GPT-NL-propella-annotations
收藏Hugging Face2026-05-04 更新2026-05-05 收录
下载链接:
https://huggingface.co/datasets/tvosch/GPT-NL-propella-annotations
下载链接
链接失效反馈官方服务:
资源简介:
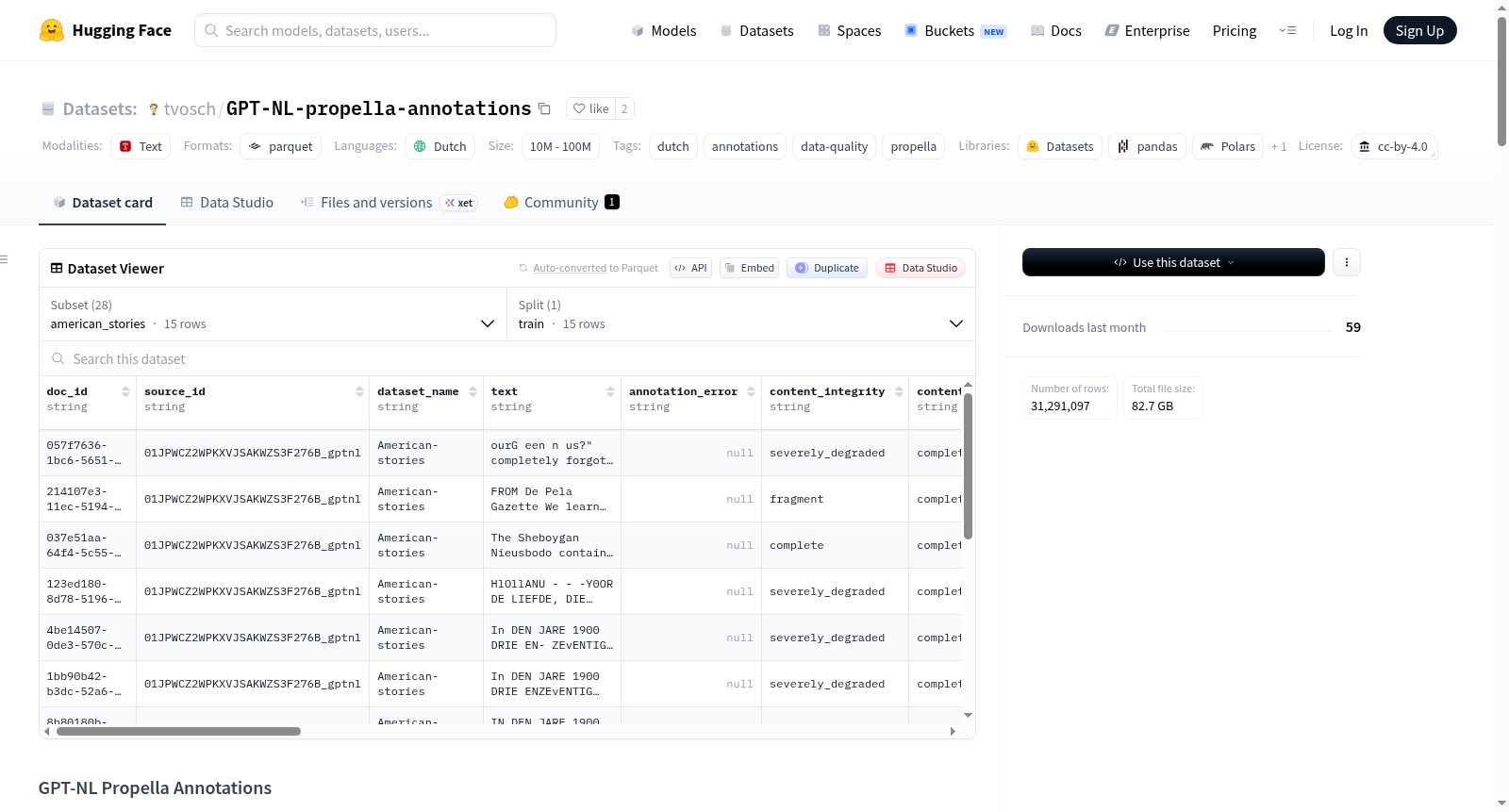
GPT-NL Propella Annotations数据集包含对GPT-NL Public Corpus荷兰语子集的文档级质量和内容注释。该数据集由Propella模型生成,该模型是一个基于Qwen3微调的40亿参数语言模型,专门用于LLM预训练数据的文档级注释。数据集包含31,291,097个文档,共计50,297,442,743个标记。每个文档都附有结构化的JSON对象注释,涵盖18个质量和内容属性,包括内容完整性、内容类型、受众水平、安全性等多个维度。数据集分为多个子集,如American-stories、Auditdienst Rijk、Belgian Journal等,每个子集都有相应的配置名称和文档数量。数据集适用于数据筛选、去重和领域平衡等任务。数据集采用CC-BY-4.0许可,语言为荷兰语。
The GPT-NL Propella Annotations dataset contains document-level quality and content annotations for the Dutch subset of the GPT-NL Public Corpus. This dataset is generated by the Propella model, a 4-billion-parameter language model fine-tuned on Qwen3, specifically designed for document-level annotation of LLM pre-training data. The dataset includes 31,291,097 documents, totaling 50,297,442,743 tokens. Each document is accompanied by structured JSON object annotations covering 18 quality and content attributes, including content completeness, content type, audience level, safety, and more. The dataset is divided into multiple subsets, such as American-stories, Auditdienst Rijk, Belgian Journal, etc., each with corresponding configuration names and document counts. The dataset is suitable for tasks such as data filtering, deduplication, and domain balancing. The dataset is licensed under CC-BY-4.0 and is in the Dutch language.
创建时间:
2026-04-20
原始信息汇总
GPT-NL Propella Annotations 数据集概述
基本信息
- 数据集名称: GPT-NL Propella Annotations
- 许可证: CC-BY-4.0
- 语言: 荷兰语 (nl)
- 标签: dutch, annotations, data-quality, propella
- 数据集地址: https://huggingface.co/datasets/tvosch/GPT-NL-propella-annotations
