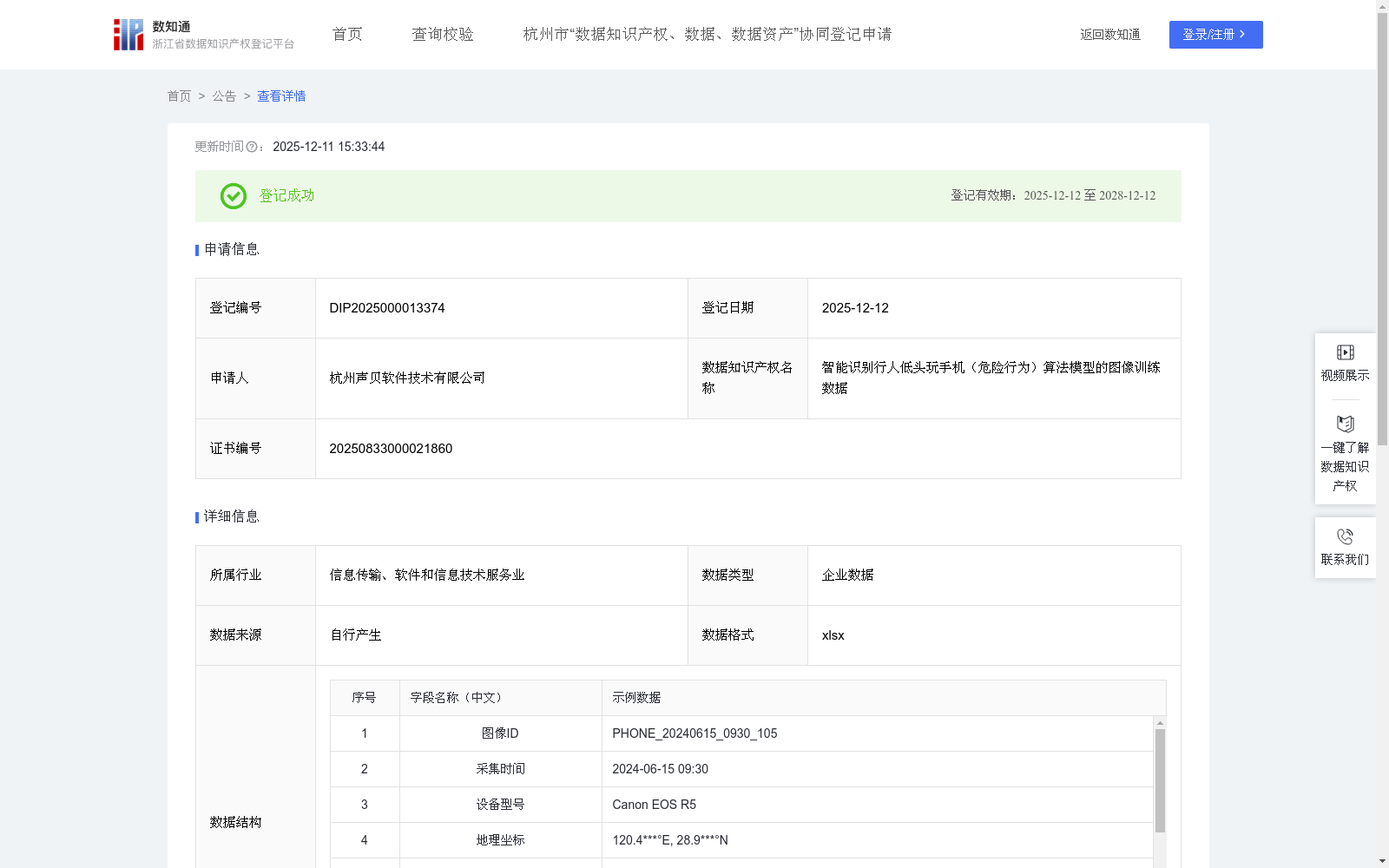
智能识别行人低头玩手机(危险行为)算法模型的图像训练数据
收藏浙江省数据知识产权登记平台2025-12-11 更新2025-12-13 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8412826
下载链接
链接失效反馈官方服务:
资源简介:
本数据集主要用于提升AI模型对行人低头玩手机危险行为的识别能力与精确性。通过对该数据集的训练,使AI模型能够通过图像分析识别行人在过马路、上下楼梯、站台候车等场景中因专注手机而忽视周围环境的安全隐患,并可应用于智慧城市安防系统、交通枢纽人流管理及校园/园区安全监控等场景。同时,本数据集可为公共安全管理系统提供智能化预警支持,有效降低事故风险,并为公共场所的安全警示系统提供数据支撑,助力提升城市公共安全管理水平。
1.数据采集
通过企业自有摄像设备自行采集道路行人图像,同步记录图像ID、采集时间、设备型号、地理坐标、光照条件、天气状况等数据。
2.数据预处理与标注
通过数据清洗剔除模糊、遮挡严重的图像。按7:2:1比例划分训练集/验证集/测试集。设置多级标注体系:
一级标签:安全行为/危险行为
二级标签:过马路玩手机/上下楼梯玩手机/站台候车玩手机
辅助标注:行人边界框坐标、手机屏幕可见性。
3.模型选择与初始化
采用YOLOv8预训练模型,初始化参数并优化超参数:学习率0.001-0.0001动态调整,批量大小1-32动态调整,锚框参数适配人体姿态;集成关键点检测提升低头行为识别精度。
4.模型训练
基于PyTorch实施分布式训练,采用混合精度训练(FP16)提升效率。设置训练时长,数据增强模拟复杂场景,添加动态模糊(模拟行人移动)、强光反射(屏幕反光干扰)、局部遮挡(背包/其他人遮挡)等特效。设置早停机制(patience=15),梯度裁剪:max_norm=1.0。
5.模型评估
在训练模型的过程中,使用验证集调整超参数,训练完成后在测试集上评估模型表现,评估指标包含:
基础性能指标:mAP@0.5、误报率
场景鲁棒性测试:低光照环境检出率
并设置渐进式测试:单人静态→多人交互场景,标准姿势→遮挡/坐姿/奔跑等变体
This dataset is primarily used to enhance the recognition capability and accuracy of AI models for identifying dangerous behaviors of pedestrians looking down at their mobile phones. Through training on this dataset, AI models can recognize safety hazards caused by pedestrians ignoring their surrounding environment while being absorbed in mobile phones in scenarios such as crossing roads, going up/down stairs, and waiting at platforms, and can be applied to scenarios including smart city security systems, passenger flow management in transportation hubs, and campus/park safety monitoring. Meanwhile, this dataset can provide intelligent early warning support for public safety management systems, effectively reduce accident risks, offer data support for safety warning systems in public places, and help improve the level of urban public safety management.
1. Data Collection
Road pedestrian images are collected using the enterprise's own camera equipment, with synchronized recording of data such as image ID, collection time, device model, geographic coordinates, lighting conditions, and weather conditions.
2. Data Preprocessing and Annotation
Blurry and severely occluded images are removed via data cleaning. The dataset is divided into training/validation/test sets at a ratio of 7:2:1. A multi-level annotation system is established:
