hf-audio/asr-leaderboard-longform
收藏Hugging Face2026-05-01 更新2026-01-03 收录
下载链接:
https://hf-mirror.com/datasets/hf-audio/asr-leaderboard-longform
下载链接
链接失效反馈官方服务:
资源简介:
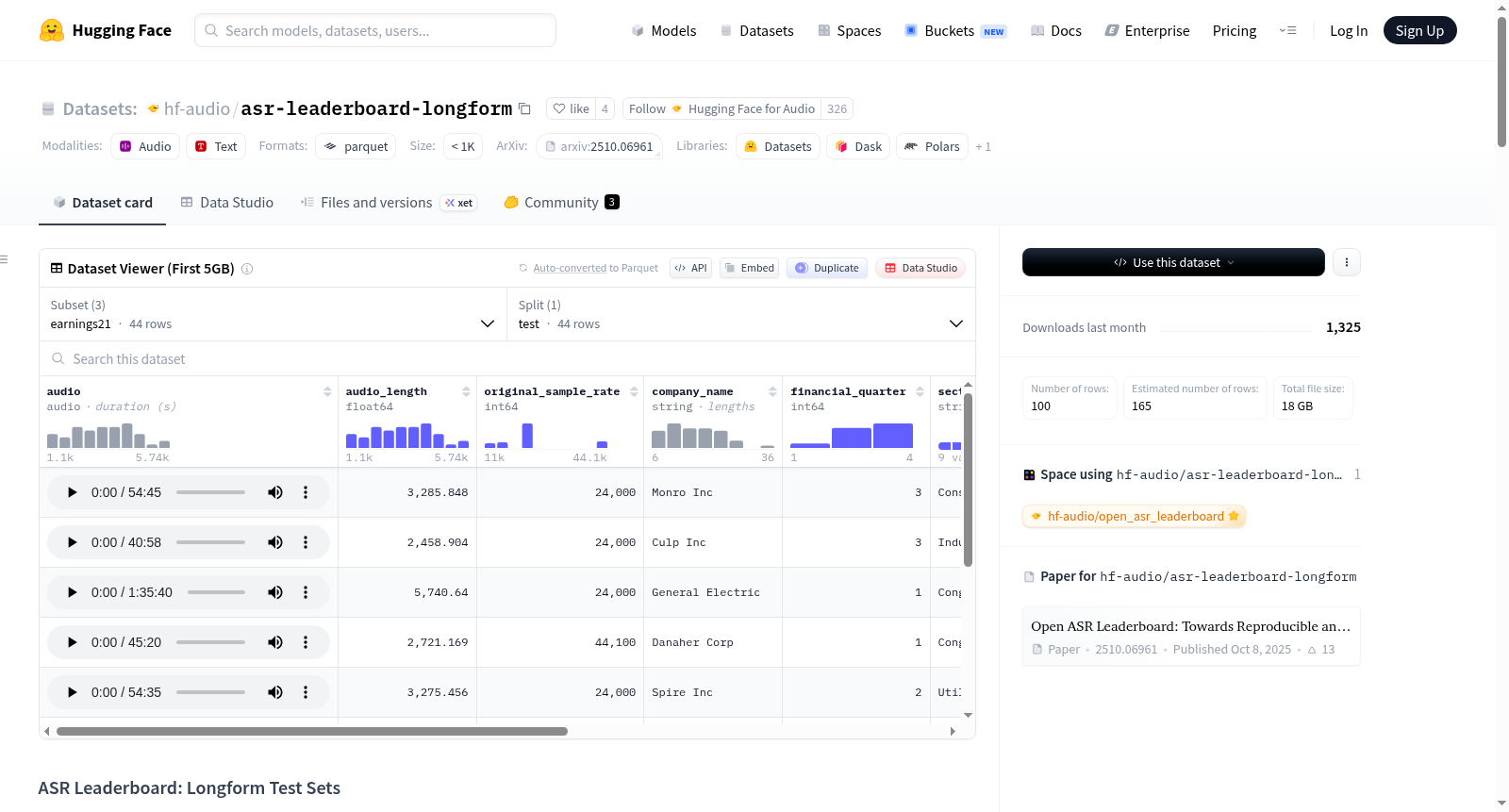
该数据集名为ASR Leaderboard: Longform Test Sets,包含三个长格式自动语音识别(ASR)基准测试集:Earnings-21、Earnings-22和TED-LIUM。这些数据集用于评估在现实条件下(如长时间音频片段、重叠说话人和特定领域语言)的长格式ASR模型性能。数据集以标准化的Parquet格式提供,包含音频、文本以及根据数据集不同而异的额外元数据。README还详细说明了每个数据集的领域、时长、说话风格、许可证信息,以及使用示例、数据字段、数据准备、评估方法和许可信息。
This dataset, named ASR Leaderboard: Longform Test Sets, provides three longform ASR benchmark test sets — Earnings-21, Earnings-22, and TED-LIUM — used for evaluating longform automatic speech recognition (ASR) models under real-world conditions such as extended audio segments, overlapping speakers, and domain-specific language. The datasets are provided in a standardized Parquet format and include features like audio, text, and additional metadata depending on the dataset. The README also details the domain, duration, speaking style, and license for each dataset, along with example usage, data fields, data preparation, evaluation methods, and licensing information.
