DREAM-1K
收藏Hugging Face2024-07-05 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/omni-research/DREAM-1K
下载链接
链接失效反馈资源简介:
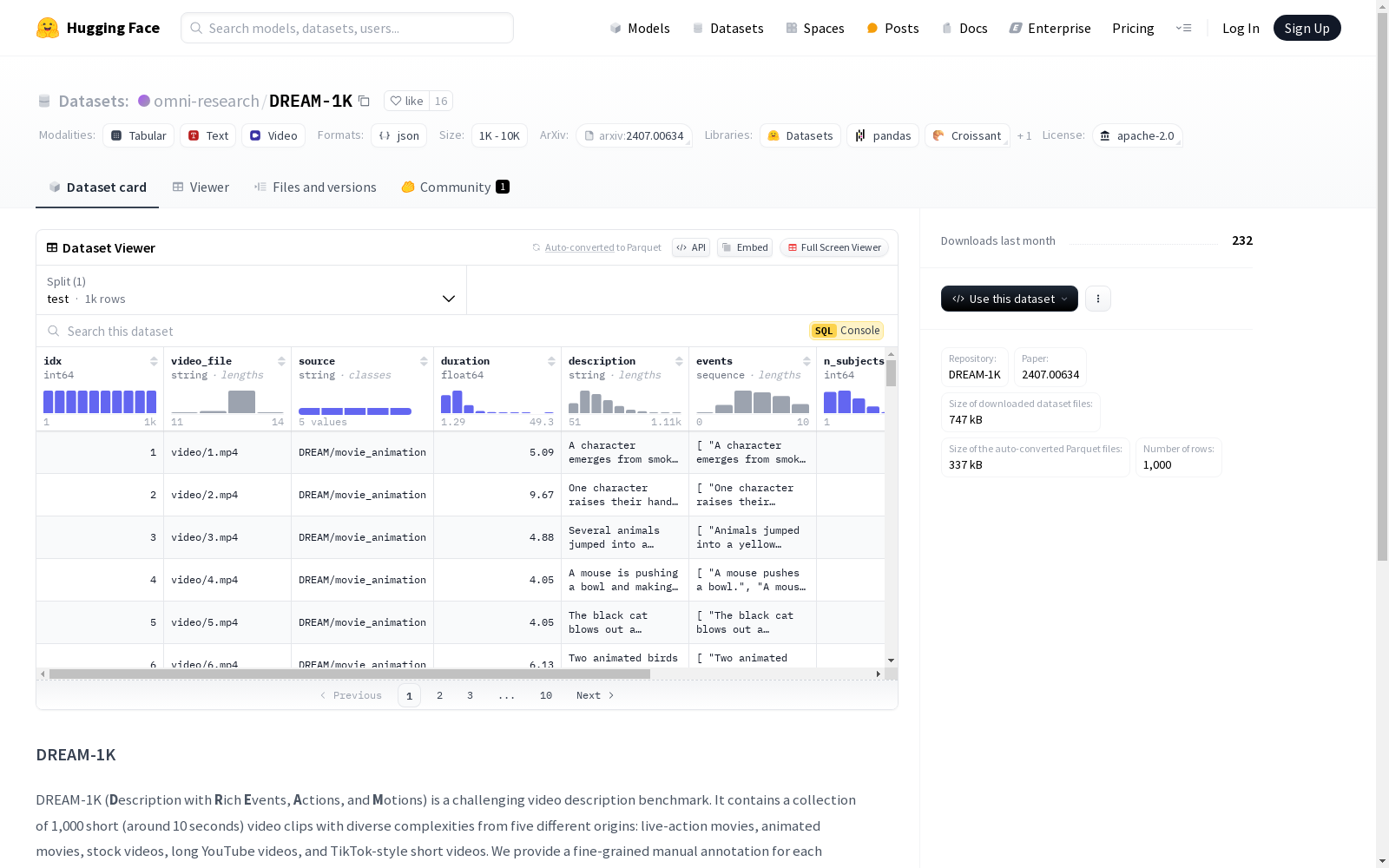
DREAM-1K(描述丰富的事件、动作和情感)是一个具有挑战性的视频描述基准。它包含1,000个短(约10秒)视频片段,具有多样化的复杂性,来自五个不同的来源:实景电影、动画电影、库存视频、长YouTube视频和TikTok风格的短视频。我们为每个视频提供了精细的手动标注。
DREAM-1K (Description-Rich Events, Actions, and Emotions) is a challenging video captioning benchmark. It comprises 1,000 short (≈10-second) video clips with varying levels of complexity, sourced from five distinct categories: live-action films, animated films, stock footage, long YouTube videos, and TikTok-style short videos. We provide fine-grained manual annotations for each video.
