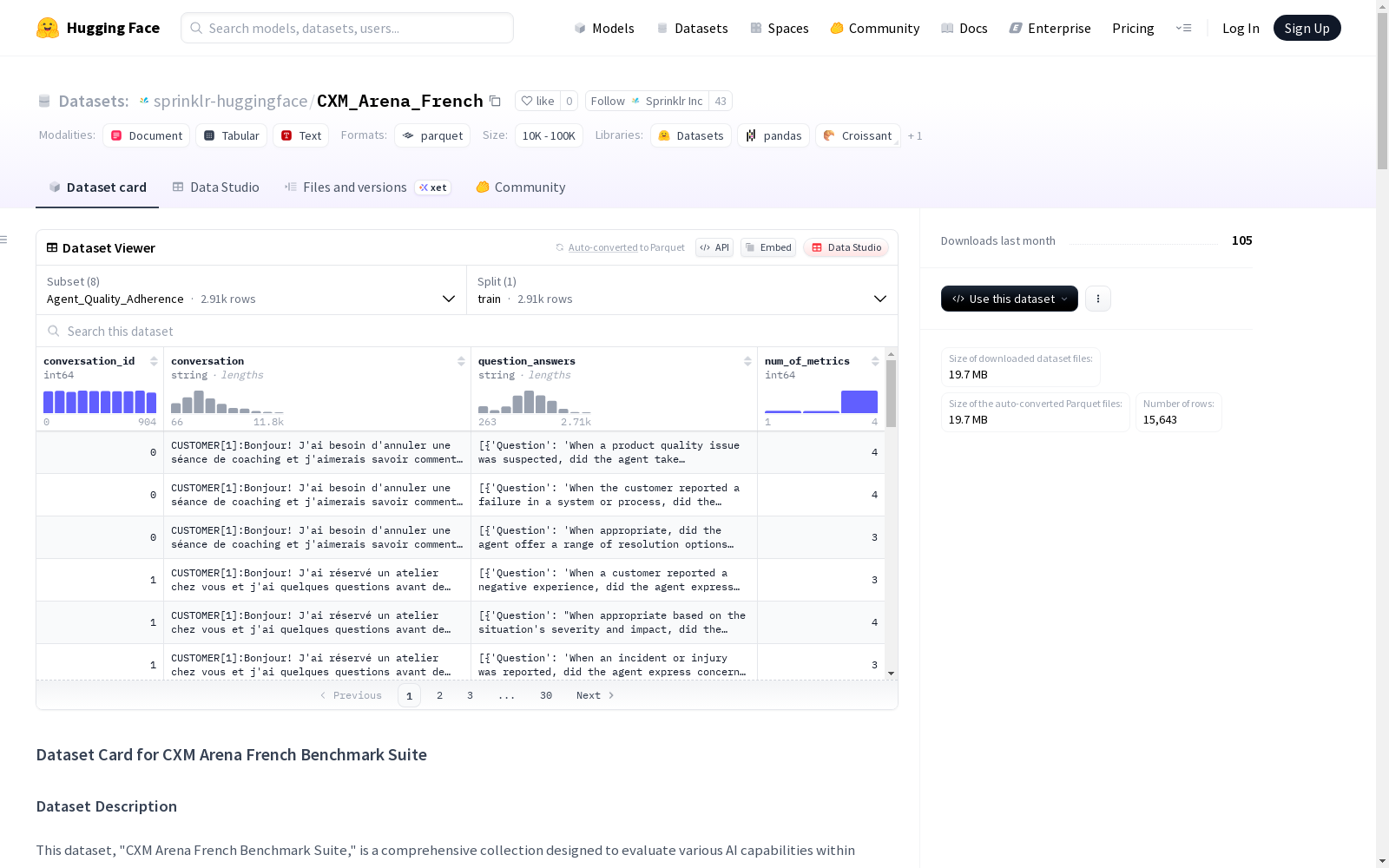
CXM_Arena_French
收藏Hugging Face2025-07-30 更新2025-07-31 收录
下载链接:
https://huggingface.co/datasets/sprinklr-huggingface/CXM_Arena_French
下载链接
链接失效反馈官方服务:
资源简介:
CXM Arena French Benchmark Suite是一个专为法语设计的全面数据集,用于评估AI在客户体验管理(CXM)领域的多种能力。该数据集包括五个核心任务:1. Agent Quality Adherence:监控法语对话中客服人员的表现。2. KB Refinement:处理业务文章,识别法语知识库条目中的相似和矛盾信息。3. Intent Prediction:基于不同的发现分类法,从客服对话中识别用户意图。4. Multi-Turn RAG with Tools:在多轮法语交互中评估会话AI系统的检索、生成和工具使用能力。
CXM Arena French Benchmark Suite is a comprehensive dataset tailored specifically for the French language, aimed at evaluating a wide range of AI capabilities in the Customer Experience Management (CXM) domain. This dataset includes five core tasks: 1. Agent Quality Adherence: Monitor the performance of customer support agents during French-language conversational interactions. 2. KB Refinement: Process business articles to identify similar and contradictory information within French-language knowledge base entries. 3. Intent Prediction: Identify user intent from customer service conversations based on multiple discovery taxonomies. 4. Multi-Turn RAG with Tools: Evaluate the retrieval, generation and tool-use capabilities of conversational AI systems during multi-turn French-language interactions.
