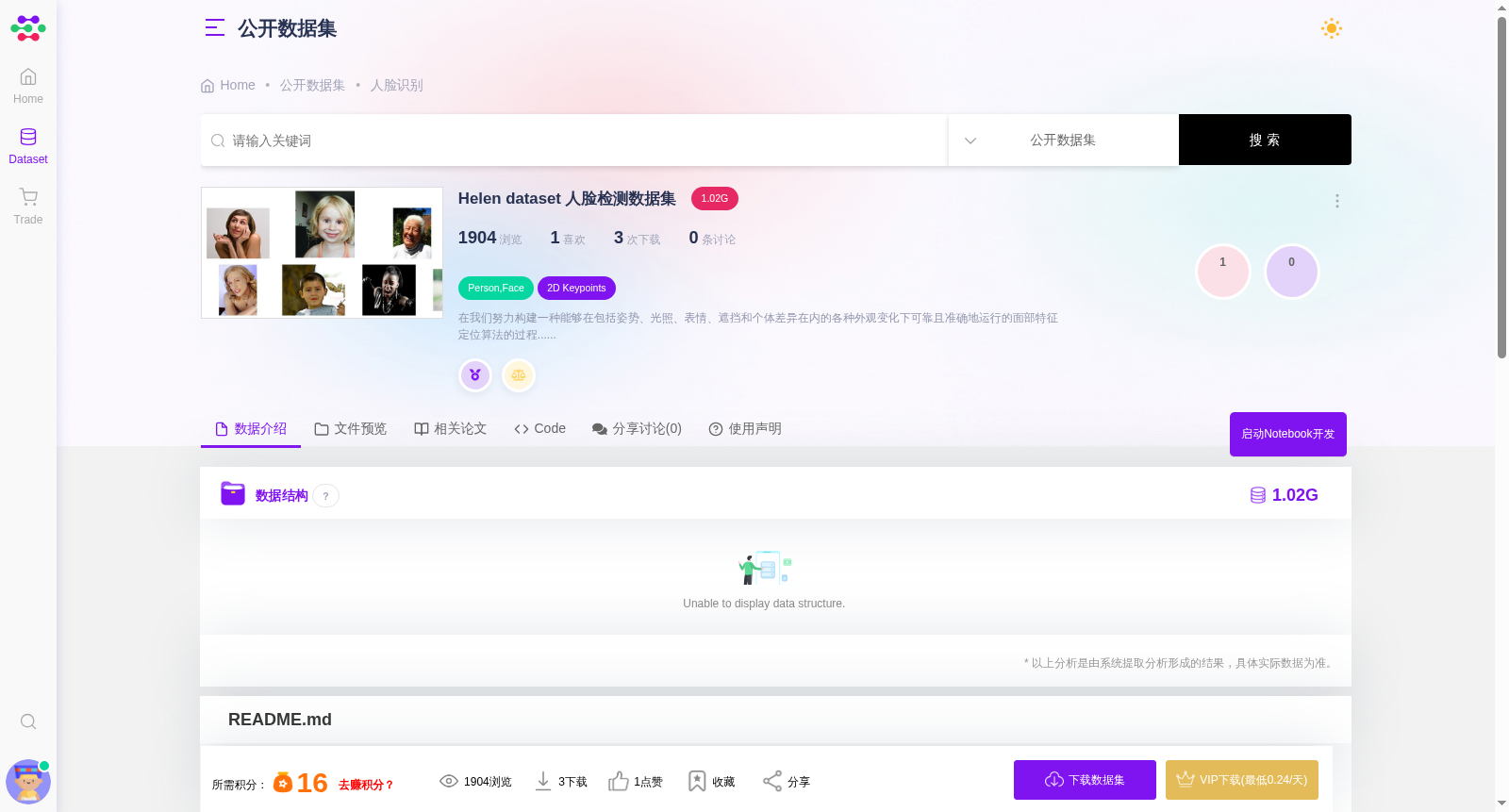
Helen dataset 人脸检测数据集
收藏帕依提提2024-03-04 收录
下载链接:
https://www.payititi.com/opendatasets/show-26564.html
下载链接
链接失效反馈官方服务:
资源简介:
在我们努力构建一种能够在包括姿势、光照、表情、遮挡和个体差异在内的各种外观变化下可靠且准确地运行的面部特征定位算法的过程中,我们意识到训练集必须包含高分辨率示例,以便在测试时可以准确拟合高分辨率测试图像。尽管存在许多人脸数据库,但我们发现没有一个符合我们的要求,尤其是分辨率要求。因此,我们使用带注释的 Flickr 图像构建了一个新数据集。 具体来说,数据集的构建如下:首先,使用 Flickr 上的各种关键字搜索收集了大量候选照片。在所有情况下,查询都包含关键字“portrait”,并增加了不同的术语,例如“family”、“outdoor”、“studio”、“boy”、“wedding”等(试图通过用几种不同的语言重复查询来避免文化偏见。)在生成的候选集上运行人脸检测器,以识别包含足够大人脸(宽度大于 500 像素)的图像子集)。该子集进一步手动过滤以去除误报、个人资料视图以及低质量图像。对于每个接受的人脸,我们生成了原始图像的裁剪版本,其中包括人脸和一定比例的背景。在某些情况下,面部非常靠近或与原始图像的边缘接触,因此不在裁剪图像的中心。此外,裁剪后的图像可以包含其他人脸实例,因为许多照片包含多个近距离的人。 最后,使用 Amazon Mechanical Turk 对图像进行手工注释,以精确定位眼睛、鼻子、嘴巴、眉毛和下巴线。 (我们采用与 PUT 人脸数据库相同的注释约定。)为了协助土耳其工人完成这项任务,我们将点位置初始化为在 PUT 数据库上训练的 STASM 算法的结果。然而,由于 Helen 数据集比 PUT 更加多样化,自动初始化的点通常远离正确的位置。 无论如何,我们发现这个特殊的注释任务需要对数据进行大量的审查和后处理,以确保高质量的结果。最终,这归因于所涉及的大量自由度。例如,土耳其工人经常会置换组件(将眼睛和眉毛或内唇换成外唇),或者充分地移动点的位置以改变它们的角色(例如选择不同的顶点来服务)作为眼角或嘴角)。界面中的图形提示以及培训视频和资格测试被用来协助该过程。此外,还开发了自动化流程来强制数据集中的一致性和统一性。除上述内容外,作者还在组件级别手动审查了这些面孔,以识别注释中的错误。有不可接受错误的组件被重新提交给土耳其人进行更正。 生成的数据集由 2000 个训练图像和 330 个测试图像组成,具有高度准确、详细和一致的主要面部组件注释。 Reference Interactive Facial Feature Localization Vuong Le, Jonathan Brandt, Zhe Lin, Lubomir Boudev, Thomas S. Huang
In our effort to build a facial landmark localization algorithm that can operate reliably and accurately under various appearance variations including pose, illumination, expression, occlusion, and individual differences, we realized that the training set must contain high-resolution examples to enable accurate fitting to high-resolution test images during inference. Although many face databases exist, we found none that meet our requirements, especially the resolution requirement. Therefore, we constructed a new dataset using annotated Flickr images. Specifically, the dataset was built as follows: First, a large number of candidate photos were collected via various keyword searches on Flickr. In all cases, the queries included the keyword "portrait" paired with additional terms such as "family", "outdoor", "studio", "boy", "wedding", etc. (To avoid cultural bias, we repeated the queries in several different languages.) A face detector was run on the generated candidate set to identify a subset of images containing sufficiently large faces (with width greater than 500 