egyptian-arabic-fake-reviews
收藏Hugging Face2025-05-09 更新2025-05-10 收录
下载链接:
https://huggingface.co/datasets/IbrahimAmin/egyptian-arabic-fake-reviews
下载链接
链接失效反馈官方服务:
资源简介:
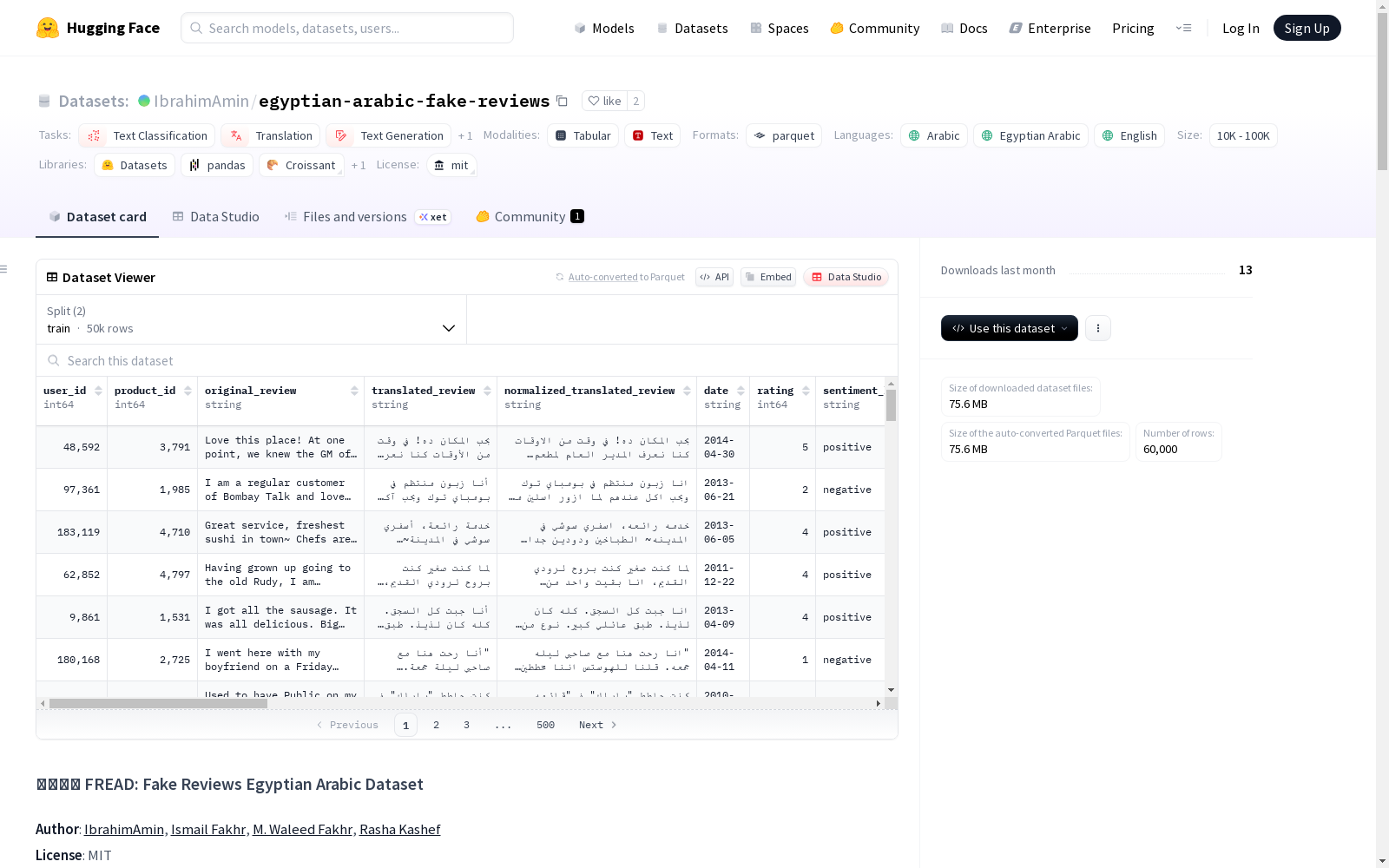
FREAD(假评论埃及阿拉伯语数据集)是一个专门用于检测阿拉伯语(埃及方言)假评论的数据集,包含60000条从YelpZip数据集翻译成埃及阿拉伯语的评论。该数据集是首个包含丰富用户行为元数据字段的大规模方言阿拉伯假评论数据集,适用于训练假评论检测模型等多种用途。
FREAD (Fake Review Egyptian Arabic Dataset) is a specialized dataset dedicated to detecting fake reviews in Egyptian Arabic dialect. It contains 60,000 reviews translated into Egyptian Arabic from the YelpZip dataset. As the first large-scale dialectal Arabic fake review dataset with rich user behavior metadata fields, it supports multiple use cases including training fake review detection models.