数据集描述
该数据集包含对 GPT-NL/GPT-NL_Public_Corpus 中荷兰语子集的文档级质量和内容注释。每个数据行对应 GPT-NL Public Corpus 中的一个荷兰语文档,包含由 Propella 模型生成的结构化注释以及原始文本。
数据集规模
- 文档数量: 31,291,097 个文档
- Token 数量: 50,297,442,743 个 token
注释模型 (Propella)
Propella(ellamind/propella-1-4b)是一个 4B 参数的语言模型,基于 Qwen3 微调,专门用于LLM预训练数据的文档级注释。给定任意语言的文档,它生成包含 18 个质量、分类和安全属性的结构化 JSON 对象。
数据子集
| 子集名称 | Config 名称 | 文档数 |
|---|---|---|
| American-stories | american_stories |
15 |
| Auditdienst Rijk | auditdienst_rijk |
555 |
| Belgian Journal | belgian_journal |
208,242 |
| C5 Filtered | c5_filtered |
63,519 |
| CC-English-PD | cc_english_pd |
1,329 |
| CC-Eurovoc | cc_eurovoc |
34,948 |
| CC-German-PD | cc_german_pd |
8,177 |
| CC-Github Code | cc_github_code |
38,083 |
| CC-Loc-PD-Books | cc_loc_pd_books |
14 |
| DANS-KNAW | dans_knaw |
52,880 |
| De Rechtspraak | de_rechtspraak |
918,634 |
| Dienst Publiek en Communicatie | dienst_publiek_en_communicatie |
127,715 |
| Eurlex | eurlex |
36,810 |
| European Parliament | european_parliament |
654 |
| Koninklijke Bibliotheek | koninklijke_bibliotheek |
1,571,895 |
| Nationaal Archief | nationaal_archief |
1,924,127 |
| Naturalis | naturalis |
2,652 |
| Noord-Hollands Archief | noord_hollands_archief |
38,737 |
| Officiele Bekendmakingen | officiele_bekendmakingen |
1,822,093 |
| Openraadsinformatie | openraadsinformatie |
2,712,533 |
| PBL | pbl |
341 |
| Tweede Kamer | tweede_kamer |
229,600 |
| Utrechts Archief | utrechts_archief |
525,886 |
| Wikidata-Synth | wikidata_synth |
14,582,582 |
| Wikiwijs | wikiwijs |
119,187 |
| Woogle | woogle |
4,088,931 |
| YouTube-Commons-Synth | youtube_commons_synth |
2,147,061 |
| Zeeuws Archief | zeeuws_archief |
33,897 |
| 总数 | 31,291,097 |
数据列说明
| 列名 | 类型 | 描述 |
|---|---|---|
doc_id |
string | 确定性 UUID5 唯一标识符,跨重运行稳定。 |
