zaremba-density
收藏Hugging Face2026-04-07 更新2026-04-08 收录
下载链接:
https://huggingface.co/datasets/cahlen/zaremba-density
下载链接
链接失效反馈官方服务:
资源简介:
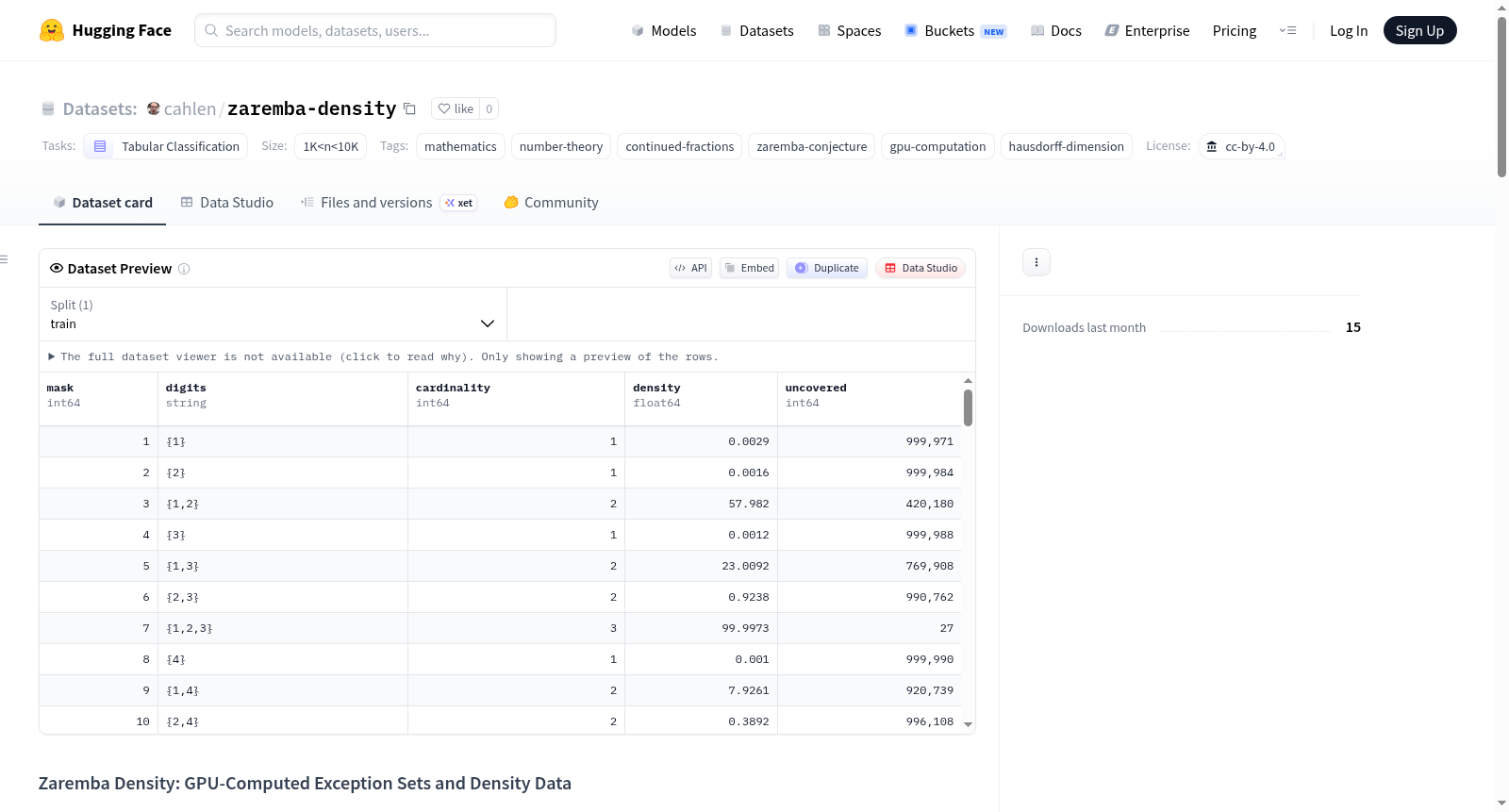
Zaremba密度数据集是一个专注于数论中Zaremba猜想研究的开源数据集,通过GPU计算提供了65种数字集/范围组合的完整密度测量结果。数据集包含三个主要文件:`zaremba_density_all_results.csv`汇总所有实验数据,`density_sweep_1e6.csv`和`density_all_subsets_n10_1e6.csv`提供{1,...,10}所有非空子集在10^6范围内的完整密度扫描,以及`logs/`目录下65个原始GPU日志文件。关键结果包括已验证至10^11的封闭异常集和在10^11处开放的异常集数据,以及{1,2}数字集的对数收敛数据。该数据集适用于数论研究、算法验证和GPU计算性能分析等任务,使用8个NVIDIA B200 GPU(共1.4TB显存)生成,采用自定义CUDA内核实现。数据集遵循CC BY 4.0许可协议。
创建时间:
2026-04-07
原始信息汇总
Zaremba Density: GPU-Computed Exception Sets and Density Data 数据集概述
数据集基本信息
- 许可证: CC BY 4.0
- 任务类别: 表格分类
- 标签: 数学、数论、连分数、Zaremba猜想、GPU计算、豪斯多夫维数
- 规模: 1K<n<10K
- 名称: Zaremba Density: GPU-Computed Exception Sets and Density Data
数据集描述
本数据集是Zaremba密度扫描数据的规范存储库,包含在8x NVIDIA B200集群(1.4 TB VRAM)上计算得出的100多种数字集/范围组合的Zaremba猜想密度测量数据。它是bigcompute.science项目的一部分。
数据集内容
zaremba_density_all_results.csv: 所有已完成实验的摘要,包括数字集、范围、密度、未覆盖计数和运行时间。density_sweep_1e6.csv/density_all_subsets_n10_1e6.csv: 在N=10^6时,对{1,...,10}的所有1,023个非空子集进行的完整密度扫描。logs/: 所有原始GPU日志文件,包含完整输出,包括封闭异常集的未覆盖分母列表。覆盖范围从10^6到10^14。results/: 分析JSON和收集的摘要。
关键结果
封闭异常集(已验证至10^11)
| 数字集 | 异常数 | 已验证至 |
|---|---|---|
| {1,2,3} | 27 | 10^9 (10^11运行中) |
| {1,2,4} | 64 | 10^10 (10^12运行中) |
| {1,2,5} | 374 | 10^11 |
| {1,2,6} | 1,834 | 10^11 |
| {1,2,7} | 7,178 | 10^11 |
在10^11处的开放(增长中)异常集
| 数字集 | 异常数 |
|---|---|
| {1,2,8} | 23,590 |
| {1,2,9} | 77,109 |
| {1,2,10} | 228,514 |
{1,2} 对数收敛
| 范围 | 密度 |
|---|---|