- Primary labels: Safe behavior / Dangerous behavior
- Secondary labels: Using mobile phone while crossing the road, using mobile phone while going up/down stairs, using mobile phone while waiting at the platform
- Auxiliary annotations: Pedestrian bounding box coordinates, visibility of mobile phone screens
3. Model Selection and Initialization
The pre-trained YOLOv8 model is adopted, with parameter initialization and hyperparameter optimization: the learning rate is dynamically adjusted between 0.001 and 0.0001, the batch size is dynamically adjusted between 1 and 32, and anchor box parameters are adapted to human postures; keypoint detection is integrated to improve the recognition accuracy of head-down behaviors.
4. Model Training
Distributed training is implemented based on PyTorch, and mixed-precision training (FP16) is adopted to improve efficiency. Training duration is set, and data augmentation is used to simulate complex scenarios, with effects such as motion blur (simulating pedestrian movement), strong light reflection (interference from screen reflections), and partial occlusion (occlusion by backpacks or other people) added. An early stopping mechanism is set (patience=15), and gradient clipping is configured with max_norm=1.0.
5. Model Evaluation
During the model training process, the validation set is used to adjust hyperparameters. After training is completed, the model performance is evaluated on the test set. The evaluation metrics include:
- Basic performance metrics: mAP@0.5, false positive rate
- Scenario robustness test: detection rate in low-light environments
Progressive testing is also set up: single-person static scenario → multi-person interactive scenario, standard posture → variants such as occlusion, sitting posture, running, etc.
提供机构:
杭州声贝软件技术有限公司
创建时间:
2025-08-03
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个用于训练智能识别行人低头玩手机危险行为算法模型的图像数据集,包含581条数据,每日更新,数据格式为xlsx,涵盖了图像ID、采集时间、地理坐标、光照条件、标签(如危险行为和过马路玩手机)、行人边界框坐标和手机屏幕可见性等结构化信息。数据集旨在提升AI模型在过马路、上下楼梯、站台候车等场景中的识别能力,应用场景包括智慧城市安防、交通管理和校园监控,以降低公共安全风险,并通过YOLOv8模型训练实现了较高的性能指标,如mAP@0.5达到0.91,误报率为4.1%,低光照检出率为88%。
以上内容由遇见数据集搜集并总结生成


