kth8/gpt-oss-20b-Health_Benchmarks-benchmark
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/kth8/gpt-oss-20b-Health_Benchmarks-benchmark
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
language:
- en
base_model: openai/gpt-oss-20b
datasets:
- yesilhealth/Health_Benchmarks
---
Benchmark of [openai/gpt-oss-20b](https://huggingface.co/openai/gpt-oss-20b) against [yesilhealth/Health_Benchmarks](https://huggingface.co/datasets/yesilhealth/Health_Benchmarks) dataset.
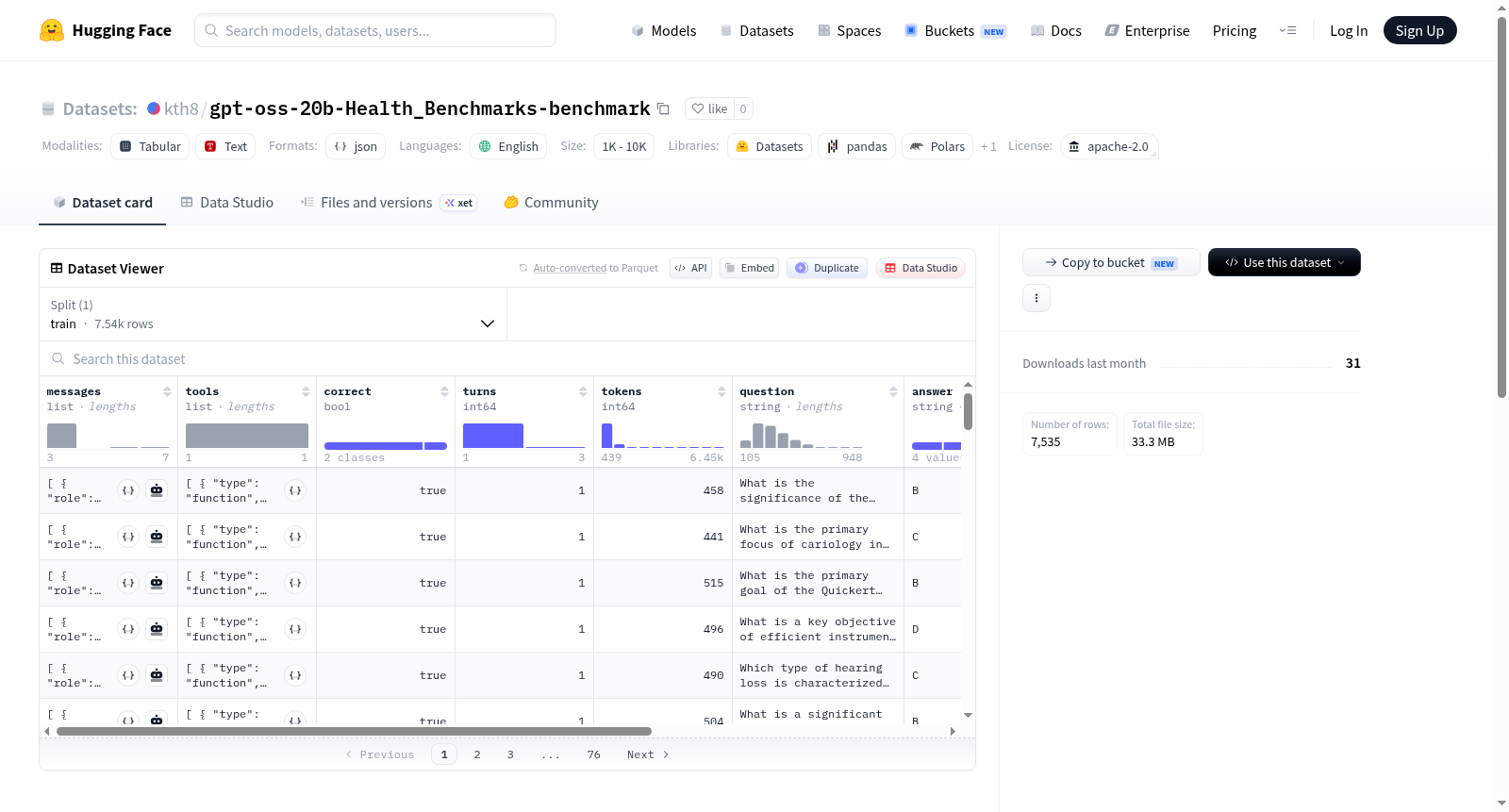
Accuracy: 80.4%.
