ACL-Verbatim
收藏arXiv2026-05-20 更新2026-05-22 收录
下载链接:
https://huggingface.co/datasets/KRLabsOrg/acl-anthology-md
下载链接
链接失效反馈官方服务:
资源简介:
ACL-Verbatim是由维也纳技术大学与KR Labs联合创建的一个高质量基准数据集,旨在为学术研究论文中的抽取式问答任务提供无幻觉的解决方案。该数据集基于ACL Anthology库,包含100个经过精细人工标注的查询-文本块对,数据来源于2026年2月前的12万余篇计算语言学与自然语言处理领域论文,通过PDF转Markdown及自定义分块策略预处理生成。其创建过程采用ScIRGen方法生成合成查询,并由NLP研究人员进行严格的相关性标注与文本跨度标注,确保了数据的可靠性与专业性。该数据集主要应用于训练和评估抽取式模型,以解决大语言模型在学术问答中产生的幻觉问题,提升研究信息检索的准确性与可解释性,服务于高效、透明的AI辅助研究工具开发。
ACL-Verbatim is a high-quality benchmark dataset jointly created by the Vienna University of Technology and KR Labs, aiming to provide hallucination-free solutions for extractive question answering tasks in academic research papers. Based on the ACL Anthology repository, this dataset contains 100 meticulously manually annotated query-text chunk pairs, sourced from over 120,000 papers in the fields of computational linguistics and natural language processing published before February 2026, and generated through PDF-to-Markdown conversion and a custom chunking strategy during preprocessing. During its development, the ScIRGen method was adopted to generate synthetic queries, and strict relevance and text span annotations were performed by NLP researchers, ensuring the reliability and professionalism of the dataset. This dataset is primarily used for training and evaluating extractive models, aiming to address the hallucination issues of large language models (LLMs) in academic question answering, improve the accuracy and interpretability of research information retrieval, and support the development of efficient and transparent AI-assisted research tools.
提供机构:
维也纳技术大学; KR Labs
创建时间:
2026-05-20
原始信息汇总
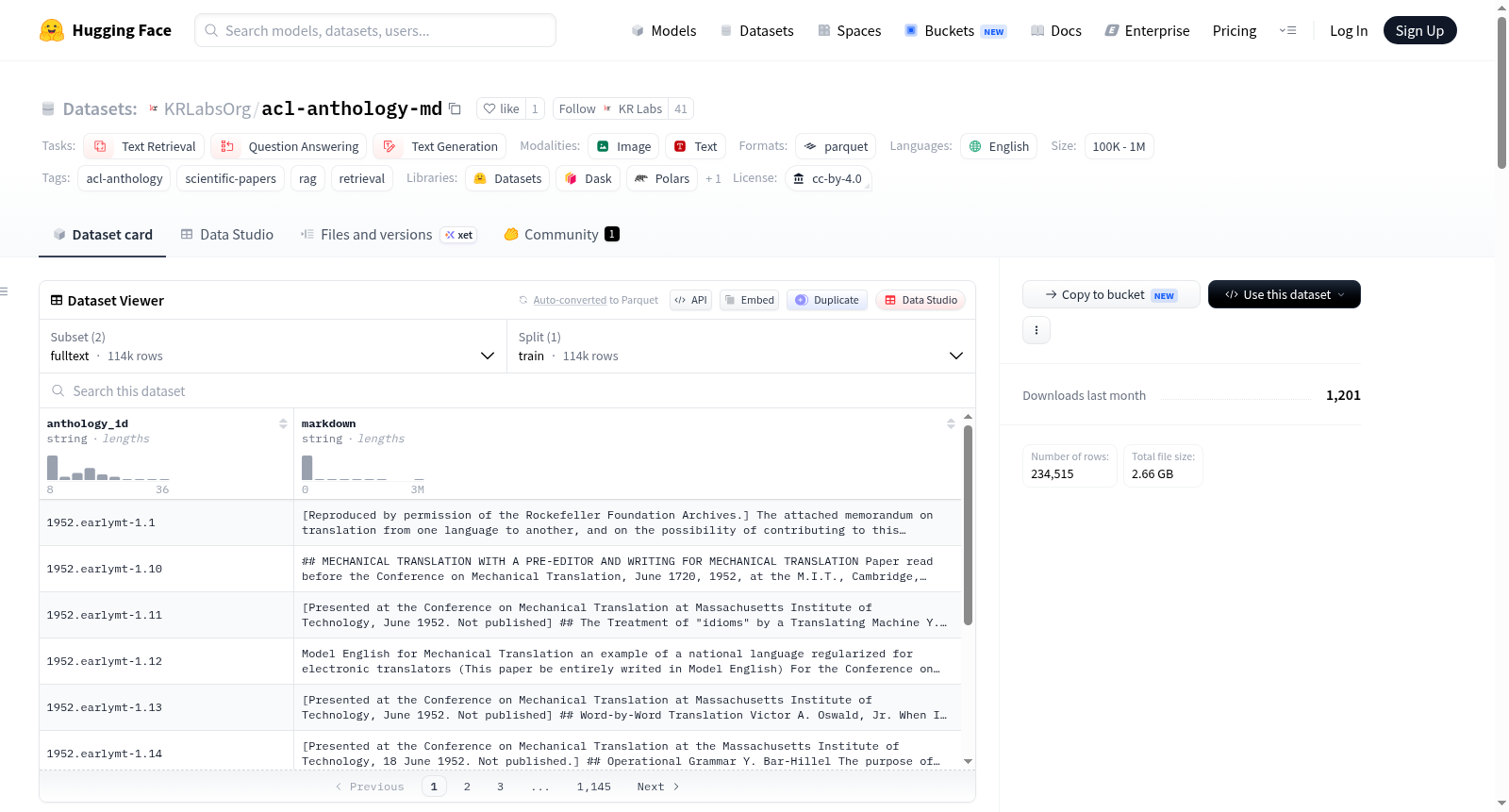
数据集概况
- 数据集名称: ACL Anthology Markdown Corpus
- 许可证: CC-BY-4.0
- 任务类型: 文本检索、问答、文本生成
- 语言: 英语
- 数据规模: 100K至1M条记录
- 模态: 文本
- 标签: acl-anthology、科学论文、RAG、检索
- 发布者: KRLabsOrg
