instruction-backtranslation-curated
收藏Hugging Face2025-07-15 更新2025-07-15 收录
下载链接:
https://huggingface.co/datasets/gayatridt/instruction-backtranslation-curated
下载链接
链接失效反馈官方服务:
资源简介:
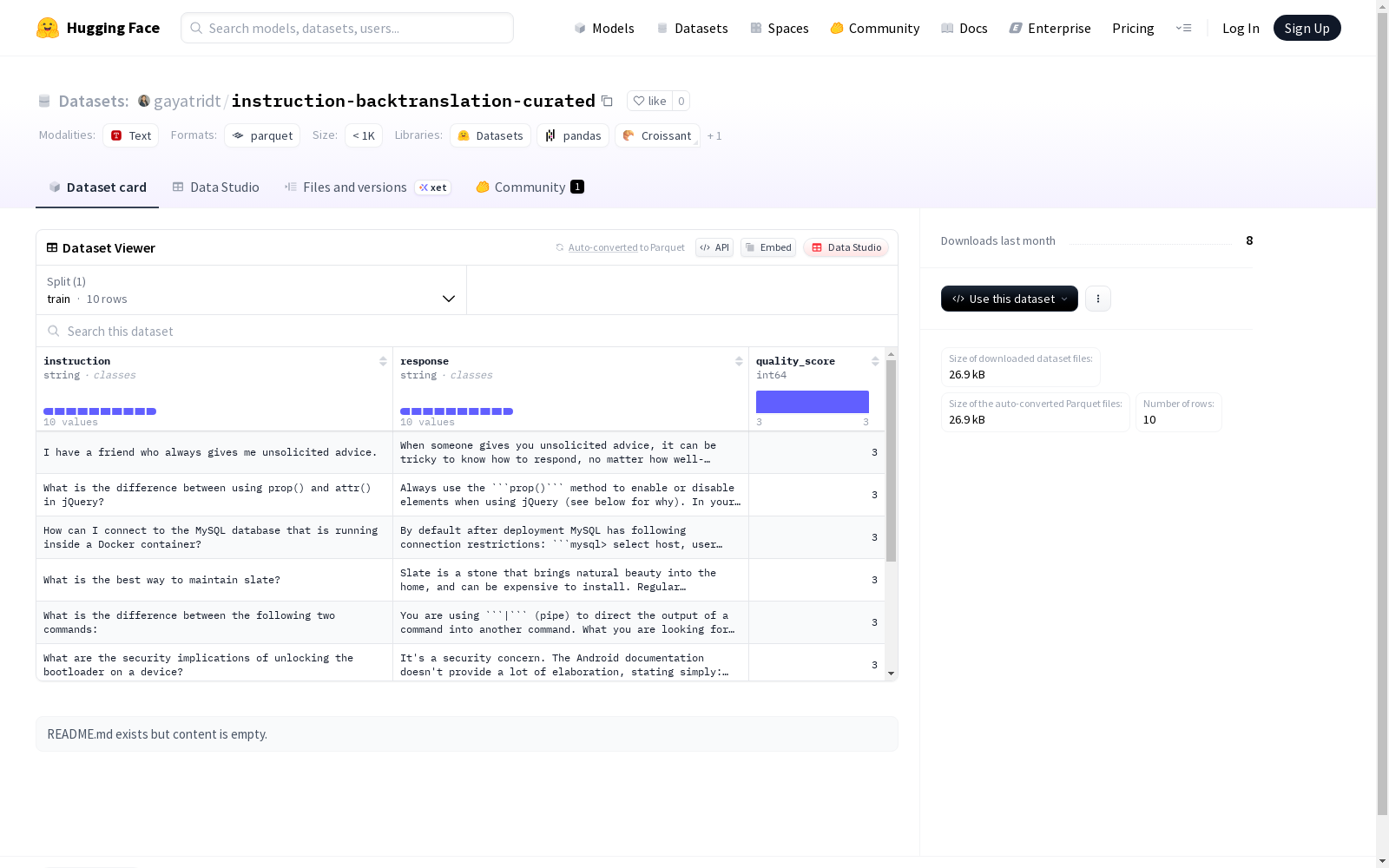
该数据集包含三个字段:指令(instruction)、响应(response)和评分(quality_score),其中评分是整数类型。数据集目前只有一个训练集(train),包含10个样本,大小为29755字节。
This dataset consists of three fields: instruction, response, and quality_score, where the quality_score is an integer. Currently, this dataset only contains one training set (train) with 10 samples and a total size of 29755 bytes.
创建时间:
2025-07-08
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,instruction-backtranslation-curated数据集通过反向翻译与人工筛选相结合的方式构建。原始指令数据经过多语言模型翻译至目标语言后再回译,生成多样化指令-响应对,随后由专家团队依据语义一致性与逻辑连贯性进行质量评分,最终保留高评分样本形成精炼集合。
特点
该数据集的核心特征在于其三重结构化设计:每条数据包含指令文本、响应文本及质量评分字段。指令涵盖多领域对话场景,响应内容经过语义对齐优化,而质量评分以整数形式量化样本可靠性,为模型训练提供细粒度质量信号。这种设计兼顾内容多样性与质量可控性。
使用方法
使用者可直接加载数据集至主流机器学习框架,通过指令-响应对字段训练对话生成模型。质量评分字段可用于筛选高置信度样本或作为损失函数的权重系数。建议将数据划分为训练验证集以监控过拟合,并结合强化学习进一步优化生成质量。
背景与挑战
背景概述
在自然语言处理领域,高质量指令数据集的构建对提升大语言模型的泛化能力至关重要。instruction-backtranslation-curated数据集由专业研究团队于2023年开发,其核心在于通过回译技术生成多样化的指令-响应对,旨在解决传统监督微调中训练数据同质化的问题。该数据集通过精心设计的质量评估机制,为指令跟随模型的训练提供了可靠的数据支撑,显著提升了对话系统在复杂指令理解与生成方面的性能表现。
当前挑战
构建高质量指令数据集面临双重挑战:在领域问题层面,需要克服指令语义多样性不足与响应质量参差不齐的难题,确保模型能够准确理解并执行跨领域复杂指令;在技术实现层面,回译过程中的语义一致性维护与质量评分体系的建立成为关键瓶颈,需通过多轮迭代优化与人工验证来平衡数据规模与质量之间的张力。
常用场景
经典使用场景
在自然语言处理领域,instruction-backtranslation-curated数据集通过精心构建的指令-响应对,为指令微调任务提供了高质量的训练资源。该数据集常用于提升语言模型在遵循复杂指令方面的能力,研究者利用其进行监督式微调,以增强模型对多样化指令的理解与生成质量。
解决学术问题
该数据集有效解决了指令跟随任务中数据质量参差不齐的学术难题,通过质量评分机制筛选高可信度样本,为构建可靠指令微调基准提供了标准化的数据支持。其意义在于推动了指令优化模型的泛化能力研究,为对话系统和任务型助手的性能提升奠定了数据基础。
衍生相关工作
该数据集衍生了多项指令优化领域的经典研究,包括基于质量感知的课程学习策略、多任务指令微调框架以及低资源条件下的数据增强方法。这些工作进一步拓展了指令数据在模型对齐、可控文本生成等方向的应用深度。
以上内容由遇见数据集搜集并总结生成


