Molmo2-VideoPoint
收藏Hugging Face2025-12-16 更新2025-12-17 收录
下载链接:
https://huggingface.co/datasets/allenai/Molmo2-VideoPoint
下载链接
链接失效反馈官方服务:
资源简介:
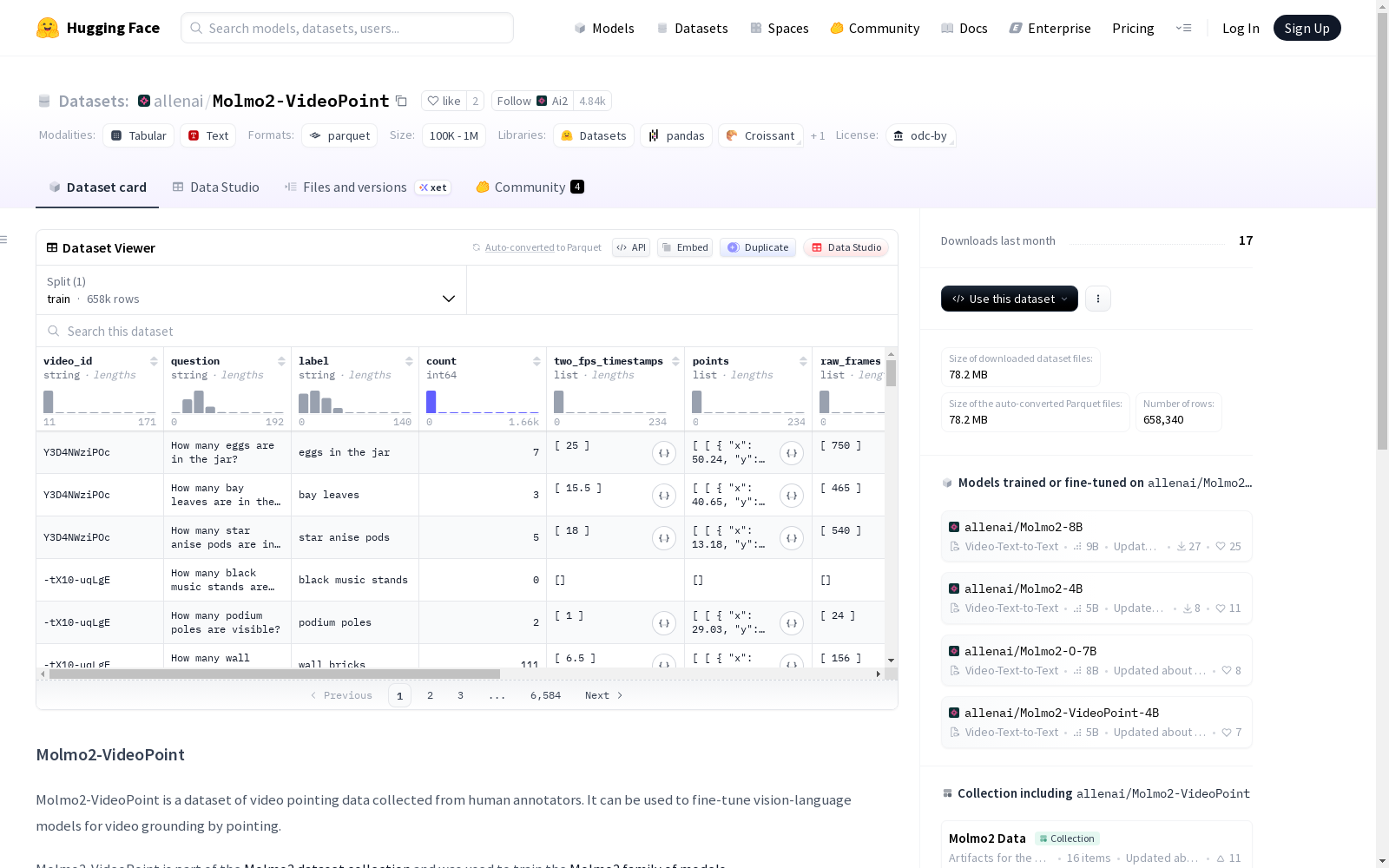
Molmo2-VideoPoint是一个从人类注释者收集的视频指向数据的数据集。它可用于通过指向来微调视觉语言模型以进行视频定位。该数据集是Molmo2数据集集合的一部分,并用于训练Molmo2系列模型。数据集包含多种视频来源(如YouTube、生成视频和MammalNet视频),并提供了重新编码为2FPS的视频注释。每个条目包含2D坐标点列表,对应特定的时间戳。注释者不确定标记用于记录注释者对标注的确定性,模型训练默认仅使用标记为确定的示例。类别列指出了指向查询的类型,包括对象、动作/事件、动物、指代表达、间接引用、空间引用、比较引用和视觉伪影/异常(仅适用于生成视频)。
Molmo2-VideoPoint is a dataset of video pointing data collected from human annotators. It can be used to fine-tune vision-language models for video grounding via pointing. This dataset is part of the Molmo2 dataset collection and is used to train the Molmo2 family of models. The dataset includes multiple video sources (e.g., YouTube, generated videos, and MammalNet videos) and provides video annotations re-encoded at 2FPS. Each entry contains a list of 2D coordinate points corresponding to specific timestamps. The annotator uncertainty tag is used to record the annotators' confidence in their annotations, and by default, only examples marked as certain are used for model training. The category column indicates the type of pointing query, including object, action/event, animal, referential expression, indirect reference, spatial reference, comparative reference, and visual artifacts/abnormalities (only applicable to generated videos).
