar文件内的字节偏移量,以及ticks目录下的独立parquet文件镜像了时间戳数据。
特点
该数据集的一大特色在于其多层次的数据组织方式,将视频、时间序列与元数据紧密耦合于同一归档中,便于流式加载与分布式训练。索引文件的引入使得用户可在不读取完整视频的情况下,基于时间戳信息快速筛选符合条件的数据样本,显著提升数据预处理效率。同时,分片(shard)策略兼顾了存储均衡与并行读取需求,适用于大规模多模态模型的训练场景。数据集的构建体现了对视频-时间序列联合建模任务的深度适配。
使用方法
使用该数据集时,可通过WebDataset库加载shards目录下的tar分片,每个样本自动包含MP4、ticks.parquet与JSON文件。用户若需根据时间戳进行条件过滤,可优先加载ticks目录下的镜像parquet文件,进行快速筛选后,再通过wds_samples.parquet索引定位到对应tar分片中的具体字节偏移,从而高效读取目标媒体数据。数据集提供train、wds_index、pov_rounds和ticks四个配置,分别对应训练数据、索引数据、POV回合信息与时间戳数据,用户可根据任务需求灵活选用相应配置进行数据加载。
背景与挑战
背景概述
OpenCS2 WebDataset(opencs2_dataset_wds)是由研究机构或团队针对自动驾驶或机器人领域中的感知与控制任务所构建的大规模数据集,其创建时间可追溯至近年。该数据集的核心研究问题在于如何高效存储和索引高保真的第一人称视角(POV)视频与时间序列传感器数据,以支持多模态学习与闭环仿真验证。通过将MP4视频、tick数据(如车辆状态、环境感知信息)及JSON侧车文件打包为WebDataset格式,数据集显著提升了训练数据的加载效率与可扩展性。在自动驾驶、具身智能等领域,OpenCS2以其标准化的数据组织形式和丰富的场景覆盖,为模型泛化能力评估提供了关键基准,推动了端到端驾驶策略与多任务学习研究的进展,并已在相关学术社区中产生广泛影响。
当前挑战
该数据集所面临的挑战首先体现在领域问题中:自动驾驶场景的复杂性与长尾分布导致模型难以适应极端天气、遮挡物或罕见交通事件,而OpenCS2需通过覆盖多样化的POV样本(包括城市、乡村与高速场景)来缓解数据偏差。在构建过程中,挑战则集中于数据格式的异构性与大规模存储效率:需将169,960个POV样本的MP4视频、高采样率tick数据及元数据同步封装为2,711个tar分片,确保无帧丢失或时间戳错位;同时,为支持快速过滤与随机访问,需维护parquet格式的索引文件(如ticks目录下数据)以剔除无关样本,避免在训练前解包整个tar包,这对数据管道的内存管理与IO优化提出了严苛要求。
常用场景
经典使用场景
OpenCS2 WebDataset是一个专门为计算机视觉与具身智能研究设计的大规模多模态数据集。其最经典的使用场景在于为机器人操作技能学习提供训练数据,尤其是那些需要结合视觉感知与状态估计的复杂任务。数据集中每一条样本都包含一个完整的POV(第一人称视角)回合,涵盖同步的MP4视频流、高频率的传感器刻度(ticks)数据以及详尽的JSON侧边信息,这使得研究者能够直接利用该数据集训练端到端的行为克隆模型或构建强化学习的仿真环境。通过将数百万个POV样本组织成WebDataset格式,OpenCS2极大地方便了大规模分布式训练中的数据加载与混洗,成为具身智能领域基准评测中不可或缺的数据基石。
解决学术问题
该数据集精准回应了具身智能领域长期存在的两大核心挑战:真实世界机器人数据的高成本采集与多模态信息对齐的复杂性。在传统研究中,获取大量带有精确时间戳和状态标注的机器人演示数据往往需要昂贵的硬件与人工干预,而OpenCS2通过标准化的POV回合结构,将视觉、触觉、关节角度等多源信息天然对齐在同一时间轴上,解决了多模态特征融合中的同步难题。此外,数据集的索引系统允许研究者在不解压全部数据的前提下快速筛选特定类型样本,极大地降低了大规模多模态数据的管理开销。这些特性使得OpenCS2成为推动模仿学习、自监督预训练以及跨场景泛化研究的关键资源,其公开发布填补了开源社区在细粒度机器人操作数据集方面的空白,加速了具身智能从实验室走向真实环境的进程。
衍生相关工作
基于OpenCS2数据集,学术界已涌现出一系列影响深远的研究工作。在模型架构方面,研究者利用其多模态对齐特性,提出了能够联合编码视频流与刻度信号的时序Transformer,显著提升了长序列操作预测的准确性。在预训练框架领域,相关工作通过在大规模POV样本上进行掩码自编码,学习到了具有强迁移能力的视觉表征,这类模型在下游灵巧操作任务中展现出了显著的性能优势。此外,数据集中标准化的索引格式直接催生了多个面向具身智能的高速数据加载库,这些工具将训练吞吐量提升了数倍,并成为许多高影响力论文实验流程的标准组件。值得一提的是,OpenCS2的shard组织方式也被后续的机器人数据集(如RH20T、DROID)广泛采用,成为行业数据发布的事实标准之一。
以上内容由遇见数据集搜集并总结生成


