gemma-270m-medium-qa
收藏Hugging Face2025-08-21 更新2025-08-22 收录
下载链接:
https://huggingface.co/datasets/Simon-Liu/gemma-270m-medium-qa
下载链接
链接失效反馈官方服务:
资源简介:
Twinkle Dialogue数据集是一个包含由Gemma-3-27B-it(Twinkle AI社群服务)生成的对话数据的集合,采用OpenAI Chat Messages格式(.jsonl)。该数据集结合了两种类型的对话:Reference-free(由seed派生的单轮问答)和Reference-based(依据ADK Python Repository的Markdown内容生成的单轮问答)。数据集适用于文本生成任务,语言为繁体中文(生成内容),部分参考文本为英文。数据集用于教学示范,不代表专业意见。Reference-based数据的答案不应超出参考文本范围。
The Twinkle Dialogue Dataset is a collection of conversational data generated by Gemma-3-27B-it (Twinkle AI Community Service), formatted in the OpenAI Chat Messages specification with .jsonl file extension. This dataset combines two types of dialogues: Reference-free (single-turn Q&A pairs derived from seed inputs) and Reference-based (single-turn Q&A pairs generated based on the Markdown content from the ADK Python Repository). This dataset is designed for text generation tasks, with its generated content in Traditional Chinese, while some reference texts are in English. It is intended for teaching and demonstration purposes only and does not represent professional advice. Answers for Reference-based data must not exceed the scope of the provided reference texts.
创建时间:
2025-08-20
原始信息汇总
数据集概述:Simon-Liu/gemma-270m-medium-qa
基本信息
- 数据集名称:Simon-Liu/gemma-270m-medium-qa
- 标签:dialog, instruction-tuning, sft, openai-messages, reference-based, reference-free
- 许可证:cc-by-4.0
- 任务类别:text-generation
- 语言:zh(繁体中文)
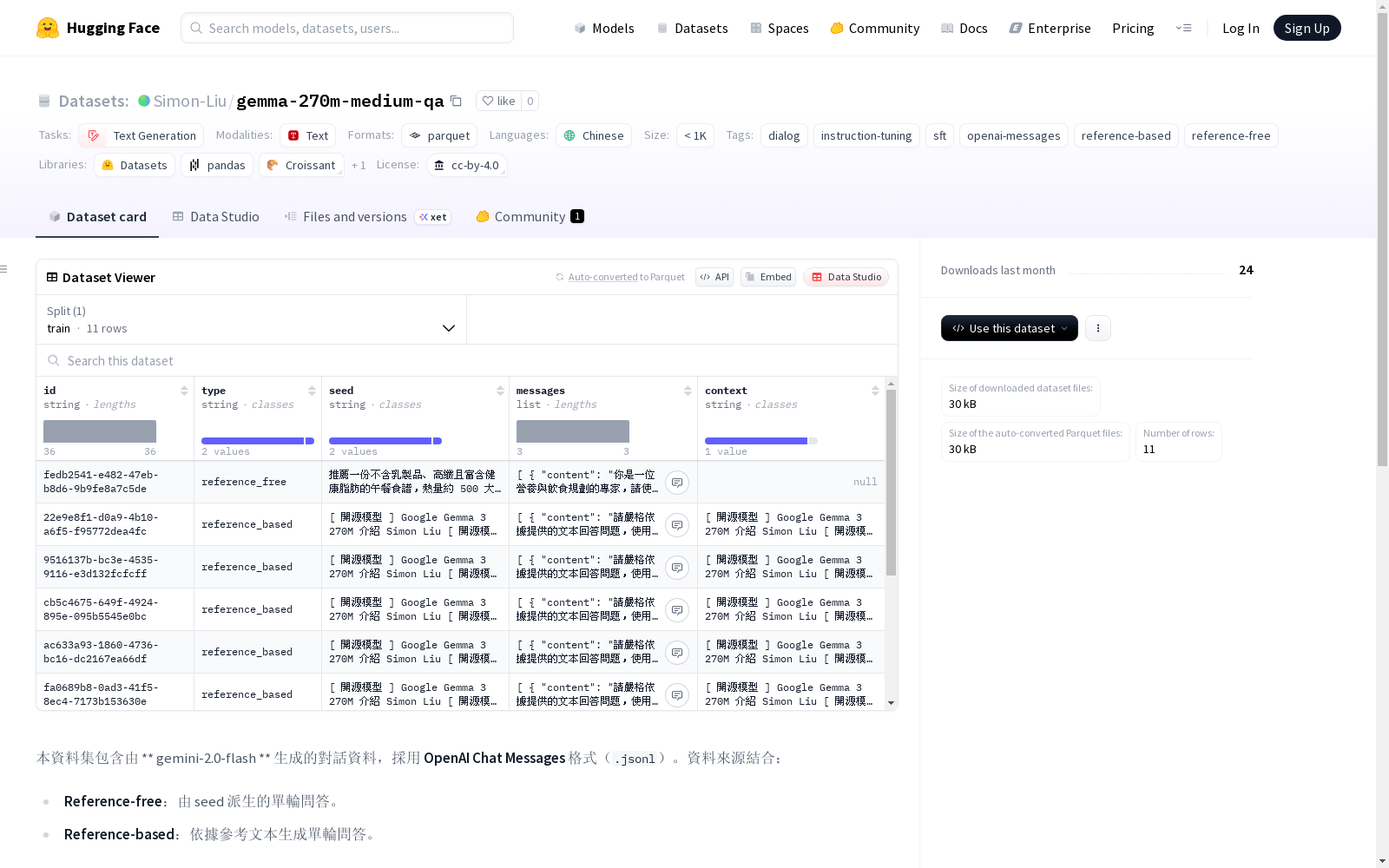
数据内容
- 数据格式:OpenAI Chat Messages格式(
.jsonl) - 数据生成模型:gemini-2.0-flash
- 数据来源类型:
- Reference-free:由seed派生的单轮问答
- Reference-based:依据参考文本生成的单轮问答
数据结构
-
文件路径:
data/train.jsonl(选配:data/train.parquet) -