提供机构:
hf-audio
搜集汇总
数据集介绍
构建方式
该数据集整合了三个经典的长语音识别基准测试集——Earnings-21、Earnings-22和TED-LIUM,均以标准化的Parquet格式存储,通过Hugging Face的datasets库实现高效加载。每个子集保留了其原始官方测试划分,音频文件以.flac或.wav格式提供,并附有对应的参考转录文本。Earnings系列涵盖了金融财报电话会议中的即兴发言,而TED-LIUM则收录了TED演讲中的预备式演讲。所有数据均经过统一字段架构整理,确保跨不同域的长语音评估具有一致性与可复现性。
使用方法
用户可通过一行Python代码加载指定子集,例如使用load_dataset("hf-audio/asr-leaderboard-longform", "earnings22", split="test")即可获取Earnings-22的测试集。为避免音频解码的额外开销,建议先通过索引获取样本,再访问audio字段。所有参考转录保持原始清洗后的形式,未进行额外标准化处理。该数据集专为Hugging Face ASR排行榜设计,参与者需使用测试集生成转录结果并提交,系统将基于词错误率(WER)等指标进行自动评分,从而公平比较不同模型的长语音识别能力。
背景与挑战
背景概述
自深度学习兴起以来,自动语音识别(ASR)领域在短时口语语料库上取得了显著进展,然而现实应用场景如会议转写、电话客服和财经汇报等,往往涉及数分钟乃至数小时的连续语音。这些长时语音流包含复杂的说话人切换、领域术语和自发语音现象,对模型的鲁棒性提出了更高要求。针对这一评估缺口,Hugging Face团队于2025年发布了ASR Leaderboard Longform数据集,由Vaibhav Srivastav、Steven Zheng和Eric Bezzam等研究者主导构建,整合了Earnings-21、Earnings-22和TED-LIUM三个广泛使用的长时英文基准测试集。该数据集聚焦于评估ASR模型在现实长时环境下的转录质量,已成为开放ASR排行榜中衡量长语音性能的核心资源,推动了语音识别研究从实验室短句向实际长音频的迁移。
当前挑战
该数据集所解决的领域问题集中于长时语音识别面临的持久挑战:模型需在数十分钟的连续音频中维持低词错误率,同时应对说话人重叠、口音差异和即兴发言等非理想条件。例如Earnings系列来自金融财报电话会,充斥着专业术语和多人轮换对话,而TED-LIUM虽为单人口语演讲,却跨越多个主题领域。构建过程中,团队面临着将不同来源、不同采样率和注释格式的音频数据统一为标准化Parquet格式的艰巨任务,并需确保仅使用官方测试子集以避免数据泄露,同时保留原始文本的清洁度以忠实反映真实误差来源。这些挑战促使数据集成为连接实验室评测与产业部署的桥梁。
常用场景
经典使用场景
在自动语音识别(ASR)领域,短时话语数据集已在模型评估中占据主导地位,但长时语音的鲁棒性评估长期缺乏统一基准。asr-leaderboard-longform数据集应运而生,它将Earnings-21、Earnings-22和TED-LIUM三个经典长语音测试集整合为标准化格式,专为评测ASR模型在数分钟乃至数小时连续语音上的转录能力而设计。研究人员可借助此数据集,在财务电话会议与公开演讲等真实长语音场景中,系统衡量模型的词错误率(WER)表现,从而弥补短时评测的局限性,推动长时语音识别技术的标准化评估进程。
解决学术问题
该数据集直击长时语音识别研究中测试集碎片化与领域覆盖不足的核心痛点。传统评测依赖LibriSpeech等短句语料,难以反映模型应对口音漂移、多人说话重叠及金融术语等高难度场景的真实能力。通过统一格式汇聚35小时财报电话录音与3小时TED演讲,该数据集为学术界提供了跨领域的标准评测基准。这一举措不仅消除了数据集预处理差异带来的比较偏差,更催生了针对长时上下文建模、说话人自适应和噪声鲁棒性等关键议题的系统性研究,显著提升了ASR模型在复杂声学环境中的泛化性评估可信度。
实际应用
在产业界,长时语音识别技术直接赋能会议纪要生成、客户服务中心质检、金融对话分析等高价值应用。本数据集所涵盖的财报电话会议场景,恰好对应金融行业对高频交易决策摘要的迫切需求;TED演讲场景则贴合教育培训领域对多语种演讲实时字幕生成的精度要求。企业可借此基准测试,筛选出在冗长对话中仍能保持低错误率的ASR模型,并将其部署于智能投顾系统的语音转文本管道或在线会议平台的自动字幕模块中,从而显著提升知识工作者在信息萃取与语义理解环节的作业效率。
数据集最近研究
最新研究方向
在长语音识别领域,研究重心正从短句评测向跨领域、长时段、多说话人场景迁移,asr-leaderboard-longform数据集通过整合财报电话会议(Earnings-21/22)与TED演讲等高质量长音频测试集,为评估模型在真实多说话人、专业术语密集和自发口语环境下的鲁棒性提供了标准化基准。该数据集伴随Hugging Face ASR排行榜推出,推动了开源社区对长语音识别系统在实际部署中面临的口语风格转换、说话人重叠与长序列建模等前沿难题的深入探索,其统一格式与元数据丰富性更助力研究者系统性分析不同场景下的性能瓶颈,对金融分析、会议转录等热点应用具有重要实践意义。
以上内容由遇见数据集搜集并总结生成