提供机构:
Allen Institute for AI
创建时间:
2025-12-07
原始信息汇总
Molmo2-VideoPoint 数据集概述
数据集简介
Molmo2-VideoPoint 是一个从人类标注者收集的视频指向数据的数据集。该数据集可用于通过指向微调视觉语言模型以进行视频定位。Molmo2-VideoPoint 是 Molmo2 数据集集合 的一部分,并用于训练 Molmo2 模型系列。
数据集详情
- 许可证: ODC-BY
- 下载大小: 78,226,518 字节
- 数据集大小: 211,519,152 字节
- 训练集样本数: 658,340
数据特征
数据集包含以下字段:
video_id: 字符串类型,视频标识符。question: 字符串类型,问题描述。label: 字符串类型,标签。count: int64 类型,计数。two_fps_timestamps: float64 序列,以 2 帧每秒速率重新编码视频的时间戳。points: 二维坐标列表的列表,其中points[i]对应timestamps[i]的二维点列表,每个点包含x(float64) 和y(float64) 坐标。raw_frames: int64 序列,从原始视频提取的帧。raw_timestamps: float64 序列,从原始视频提取的时间戳。annotator_unsure: 布尔类型,标注者是否对其标注不确定。category: 字符串类型,指向查询的类别。video_duration: float64 类型,视频持续时间。video_source: 字符串类型,视频来源。
数据格式说明
- 视频来源: 共有三种视频来源:
youtube、generated和MammalNet。对于 YouTube 视频,需按其 ID 下载。对于生成的视频,可在generated_videos/文件夹中找到。对于来自 MammalNet 的视频,可按照其 GitHub 仓库中的说明下载。 - 时间戳对比: 所有原始视频均被重新编码为 2FPS,并在 2FPS 视频上进行标注。
raw_frames和raw_timestamps是从原始视频提取的,而two_fps_timestamps用于模型训练。 - 指向点:
points中的每个条目是二维坐标列表的列表,points[i]对应timestamps[i]的二维点列表。 - 标注者不确定标记: 该列记录标注者是否对其标注不确定。在模型训练中,默认仅使用他们标记为确定的示例(即
annotator_unsure==false)。 - 查询类别:
category列表示指向查询的类别,包括物体、动作/事件、动物、指代表达、间接引用、空间引用、比较引用以及视觉伪影/异常(仅针对生成视频)。
许可证与使用
本数据集采用 ODC-BY 许可证。根据 Ai2 的 负责任使用指南,其旨在用于研究和教育目的。本数据集包含由 GPT-4.1 和 GPT-5 生成的问题,这些问题受 OpenAI 的 使用条款 约束。
搜集汇总
数据集介绍
构建方式
Molmo2-VideoPoint数据集的构建过程体现了多源视频与精细化标注的深度融合。该数据集整合了来自YouTube、生成式视频以及MammalNet三个渠道的视频素材,通过人工标注的方式收集视频指向数据。所有原始视频均被重新编码为每秒两帧的格式,并在此基础上进行标注,确保了时间维度的一致性。标注过程中,每个时间戳对应一组二维坐标点,形成时空指向信息,同时记录了标注者的不确定状态及查询类别,为模型训练提供了高质量且结构化的监督信号。
使用方法
