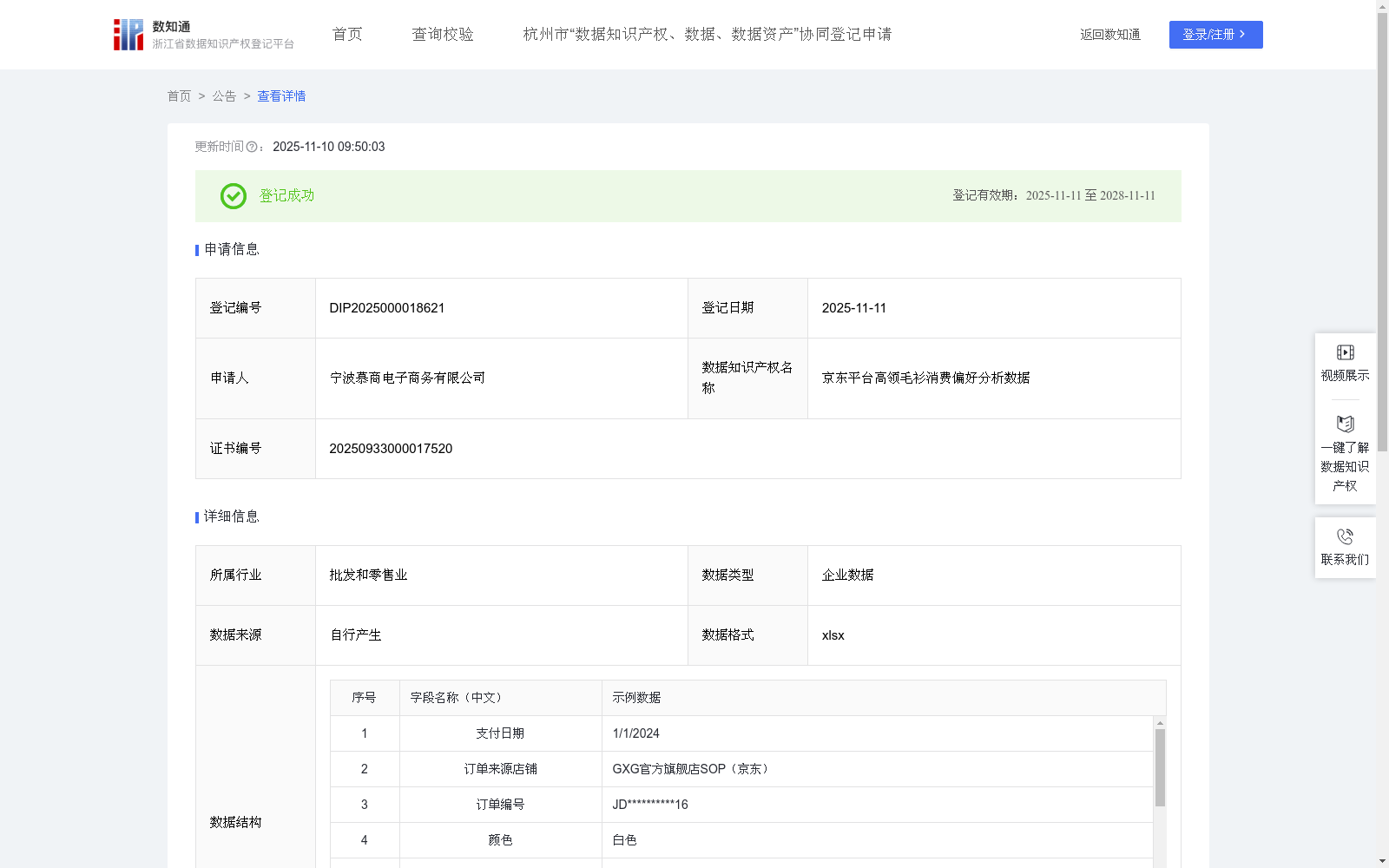
京东平台高领毛衫消费偏好分析数据
收藏浙江省数据知识产权登记平台2025-11-10 更新2025-11-11 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8394538
下载链接
链接失效反馈官方服务:
资源简介:
通过收集和分析全国范围内有对高领毛衫产品交易行为的省份以及相关消费数据,深度洞察京东平台用户的消费偏好(如款式、材质、颜色、价格等),可应用于对公司内部运营的优化与重塑以及服装行业整体协同增强。对公司内部而言,对于高偏好品类,可以提前锁定优质面料供应商,优化采购成本,可灵活调整生产线,降低原材料和成品库存的资金占用,显著提升库存周转率。对于服装行业而言,可以行业协同共同开发更符合市场需求的新品,从源头优化产品设计,增强供应链条的响应速度与竞争力。从而为本行业的全链条企业制定生产销售策略提供数据支撑,更好地为客户提供个性化的商品和服务。1、数据采集:采集全国范围内高领毛衫产品销售交易数据以及其他所有品类产品消费数据。2、数据处理,对采集到的数据进行分类、梳理,便于分析使用。3、算法加工:将处理后的数据进行分析:全品类产品平均订单金额=全品类产品销售额/全品类产品订单总数量(保留两位小数),偏好指数L(高领毛衫)=(高领毛衫销售额/全品类产品平均订单金额)*(全品类产品订单总数量/全品类产品销售额),用于将算法确定为基于全品类产品平均订单金额的需求量进行计算。数据为整理后状态,主要根据产品种类汇集,不完全按照时间先后顺序;订单可能存在捆绑/拼单/活动优惠,同品牌高领毛衫产品单价在各区域、不同时间的差价忽略不计,因此全品类产品销售额/全品类产品订单总数量≠某品类产品销售额/某品类产品订单总数量,全品类数据由多个品类消费偏好数据集合汇总得出,依据行业经验采用全品类产品平均订单金额进行标准化算法处理。4、数据分类分级复用:根据计算出的偏好指数,L>5.0记为高偏好品类,1.0<L≤5.0记为中偏好品类,1.0≥L记为低偏好品类,根据等级安排更精准的生产营销策略,例如:加大高偏好品类的铺货量等。
This dataset is developed by collecting and analyzing provincial-level transaction data and relevant consumer spending data related to turtleneck sweater purchases across China, to gain in-depth insights into JD.com platform users' consumer preferences (including product style, material, color, price, etc.). The findings can be applied to optimize and restructure the internal operations of the company, as well as enhance overall collaboration within the apparel industry.
For the company itself, for high-preference product categories, the firm can secure high-quality fabric suppliers in advance to optimize procurement costs, flexibly adjust production lines, reduce capital tied up in raw material and finished goods inventory, and significantly improve inventory turnover rate. For the apparel industry as a whole, industry collaboration can be leveraged to jointly develop new products that better align with market demand, optimize product design from the source, and enhance the responsiveness and competitiveness of the entire supply chain. This dataset provides data support for full-chain enterprises in the industry to formulate production and sales strategies, so as to better deliver personalized products and services to customers.