数据集构成
该数据集包含两个配置(config),通过 anthology_id 进行关联:
metadata(120,034 条记录)
包含ACL Anthology中所有论文的文献元数据,包括前言和仅有摘要的条目。主要字段包括:
| 字段 | 类型 | 说明 |
|---|---|---|
anthology_id |
字符串 | 唯一标识符,如 2023.acl-long.42,用于关联两个配置 |
paper_id |
字符串 | Anthology内部数字ID |
bibkey, bibtype, bibtex |
字符串 | BibTeX信息 |
title, title_html, title_raw |
字符串 | 不同格式的论文标题 |
author |
列表 | 作者信息结构化字段 |
url, pdf, thumbnail, doi |
字符串 | 论文相关链接 |
abstract_html, abstract_raw |
字符串 | 摘要(约72k篇论文可用) |
year, venue |
字符串/列表 | 年份和会议名称 |
has_markdown |
布尔值 | 标记该论文是否有全文Markdown |
fulltext(114,484 条记录)
包含已转换的论文全文Markdown文本。主要字段包括:
| 字段 | 类型 | 说明 |
|---|---|---|
anthology_id |
字符串 | 与metadata关联的标识符 |
markdown |
字符串 | 使用docling转换的论文全文Markdown |
数据集统计
| 指标 | 数值 |
|---|---|
| 元数据论文总数 | 120,034 |
| 有全文Markdown的论文 | 114,484(95.4%) |
| 年份范围 | 1952 – 2026 |
| 不同会议/期刊数量 | 500 |
| 有摘要的论文 | 71,902 |
| 每篇论文平均作者数 | 3.7 |
| 总Markdown大小 | 5.10 GB |
| 每篇论文Markdown中位数/90百分位/99百分位 | 37 KB / 74 KB / 162 KB |
论文数量最多的会议/期刊:acl(13,664)、emnlp(11,525)、ws(10,714)、findings(10,519)、lrec(9,105)、coling(8,701)、naacl(5,458)、ijcnlp(3,871)、semeval(3,330)、jeptalnrecital(2,766)。
构建流程
- 从 acl-org/acl-anthology 仓库中提取元数据。
- 获取PDF文件(不重新分发PDF,仅包含转换后的Markdown)。
- 使用 docling 的
DocumentConverter将PDF转换为Markdown(在单张A100 GPU上运行)。 - 组装数据集:将Markdown文件与元数据通过
anthology_id关联,写入两个配置。
预期用途
- 基于NLP研究文献的检索增强生成(RAG)。
- 训练和评估科学文本上的抽取式问答/引文溯源系统。
- 针对NLP社区的文献计量和元研究。
搜集汇总
数据集介绍
构建方式
在学术研究中,研究者亟需从海量文献中高效获取可靠信息,但大语言模型固有的幻觉现象严重威胁了信息检索的准确性。为此,ACL-Verbatim数据集应运而生,其构建基于VerbatimRAG框架,专注于从ACL Anthology中超过12万篇计算语言学论文中进行抽取式问答。首先,利用Docling工具将PDF论文转换为Markdown格式,并通过自定义分块策略沿章节边界将论文分割为长度介于500至5000字符的文本块。随后,基于ScIRGen方法论设计流水线,自动生成合成用户查询,并借助VerbatimRAG索引检索每个查询对应的前五个文本块。最后,由NLP研究人员对100个查询-文本块对进行人工标注,识别与查询最为相关的文本片段,形成包含47个相关块和53个无关块的高质量基准数据集。
使用方法
使用ACL-Verbatim数据集时,研究者可将其作为抽取式问答模型的训练与评估基准。具体而言,模型需以用户查询和检索到的文本块为输入,输出与查询最相关的连续文本片段。数据集提供了基于词级别的精确率、召回率与F1值等评估指标,建议采用如ModernBERT等轻量级编码器模型在合成银数据上进行微调,并辅以阈值筛选(如0.2)及后处理步骤(如丢弃短于10字符的片段、合并间距小于20字符的相邻片段)来优化输出。同时,研究者亦可利用该数据集与VerbatimRAG框架结合,构建端到端的无幻觉问答系统,通过将模型部署于ACL Anthology索引之上,实现从真实查询到证据片段的精确映射。