创建时间:
2024-07-04
原始信息汇总
DREAM-1K 数据集概述
数据集描述
DREAM-1K(Description with Rich Events, Actions, and Motions)是一个具有挑战性的视频描述基准数据集。它包含1,000个短(约10秒)视频片段,这些片段来自五个不同的来源:实景电影、动画电影、库存视频、长YouTube视频和TikTok风格的短视频。每个视频都提供了细粒度的手动标注。
数据集信息
配置名称
dream-1k
特征
idx: 字符串类型video_file: 字符串类型source: 字符串类型duration: 字符串类型description: 字符串类型events: 字符串类型n_subjects: 字符串类型n_shots: 字符串类型n_events: 字符串类型
分割
test
大小类别
- 1K < n < 10K
配置
DREAM-1K- 数据文件
split:testpath:json/metadata.json
- 数据文件
AI搜集汇总
数据集介绍
构建方式
DREAM-1K数据集通过精心挑选来自五个不同来源的1000个短视频片段构建而成,这些来源包括实景电影、动画电影、库存视频、长YouTube视频以及TikTok风格的短视频。每个视频片段均经过精细的手动注释,涵盖了丰富的事件、动作和运动描述,确保了数据集的多样性和复杂性。
特点
DREAM-1K数据集的特点在于其视频片段的多样性和复杂性,每个视频片段均包含详细的事件、动作和运动描述。数据集中的视频片段来自五个不同的来源,涵盖了广泛的视觉内容和情境,为视频描述任务提供了丰富的素材。此外,每个视频片段都经过精细的手动注释,确保了数据的高质量和准确性。
使用方法
DREAM-1K数据集主要用于视频描述任务的研究和开发。用户可以通过访问HuggingFace平台获取数据集的元数据文件,该文件包含了每个视频片段的详细信息,如视频文件路径、来源、持续时间、描述、事件、主体数量、镜头数量和事件数量等。在使用数据集时,用户需遵守相关的使用协议,确保数据的合规使用。
背景与挑战
背景概述
DREAM-1K数据集由字节跳动公司于2024年发布,旨在为视频描述任务提供一个具有丰富事件、动作和运动信息的基准测试。该数据集包含1000个时长约10秒的视频片段,涵盖五种不同来源:实景电影、动画电影、素材视频、长YouTube视频和TikTok风格短视频。每个视频片段均经过精细的人工标注,提供了详细的事件、动作和运动描述。DREAM-1K的发布为视频理解领域的研究提供了重要的数据支持,尤其是在多模态学习和视频内容生成方面,推动了相关技术的发展。
当前挑战
DREAM-1K数据集在构建和应用过程中面临多重挑战。首先,视频描述的复杂性要求标注者具备对视频内容的高度理解能力,以确保标注的准确性和一致性。其次,数据来源的多样性使得视频风格、内容和质量差异显著,增加了模型泛化能力的考验。此外,视频版权问题也限制了数据的广泛使用,研究者需严格遵守相关协议。在应用层面,如何有效融合多模态信息(如视觉、文本和时间序列)以生成高质量的视频描述,仍是当前研究的核心难题。
常用场景
经典使用场景
DREAM-1K数据集在视频描述生成领域具有广泛的应用,尤其是在多模态学习和自然语言处理任务中。该数据集通过提供包含丰富事件、动作和运动的视频片段,为研究者提供了一个理想的平台,用于开发和评估视频到文本的生成模型。其多样化的视频来源和精细的手动标注,使得模型能够在复杂场景下进行训练和测试,从而提升其在实际应用中的表现。
解决学术问题
DREAM-1K数据集解决了视频描述生成领域中的多个关键学术问题。首先,它通过提供多样化的视频内容和精细的标注,帮助研究者克服了传统数据集在复杂场景描述上的局限性。其次,该数据集支持多模态学习,促进了视频与文本之间的跨模态理解,推动了视频描述生成模型的性能提升。此外,DREAM-1K还为研究者提供了一个标准化的评估基准,使得不同模型的性能能够进行公平比较。
衍生相关工作
DREAM-1K数据集自发布以来,已经衍生出多项经典研究工作。例如,基于该数据集的视频描述生成模型在多个国际竞赛中取得了优异成绩,推动了该领域的技术进步。此外,研究者们还利用DREAM-1K开发了多种多模态学习算法,进一步提升了视频与文本之间的跨模态理解能力。这些工作不仅丰富了视频描述生成的研究内容,还为相关领域的应用提供了新的思路和方法。
以上内容由AI搜集并总结生成