source_id |
string | 来自 GPT-NL_Public_Corpus 的原始 id 值。 |
dataset_name |
string | 来自 GPT-NL_Public_Corpus 的子语料库名称。 |
text |
string | 文档文本(CC-BY-4.0 许可)。 |
content_integrity |
string | 文本是否完整和连贯。 |
content_ratio |
string | 有意义内容与模板/噪音的比例。 |
content_length |
string | 定性长度类别。 |
one_sentence_description |
string | 文档的单句摘要。 |
content_type |
list[string] | 内容类型标签(如 news, legal_document, boilerplate)。 |
business_sector |
list[string] | 相关行业/部门标签。 |
technical_content |
list[string] | 技术内容的程度和类型。 |
information_density |
string | 文本的信息密度。 |
content_quality |
string | 总体质量评级。 |
audience_level |
string | 目标受众(如 general, expert)。 |
commercial_bias |
string | 商业意图的程度。 |
time_sensitivity |
string | 内容是时效性还是常青内容。 |
content_safety |
string | 安全分类。 |
educational_value |
string | 教育价值评级。 |
reasoning_indicators |
string | 推理或论证的存在。 |
pii_presence |
string | 文档是否包含个人身份信息。 |
regional_relevance |
list[string] | 地理相关性标签。 |
country_relevance |
list[string] | 特定国家相关性标签。 |
annotation_error |
string | 仅当注释模型失败时填充,此时所有注释列为 null。 |
重要说明
- source_id 唯一性:
source_id不是文档级唯一标识符,应使用doc_id作为稳定唯一标识符。 - 注释错误: 约 239,000 个文档(<1%)因模型输出验证失败而无法注释,这些行的所有注释列为
null,annotation_error列非空。 - 来源语料库: GPT-NL/GPT-NL_Public_Corpus
- 来源许可证: CC-BY-4.0
搜集汇总
数据集介绍
构建方式
GPT-NL-propella-annotations数据集基于荷兰语大语言模型训练语料库GPT-NL/GPT-NL_Public_Corpus构建,其核心在于利用Propella模型进行文档级质量与内容标注。Propella是一个经过微调的4B参数语言模型,能够为任意语言文档生成包含18个维度的结构化JSON标注信息,涵盖质量、分类与安全属性。数据集通过vLLM服务框架与xgrammar结构化输出约束,以FP8量化方式高效推理,确保标注格式的规范性与可复用性。每个文档样本均保留原始文本,并补充了由模型产出的多维度注释。
使用方法
用户可通过HuggingFace Datasets库加载任意子配置,例如`load_dataset('GPT-NL/GPT-NL-propella-annotations', 'tweede_kamer')`。使用前建议过滤含`annotation_error`字段非空的异常行,如`ds.filter(lambda x: x['annotation_error'] is None)`。标注可应用于训练数据筛选与加权:例如依据`content_quality`剔除低质文档,利用`content_type`实现领域平衡采样,或通过`information_density`调节知识密度分布。所有数据遵循CC-BY-4.0许可协议,适用于学术研究及商业场景中的语料精炼与模型训练优化。