背景与挑战
背景概述
ACL-Verbatim 数据集由维也纳工业大学与 KR Labs 的研究团队于 2026 年联合创建,旨在解决大型语言模型在科研文献问答中生成幻觉内容的严峻问题。该数据集基于 ACL Anthology 中逾 12 万篇计算语言学论文,核心研究聚焦于构建无幻觉的抽取式问答系统,通过将用户查询直接映射至文献中的原文字段,以杜绝生成式模型常见的虚假输出。作为 VerbatimRAG 框架的关键组成部分,ACL-Verbatim 为抽取式问答提供了人工标注的基准数据,其影响力体现在为高精度、可解释的学术信息检索开辟了新路径,并推动了小型化模型在减少参数量的同时超越大型语言模型的提取性能。
当前挑战
ACL-Verbatim 所面临的核心挑战包括:领域难题方面,现有生成式问答系统普遍存在幻觉现象,即便采用检索增强生成框架,大型语言模型仍会基于自身先验知识扭曲检索结果,导致事实性错误;同时,学术文本中的专业术语与复杂推理使得精准定位相关证据极为困难。构建过程中的挑战尤为突出:人工标注任务需依赖领域专家的深层理解,例如解析合并谓词语序等价条件这类专业性极强的查询,标注者需通读并掌握算法原理才能判断文本块的相关性;此外,合成查询的生成与筛选流程复杂,需通过多步提示工程实现问题类型的分类与简化,而标注歧义性导致仅有 100 个查询-文本对完成了人工验证,数据规模受限且标注一致性难以保证。
常用场景
经典使用场景
在学术研究与自然语言处理领域,问答系统常因大语言模型产生的事实性谬误而备受困扰。ACL-Verbatim数据集专为学术场景下的无幻觉问答而设计,其核心应用在于从ACL Anthology收录的海量计算语言学论文中,精确提取与用户查询直接对应的原文片段。该数据集通过人类注释者基于合成查询与论文片段构建的基准,为评估和训练抽取式问答模型提供了可靠的测试平台。研究者可借助该数据集,验证模型从长篇学术文本中定位相关证据的能力,从而推动构建可信赖的、基于原文的科学文献智能检索系统。
解决学术问题
该数据集直击当前检索增强生成系统中的关键痼疾——生成模型在引用外部资料时仍频繁产生与原文不符的幻觉内容。ACL-Verbatim通过严格限定输出必须为原文逐字片段,从根本上规避了生成式模型对信息的曲解与编造。它有效解决了学术场景中信息溯源难、响应可靠性低、以及模型可解释性不足等核心问题。该数据集的提出,使得研究者能够在计算语言学领域内,以可量化的方式比较不同抽取式模型的精准度与召回率,为开发高精度、低资源消耗的学术问答工具奠定了坚实的实证基础。
实际应用
在实际应用层面,ACL-Verbatim可无缝嵌入科研文献管理系统与学术搜索引擎之中,为研究人员提供一种即查即得、有据可依的知识获取方式。当学者输入诸如解析合并谓词序列等价条件这类高度专业化的查询时,系统能够从海量论文中精准定位到唯一相关的算法描述段落,而非生成模棱两可的摘要。该数据集支撑的抽取式问答框架特别适用于文献综述撰写、实验方法溯源、以及跨论文对比分析等高精度需求场景,显著提升了知识发现流程的透明度与效率,降低了因信息误传而导致的学术风险。
数据集最近研究
最新研究方向
在学术文献问答领域,大型语言模型幻觉问题仍是核心挑战。ACL-Verbatim 数据集聚焦于无幻觉的抽取式问答,将用户查询直接映射到论文中的原文片段,为科研人员提供高可靠性的信息检索方案。该研究前沿方向包括:基于 VerbatimRAG 框架的端到端抽取系统,通过银标签监督训练小规模 ModernBERT 模型在词级 F1 上超越大模型;利用合成查询与人工标注构建高质量基准,推动可解释、可验证的学术问答系统发展。这一工作直接回应了 RAG 系统中外在幻觉与算法崇拜的痛点,为医疗、法律等高风险领域提供了低资源、高精度的抽取范式,其开源管线与多领域泛化能力显著降低了 AI 辅助科研的信任门槛。
相关研究论文
- 1ACL-Verbatim: hallucination-free question answering for research维也纳技术大学; KR Labs · 2026年
以上内容由遇见数据集搜集并总结生成