pixels). This subset was further manually filtered to remove false positives, profile views, and low-quality images. For each accepted face, we generated cropped versions of the original image that included the face and a proportional amount of background. In some cases, the face was very close to or touching the edges of the original image, so it was not centered in the cropped image. Additionally, the cropped images could contain other face instances, as many photos contain multiple people in close proximity. Finally, the images were manually annotated via Amazon Mechanical Turk to precisely locate the eyes, nose, mouth, eyebrows, and jawline. (We adopted the same annotation conventions as the PUT Face Database.) To assist the Turkers with this task, we initialized the point positions using the results of the STASM algorithm trained on the PUT database. However, since the Helen Dataset is more diverse than the PUT database, the automatically initialized points were often far from the correct positions. Regardless, we found that this particular annotation task required extensive review and post-processing of the data to ensure high-quality results. This was ultimately attributed to the large number of degrees of freedom involved. For example, Turkers often swapped components (replacing eyes and eyebrows with inner or outer lips) or sufficiently shifted the positions of points to alter their roles (e.g., selecting different vertices to serve as eye corners or mouth corners). Graphic prompts within the interface, along with training videos and qualification tests, were used to assist the process. Additionally, automated workflows were developed to enforce consistency and uniformity across the dataset. Beyond the above, the authors manually reviewed these faces at the component level to identify errors in the annotations. Components with unacceptable errors were resubmitted to the Turkers for correction. The resulting dataset consists of 2000 training images and 330 test images, with highly accurate, detailed, and consistent annotations for major facial components. Reference: Interactive Facial Feature Localization, Vuong Le, Jonathan Brandt, Zhe Lin, Lubomir Boudev, Thomas S. Huang
提供机构:
帕依提提
搜集汇总
数据集介绍
背景与挑战
背景概述
Helen dataset是一个高分辨率的人脸检测数据集,包含2330张图像(2000训练,330测试),具有精确的面部特征注释。该数据集特别注重在多种外观变化下的面部特征定位,适用于复杂环境下的人脸识别研究。
以上内容由遇见数据集搜集并总结生成