背景与挑战
背景概述
随着大规模语言模型预训练数据的复杂性日益提升,数据质量及其多维度标注成为提升模型性能的关键瓶颈。GPT-NL Propella Annotations数据集由Ellamind团队于近年创建,旨在为荷兰语公共语料库GPT-NL/GPT-NL_Public_Corpus提供细粒度的文档级质量与内容标注。该数据集利用4B参数的Propella模型,对超过3100万份荷兰语文档进行了18种属性的结构化标注,涵盖内容完整性、信息密度、商业偏向及安全性等关键维度。其发布为低资源语言(如荷兰语)的预训练数据筛选与领域平衡提供了可复用的标准化基准,显著推动了多语言自然语言处理中数据治理方法的进步。
当前挑战
该数据集面临的核心挑战源于文档质量异质性与标注可靠性的辩证关系。首先,领域问题在于:荷兰语作为相对低资源语言,其预训练语料混杂了大量噪声(如模板化内容、机器翻译痕迹及不完整文档),亟需自动化工具区分高价值文本与冗余信息,而传统规则或单标签分类器难以捕捉语义层面的微妙差异。其次,构建过程中,Propella模型虽能输出18维结构化标注,但约0.8%(约23.9万)的文档因模型输出验证失败产生空标注,揭示了大规模自动化标注中约束生成(如xgrammar框架)与模型容错率之间的技术张力。此外,不同子语料库的领域分布极不平衡(如Wikidata合成数据占近半数,而某些档案集仅数十篇),导致标注泛化性受限于长尾数据稀疏性,需在后续使用中通过下采样或加权策略弥补偏差。
常用场景
经典使用场景
在自然语言处理与大规模语言模型预训练领域,GPT-NL-propella-annotations最为经典的使用场景,是作为荷兰语语料库的质量标注与内容分类基准。该数据集依托Propella模型对GPT-NL公共语料库中超过3100万份文档进行结构化标注,涵盖内容完整性、信息密度、商业倾向、安全性等18个维度的属性。研究者可依据这些标签对海量无监督文本进行精细筛选与加权,从而构建高质量、领域均衡的预训练语料子集,显著提升下游模型的训练效率与生成质量。
解决学术问题
该数据集有效回应了低资源语言在大规模预训练中面临的数据质量参差不齐与领域覆盖失衡这一核心学术难题。通过为荷兰语文档提供细粒度的质量与内容标注,它使得研究者能够系统性地剔除噪声文本、识别低价值内容,并量化不同领域(如法律、新闻、科学文献)的分布比例。此举不仅提升了预训练数据的可解释性与可复用性,也为跨语言数据治理策略提供了实证基础,推动了多语言模型在公平性与鲁棒性方面的研究进展。
实际应用
在实际产业应用中,GPT-NL-propella-annotations被广泛用于荷兰语自然语言处理系统的数据流水线优化。例如,企业可借助其内容类型与受众级别标签,自动筛选并提升面向公众的法律文书或教育材料的语料占比;媒体机构可依据时间敏感性与商业偏见标注,过滤新闻摘要中的广告内容。此外,该数据集还支持政府与学术机构构建垂直领域模型,如基于法律判决(De Rechtspraak)或议会记录(Tweede Kamer)进行专业化微调,从而提升自动化文本分析服务的精准度。
数据集最近研究
最新研究方向
数据集最新研究方向聚焦于利用精细化的文档级质量标注框架,推动非英语(尤其荷兰语)大语言模型预训练语料的智能筛选与内容治理。通过Propella模型对超3000万份荷兰语文档进行18维度的结构化评估,涵盖内容完整性、信息密度、商业倾向及安全合规等核心指标,该数据集为破解低资源语言语料噪声大、领域分布不均的瓶颈提供了范式支撑。当前前沿探索包括将标注结果用于构建高质量的多域平衡子集(如法律、政务、文化遗产),并结合自动化去重与毒性检测技术优化模型训练的数据配比,这一方向呼应了欧盟数字化转型背景下对开放、可信、语言包容的AI基础设施的迫切需求,其意义在于为荷兰语等小语种打破英语中心主义的数据垄断提供了可复现的基准路径。
以上内容由遇见数据集搜集并总结生成