| 10^6 | 61.28% |
| 10^9 | 72.06% |
| 10^10 | 76.55% |
| 10^11 | 80.75% |
| 10^12 | 84.58% |
拟合结果:密度 ~ 31.5 + 4.47 * log10(N)。预测在约10^15处达到100%。
硬件
- 8x NVIDIA B200(每个180 GB,总计约1.4 TB VRAM)
- 使用持久线程和前缀排序工作分配的自定义CUDA内核
复现
bash nvcc -O3 -arch=sm_90 -o zaremba_density_gpu zaremba_density_gpu.cu -lm ./zaremba_density_gpu 100000000000 1,2,3
源代码位于:https://github.com/cahlen/idontknow/tree/main/scripts/experiments/zaremba-density
相关数据集
- cahlen/zaremba-conjecture-data (https://huggingface.co/datasets/cahlen/zaremba-conjecture-data) — 计算证明框架:转移算子、谱隙、表示计数
- cahlen/hausdorff-dimension-spectrum (https://huggingface.co/datasets/cahlen/hausdorff-dimension-spectrum) — 所有2^20-1个子集的dim_H(E_A)
来源
- 代码: https://github.com/cahlen/idontknow/tree/main/scripts/experiments/zaremba-density
- 发现: https://bigcompute.science/findings/zaremba-density-phase-transition/, https://bigcompute.science/findings/zaremba-exception-hierarchy/
- 项目: https://bigcompute.science
引用
bibtex @misc{humphreys2026zaremba_density, author = {Humphreys, Cahlen and Claude (Anthropic)}, title = {Zaremba Density: GPU-Computed Exception Sets and Density Data}, year = {2026}, publisher = {Hugging Face}, url = {https://huggingface.co/datasets/cahlen/zaremba-density} }
人类-AI协作作品(Cahlen Humphreys + Claude)。未经独立同行评审。所有代码和数据开放供验证。CC BY 4.0。
搜集汇总
数据集介绍
构建方式
在数论领域,Zaremba密度数据集通过大规模GPU计算精心构建而成。该数据集依托八块NVIDIA B200显卡组成的计算集群,利用定制化的CUDA内核与持久线程技术,对超过一百种数字集合与范围组合进行了系统性的密度扫描。数据生成过程涵盖了从10^6到10^14的广泛数值范围,通过并行计算高效统计了每个范围内满足Zaremba猜想条件的既约分数比例,并将原始日志、未覆盖分母列表及分析摘要结构化存储,确保了计算过程的透明性与结果的可复现性。
特点