| Metric | Value |
|----------------------|---------------|
| **Correct** | 6060 |
| **Incorrect** | 1475 |
| **Errors** | 0 |
| **Total samples** | 7535 |
| **Total completion tokens** | 2,940,179 |
Raw stats:
```json
{
"accuracy": 0.804,
"correct": 6060,
"incorrect": 1475,
"error": 0,
"total": 7535,
"completion_tokens": 2940179
}
```
提供机构:
kth8
搜集汇总
数据集介绍
构建方式
该数据集基于开源通用大语言模型openai/gpt-oss-20b,针对医疗健康领域的专用基准评测集合yesilhealth/Health_Benchmarks进行性能评估而构建。评测过程通过将模型应用于基准数据集中的全部7535个样本,记录模型输出的正确性、错误率及生成令牌数,最终统计得出80.4%的总体准确率。构建方式体现了对通用模型在专业领域适用性的系统性验证。
特点
数据集的核心特点在于提供了对gpt-oss-20b模型在健康基准测试中的量化表现记录,包含精确的正确与错误样本计数、零错误率以及生成令牌总量等关键指标。评测数据覆盖完整样本集,无缺失或异常样本,确保了统计结果的可靠性。准确率与令牌消耗的同步呈现,使得模型的效能与资源消耗可被综合评估。
使用方法
数据集可直接用于复现gpt-oss-20b在健康基准上的评测结果,或作为参考基准与其他模型在相同任务上的表现进行对比分析。研究者可依据提供的分类统计(正确/错误/错误类型)深入分析模型在特定医学子领域的能力短板,亦可结合令牌消耗数据优化实际部署中的成本效率。评测流程与数据结构设计简洁,便于集成至自动化模型评估管道中。
背景与挑战
背景概述
该数据集由Yesil Health团队于近期创建,旨在评估开源语言模型在医疗健康领域的基准表现。以OpenAI的gpt-oss-20b模型为基线,针对Health_Benchmarks数据集进行系统性测评,核心研究问题聚焦于验证开源模型在专业医学问答任务中的准确性与可靠性。该数据集整合了7535个样本,覆盖多类健康主题,其发布为医疗AI的标准化评估提供了重要参照,推动了开源模型在临床辅助决策等敏感应用中的可信度研究,对促进医疗大模型的开放科学与可复现性具有里程碑意义。
当前挑战
当前该数据集面临的核心挑战包括:1)医疗领域特有的知识壁垒——模型需应对专业术语、跨模态诊断逻辑及伦理合规性,而gpt-oss-20b仅达到80.4%的准确率,距离临床部署的严苛阈值尚有差距;2)构建过程中样本平衡难题——健康问题分布天然不均衡,罕见病症与常见症状的样本比例需精心设计以避免评估偏差,且人工标注成本高昂,需兼顾专家知识与自动化标注的协同;3)语言与地域泛化挑战——当前仅覆盖英文环境,向多语言、多文化医疗场景迁移时,数据集的结构与语义适配仍需系统性迭代。
常用场景
经典使用场景
在医疗人工智能领域,评估大型语言模型(LLM)在临床知识问答、医学推理和诊断建议生成等任务中的表现,是验证其实际效用的关键步骤。gpt-oss-20b-Health_Benchmarks-benchmark数据集融合了开源LLM与专业健康基准测试,主要用于对模型在医疗场景下的准确性进行系统性评测。该数据集包含数千条医学问答样本,覆盖诊断、治疗及预后判断等多维度内容,通过计算模型输出的准确性(如本研究中的80.4%),为开发者提供量化反馈,以衡量模型处理的可靠程度。其经典用法是通过标准化的问题-答案对,激发模型的医学推理能力,从而揭示其在真实临床知识检索与逻辑判断中的优势与短板,成为推动LLM医学应用研究的基石性工具。
实际应用
在实际应用中,这一基准测试的结果直接影响着医疗AI产品的落地与部署。互联网医疗平台可利用该数据集筛选出最适合辅助医生进行初步病情分析的模型,例如将其整合至智能问诊系统中,用于生成鉴别诊断的建议。医疗教育机构也能借此评估AI助教在医学知识答疑中的准确性,从而在虚拟教学中为学生提供可靠反馈。此外,药企和医疗设备公司能够基于基准测试成绩,选择最具潜力的模型用于药物副作用分析或病历摘要生成,确保在合规与安全的前提下提升临床工作流的效率,最终将抽象的语言模型能力转化为触手可及的医疗辅助工具。
衍生相关工作
该数据集的发布催生了多个方向的开创性后续工作。最直接的衍生研究是以gpt-oss-20b为基线,通过指令微调、检索增强生成或领域强化学习等技术,构建针对医疗场景的专用模型,并在此基准上验证改进成效。另一经典延展是跨模型比较研究,各国团队采用同样的Health_Benchmarks考题,评估如Llama、Mistral及闭源模型在医学推理上的相对强弱,绘制出模型间的能力图谱。此外,该基准的细粒度统计(如正确/错误/错误类型)激发了关于模型置信度校准与错误模式分析的工作,推动开发更鲁棒的医疗问答系统,并促使学术界围绕数据偏倚与评测公平性展开深入讨论,形成良性学术生态。
以上内容由遇见数据集搜集并总结生成