1. Data Collection: Collect sales transaction data of turtleneck sweaters and consumer data of all other product categories across the country.
2. Data Processing: Classify and organize the collected data to facilitate subsequent analysis and application.
3. Algorithmic Processing: Analyze the processed data with the following formulas:
- Average Order Value of All Categories (AOV_all) = Total Sales of All Categories / Total Number of Orders of All Categories (rounded to two decimal places)
- Preference Index L (for turtleneck sweaters) = (Total Sales of Turtleneck Sweaters / AOV_all) * (Total Number of Orders of All Categories / Total Sales of All Categories)
The processed data is aggregated primarily by product category, not strictly in chronological order. Bundled orders, group purchases, and promotional discounts may exist, and price differences of same-brand turtleneck sweaters across regions and time periods are ignored. Therefore, AOV_all ≠ Average Order Value of a Single Category (AOV_single) = Total Sales of Single Category / Total Number of Orders of Single Category. The all-category data is aggregated from consumer preference data of multiple product categories, and standardized algorithmic processing using AOV_all is adopted based on industry practices.
4. Data Classification, Grading and Reuse: Classify products based on the calculated preference index L: high-preference category for L > 5.0, medium-preference category for 1.0 < L ≤ 5.0, and low-preference category for L ≤ 1.0. Formulate more precise production and marketing strategies according to the category grade, such as increasing inventory allocation for high-preference categories.
提供机构:
宁波慕商电子商务有限公司
创建时间:
2025-09-01
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集聚焦京东平台2024年高领毛衫消费数据,包含3107条交易记录,涵盖颜色、尺寸、地区等关键字段,并通过偏好指数(如高偏好指数22.11)分析用户偏好。数据应用于企业内部运营优化和服装行业协同,为生产销售策略提供数据支撑。
以上内容由遇见数据集搜集并总结生成