本数据集的核心特征在于其针对Zaremba猜想提供了前所未有的高精度密度测量与例外集合分析。它系统收录了不同数字子集下的密度演化数据,例如集合{1,2}的密度随对数尺度呈现清晰的收敛趋势。尤为突出的是,数据集明确区分了闭合例外集合与开放增长型例外集合,并对诸如{1,2,3}等集合的例外分母进行了高达10^11量级的验证。这些经过GPU验证的密集数据,为研究连分数中部分商分布的规律与相变现象提供了坚实的经验基础。
使用方法
研究人员可利用该数据集深入探究Zaremba猜想及相关数论问题的统计特性。数据集中的CSV文件,如`zaremba_density_all_results.csv`,提供了所有实验的摘要,便于进行跨数字集合的密度比较与趋势分析。`logs`目录下的原始输出则允许用户核查具体的未覆盖分母,从而验证例外集合的构成。结合提供的复现指令与开源代码,学者不仅能直接引用已计算的密度结果,还能扩展计算至新的参数组合,推动对连分数动力系统与丢番图逼近理论的实证研究。
背景与挑战
背景概述
Zaremba密度数据集聚焦于数论领域的Zaremba猜想研究,该猜想涉及连分数部分商的有界性问题。数据集由Cahlen Humphreys与Claude(Anthropic)于2026年合作创建,隶属于bigcompute.science项目,旨在通过大规模GPU计算探索不同数字集合下猜想的密度特性与例外集结构。研究核心在于量化满足猜想的整数比例,并验证例外集的封闭性,其成果为解析数论与动力系统提供了实证基础,推动了计算数学与高性能计算的交叉融合。
当前挑战
该数据集致力于解决Zaremba猜想中密度估计与例外集识别的计算难题,挑战在于连分数表示的组合复杂性随数字集合与整数范围指数级增长,传统算法难以处理高达10^14量级的枚举。构建过程中,需设计高效CUDA内核以管理1.4TB显存,实现工作负载的持久线程与前缀排序分布,同时确保海量日志数据的完整性与可复现性,这对计算架构与数据一致性提出了严峻考验。
常用场景
经典使用场景
在数论与连分数理论的研究中,Zaremba密度数据集为验证Zaremba猜想提供了关键的计算实证。该数据集通过GPU大规模并行计算,系统性地测量了不同数字集合在广泛数值范围内的密度值,尤其聚焦于部分商有界条件下的有理数表示存在性。经典使用场景包括分析数字集合如{1,2,3}至{1,2,10}的例外集结构,以及观测密度随范围N增长的收敛行为,例如{1,2}集合呈现出的对数增长趋势,为理论猜想提供了坚实的数值支撑。
解决学术问题
该数据集直接回应了Zaremba猜想中关于例外集规模与密度渐近行为的核心学术问题。通过精确计算高达10^14范围的密度数据,它揭示了不同数字集合下例外集的封闭性与开放性,例如{1,2,3}至{1,2,7}集合的例外集在特定范围内闭合,而{1,2,8}以上则呈现增长态势。这些结果不仅量化了猜想的成立边界,还促进了连分数动力系统与Hausdorff维数等相关领域的交叉研究,为理解丢番图逼近中的结构性规律提供了重要洞见。
衍生相关工作
围绕该数据集衍生的经典工作主要包括计算证明框架的深化与跨领域拓展。关联数据集如zaremba-conjecture-data进一步提供了转移算子、谱间隙及表示计数的详细数据,构成了猜想验证的完整计算链条。同时,hausdorff-dimension-spectrum数据集则将所有数字子集的Hausdorff维数谱系统化,将密度问题与分形几何理论紧密联结。这些工作共同推动了对Zaremba猜想相变行为与例外层次结构的理论建模,激发了动力系统与解析数论交叉的新研究方向。
以上内容由遇见数据集搜集并总结生成