样本结构: json { "id": "...", "type": "...", "seed": "...", "context": "...", "messages": [ {"role": "user", "content": "..."}, {"role": "assistant", "content": "..."} ] }
-
字段说明:
type:标识数据来源(reference_free或reference_based)seed:存储Reference-free的原始seed指令,或Reference-based的参考文本片段context:仅在reference_based数据中包含完整的参考文本片段messages:可直接用于训练的对话格式
使用限制
- 语言限制:生成内容为繁体中文,部分参考文本为英文
- 使用场景:教学示范用,不代表专业意见
- 重要限制:Reference-based数据的问题和答案均从参考文本中生成,答案不应超出参考文本范围
搜集汇总
数据集介绍
构建方式
在对话生成与指令调优的研究领域中,gemma-270m-medium-qa数据集采用双路径构建策略。其数据源自gemini-2.0-flash模型生成,涵盖reference-free与reference-based两种类型:前者通过种子指令派生单轮问答,后者则依据参考文本片段生成对应问答。所有数据均以OpenAI Chat Messages的JSONL格式存储,确保了结构化与可扩展性。
特点
该数据集以繁体中文生成为主,部分参考文本为英文,具备多语言交叉特性。其样本结构清晰,每列包含类型标识、种子或参考文本源、完整对话消息等内容,支持直接用于对话模型的训练。数据设计注重上下文关联性,尤其在reference-based类型中,答案严格限制于参考文本范围内,增强了内容的准确性与可控性。
使用方法
使用者可通过加载train.jsonl或train.parquet文件,直接提取messages字段中的对话序列进行模型训练。该格式兼容主流对话生成框架,无需额外预处理。应用时需注意数据生成于教学示范场景,不代表专业意见,且应遵循CC BY 4.0许可协议,确保合规使用与后续分发。
背景与挑战
背景概述
在自然语言处理领域,指令微调数据集对提升模型对话能力具有关键作用。gemma-270m-medium-qa数据集由Simon-Liu团队构建,采用OpenAI消息格式,专门针对中文对话任务设计。该数据集融合无参考与基于参考的生成策略,通过gemini-2.0-flash模型合成高质量问答对,旨在推动对话系统与指令跟随技术的研究与应用。
当前挑战
该数据集核心挑战在于解决开放域问答中答案准确性与上下文相关性的平衡问题,同时需确保生成内容严格遵循参考文本范围以避免幻觉。构建过程中面临生成模型偏差控制、中英文跨语言一致性维护,以及对话逻辑连贯性保障等多重技术难点,这些因素共同增加了数据质量控制的复杂度。
常用场景
经典使用场景
在对话系统研究领域,该数据集通过OpenAI消息格式构建的指令微调样本,为生成式对话模型提供了高质量的监督微调素材。其reference-free和reference-based双模式设计,能够有效支撑模型在开放域问答和基于文档的精确应答两种典型场景下的性能优化,显著提升模型对用户指令的理解与执行能力。
解决学术问题
该数据集主要解决了指令微调过程中高质量中文对话数据稀缺的学术难题,为研究社区提供了标准化的评测基准。通过结构化的问题-答案对,它支持模型事实性、一致性和逻辑性的量化评估,对推进对话生成的可控性与可靠性研究具有重要价值,填补了中文指令微调数据资源的空白。
衍生相关工作
该数据集的构建方法论催生了多项相关研究,包括基于检索增强的对话生成技术、多轮指令微调框架的优化,以及中英文混合数据下的跨语言泛化能力探索。其开放的消息格式标准也被后续工作广泛采纳,推动了对话数据标准化和模型 interoperability 的研究进程。
以上内容由遇见数据集搜集并总结生成