创建时间:
2025-05-02
搜集汇总
数据集介绍
构建方式
在阿拉伯语虚假评论检测领域,FREAD数据集通过创新性的跨语言转换方法构建而成。该数据集以YelpZip英文评论为原始素材,运用OpenAI GPT-4o模型进行精准的埃及方言阿拉伯语翻译,并通过系统提示词严格控制输出质量,确保生成符合埃及口语习惯的文本表达。最终形成的六万条语料经过严格的文本归一化处理,构建出首个融合文本内容与多维行为元数据的大规模阿拉伯语虚假评论数据集。
特点
该数据集最显著的特征在于其多维度的元数据架构,不仅包含经过标准化的埃及方言阿拉伯语文本,还整合了用户行为模式、产品属性特征及时间动态等十六类结构化特征。通过引入情感分析得分、信息熵指标和时序行为特征,数据集实现了文本内容与行为特征的深度融合。这种多模态特征组合为研究者提供了从语言学特征到行为模式的全方位分析视角,极大拓展了阿拉伯语虚假评论检测的研究维度。
使用方法
在具体应用层面,研究者可通过HuggingFace标准接口直接加载数据集,采用文本与元数据特征联合建模的策略。基准实验表明,将十六维元数据特征通过特殊分隔符与标准化阿拉伯语文本拼接后输入BERT系列模型,可取得最优检测效果。该数据集支持文本分类、情感分析、零样本学习等多种自然语言处理任务,为阿拉伯语虚假评论检测研究提供了标准化的评估基准和丰富的特征组合方案。
背景与挑战
背景概述
随着电子商务平台的蓬勃发展,虚假评论检测已成为自然语言处理领域的关键研究方向。FREAD数据集由Ibrahim Amin等学者于2025年创建,作为首个大规模埃及阿拉伯语方言虚假评论数据集,其核心研究目标在于通过整合文本内容与用户行为元数据,提升阿拉伯语虚假评论检测的准确率。该数据集基于YelpZip英文评论语料,借助GPT-4o模型实现高质量方言翻译,不仅填补了阿拉伯语方言虚假评论数据资源的空白,更为跨语言检测模型与方言自然语言处理研究提供了重要基准。
当前挑战
在虚假评论检测领域,模型需克服语义伪装与行为模式模拟的双重挑战,尤其面对方言语言特性时传统特征提取方法效能显著下降。数据集构建过程中,研究者面临埃及阿拉伯语方言资源稀缺的困境,需通过精心设计的提示工程确保GPT-4o生成纯正方言文本;同时为保持元数据完整性,必须对用户行为时序特征、产品评分偏差等16类异构特征进行标准化处理,这对多模态数据融合与特征对齐提出了严格要求。
常用场景
经典使用场景
在阿拉伯语自然语言处理领域,该数据集为虚假评论检测任务提供了首个大规模埃及方言标注资源。研究者通常将其用于训练基于Transformer的深度学习模型,通过整合评论文本与用户行为元数据构建多模态分类系统。经典实验范式涉及将标准化翻译文本与16维元数据特征拼接后输入预训练语言模型,在测试集上达到86.78%的F1分数,显著超越仅使用文本特征的基线模型。
实际应用
在电子商务与社交媒体监管领域,该数据集支撑的检测模型可部署于阿拉伯语在线平台。实际应用场景包括自动识别电商平台的刷评行为、监测社交媒体恶意营销内容、辅助内容审核系统提升识别准确率。其埃及方言特性特别适用于中东地区数字市场治理,为平台运营者提供符合本地语言习惯的内容风控工具,有效维护在线评价系统的公信力。
衍生相关工作
基于该数据集衍生的经典研究包括多模态阿拉伯语虚假检测框架的构建,如融合CAMeL-Lab预训练模型与元数据特征的混合架构。相关工作进一步拓展至跨语言迁移学习领域,探索将埃及方言检测模型适配至其他阿拉伯语变体的可行性。在方法论层面,催生了针对低资源方言的元数据增强范式,为后续阿拉伯语数字取证研究提供了可复现的基准体系。
以上内容由遇见数据集搜集并总结生成