使用Molmo2-VideoPoint数据集时,需首先根据视频来源字段获取相应的视频内容:YouTube视频需通过ID下载,生成式视频可直接在指定文件夹中获取,MammalNet视频则需遵循其官方仓库的下载指引。在模型训练阶段,建议默认采用标注者标记为确定的样本,即筛选`annotator_unsure`字段为假的条目,以提升训练数据的可靠性。数据集中的两帧每秒时间戳与对应坐标点可直接用于训练视频指向定位模型,通过将自然语言问题与视频时空位置进行关联,实现精准的视频语义接地任务。
背景与挑战
背景概述
Molmo2-VideoPoint数据集由艾伦人工智能研究所于2024年发布,作为Molmo2系列数据集的重要组成部分,旨在推动视频理解与视觉语言模型的研究。该数据集聚焦于视频指向任务,通过收集人类标注者对视频内容中特定对象、动作或事件的时空指向数据,为核心研究问题——视频时空定位与视觉语言对齐提供了关键支持。其构建基于多源视频素材,包括YouTube、生成式视频及MammalNet生态监测数据,通过精细的二维坐标标注与时间戳对齐,为模型训练提供了高精度监督信号,显著提升了视频理解模型在细粒度推理与交互任务中的性能,对多模态人工智能领域的发展产生了深远影响。
当前挑战
Molmo2-VideoPoint数据集致力于解决视频时空定位这一复杂领域问题,其核心挑战在于如何准确关联自然语言查询与视频中的动态视觉内容,尤其是在处理快速运动、遮挡或多对象交互场景时,模型需克服时空歧义与语义模糊性。在构建过程中,数据集面临标注一致性与规模化的双重挑战:人类标注者需在低帧率(2FPS)视频中精确标注二维指向坐标,同时处理多样化的查询类别(如间接指代、空间参照等),这要求标注协议具备高度的严谨性与可扩展性;此外,整合多源视频(包括生成式内容)并确保时间戳与原始帧的精确对齐,进一步增加了数据清洗与验证的复杂性。
常用场景
经典使用场景
在视频理解与视觉语言模型的研究中,Molmo2-VideoPoint数据集被广泛应用于视频定位任务的微调与评估。该数据集通过人类标注者提供的指向性数据,将自然语言问题与视频中的时空坐标关联起来,为模型学习视频内容与语言描述的对应关系提供了丰富的监督信号。其典型应用场景包括训练模型根据问题在视频帧序列中精准定位目标对象或事件,从而推动视频问答、视频检索等任务的发展。
解决学术问题
Molmo2-VideoPoint数据集有效解决了视频理解领域中细粒度时空定位的学术挑战。它通过大规模标注的指向坐标,为模型提供了明确的监督信息,有助于克服视频内容动态变化、语义模糊以及跨模态对齐困难等问题。该数据集支持对对象、动作、事件、指代表达等多种查询类别的建模,促进了视频基础模型在时空推理能力上的突破,为视频定位技术的理论进展提供了关键数据支撑。
实际应用
在实际应用层面,Molmo2-VideoPoint数据集可赋能智能视频分析系统,例如在安防监控中快速定位异常行为,在教育视频中精确标记教学重点,或在媒体内容管理中实现基于语义的视频片段检索。其指向标注机制使得系统能够理解用户的自然语言指令并反馈视频中的具体位置,提升了人机交互的直观性与效率,为视频编辑、辅助诊断、自动驾驶等领域的智能化应用提供了技术基础。
数据集最近研究
最新研究方向
在视频理解与多模态人工智能领域,Molmo2-VideoPoint数据集以其丰富的视频指向标注数据,正推动着视觉-语言模型在视频时序定位任务中的前沿探索。该数据集整合了来自YouTube、生成式视频及MammalNet的多样化视频源,并提供了精细的二维坐标点序列与时间戳对齐,为模型学习时空语义关联提供了坚实基础。当前研究热点聚焦于利用此类指向数据增强模型对视频中物体、动作、事件及复杂指代表达的细粒度理解能力,特别是在处理间接引用、空间比较等抽象查询时展现潜力。这一方向不仅促进了视频问答与交互式人工智能的发展,也为生成式视频分析及具身智能等新兴应用提供了关键数据支持,在推动多模态模型从静态图像向动态视频理解过渡中具有重要影响。
以上内容由遇见数据集搜集并总结生成