创建时间:
2025-07-29
原始信息汇总
CXM Arena French Benchmark Suite 数据集概述
数据集描述
- 目的:评估客户体验管理(CXM)领域中AI能力的综合性法语基准测试套件
- 语言:法语
- 特点:基于原始CXM_Arena基准建模,全部数据为法语生成
- 生成方式:使用先进大语言模型合成生成,包含重要品牌实体和现实法语场景
核心任务
- Agent Quality Adherence:通过模拟法语对话监控联络中心座席表现
- KB Refinement:处理商业文章,识别法语知识库中的相似/矛盾信息
- Intent Prediction:基于多种分类法识别联络中心对话中的用户意图
- Multi-Turn RAG with Tools:评估多轮法语交互中的检索、生成和工具使用能力
数据集详情
- 维护方:Spinklr AI
- 许可证:CC BY-NC-4.0
- 配置信息:
- KB_Refinement:
- contradictory_pairs:422个样本/5918字节
- similarity_pairs:569个样本/7448字节
- Articles:
- KB_refinement_articles:2223个样本/4181793字节
- multi_turn_articles:2435个样本/5883604字节
- Taxonomy:
- taxonomy_1:286个样本/32328字节
- Intent_Prediction:
- train:997个样本/1520270字节
- Agent_Quality_Adherence:
- train:2914个样本/3498804字节
- Multi_Turn:
- train:4142个样本/2223182字节
- Tool_Calling:
- train:1505个样本/2553514字节
- Tools_Description:
- train:150个样本/33520字节
- KB_Refinement:
评估结果
- 评估方法:随机采样100个数据点,使用intfloat/multilingual-e5-large嵌入和gemini-2.0-flash进行LLM推理
- 结果图表:
- Agent Quality Adherence
- KB Refinement
- Intent Prediction
- Multi-Turn RAG with Tools (包含2个图表)
搜集汇总
数据集介绍
构建方式
在客户体验管理领域,CXM_Arena_French数据集通过系统化方法构建,专注于法语环境下的多任务评估。该数据集采用先进的大语言模型生成合成数据,精心设计了品牌实体和真实场景的法语模拟对话,涵盖知识库优化、意图识别等五个核心任务模块。数据以parquet格式存储,各任务模块独立配置,确保数据结构清晰可追溯,为法语区客户服务AI研究提供标准化基准。
特点
作为法语客户体验管理的专业评估套件,该数据集最显著的特点是任务导向的多模态架构。其包含2914条客服质量监测对话、2223篇知识库文章及1505次工具调用记录,通过矛盾对检测、多轮对话等子任务形成立体评估维度。所有数据均经过标准化处理,配套提供置信区间分析图表,支持'intfloat/multilingual-e5-large'等嵌入模型直接调用,满足工业级评估需求。
使用方法
针对法语AI模型开发需求,该数据集支持端到端的客户服务能力测试。研究者可分别加载KB_Refinement等八个配置模块,利用预置的评估指标分析模型在意图预测、工具调用等场景的表现。建议参照原项目库的评估流程,结合gemini-2.0-flash等大模型进行推理测试,注意法语语言特性对语义相似度计算的影响,以获得准确的跨任务性能对比。
背景与挑战
背景概述
CXM_Arena_French数据集由Spinklr AI团队构建,专注于客户体验管理(CXM)领域的法语基准测试。该数据集基于原始CXM_Arena框架,针对法语环境进行了全面本地化,包含知识库优化、意图预测、多轮对话工具调用等五大核心任务模块。作为商业场景下AI能力评估的重要工具,其采用合成数据生成技术,模拟真实品牌实体和交互情境,填补了法语CXM领域标准化评估资源的空白。数据集的设计反映了当前企业数字化转型过程中对多语言客户服务智能化的迫切需求,为法语区市场的AI解决方案研发提供了关键基础设施支持。
当前挑战
该数据集面临双重技术挑战:在领域问题层面,法语复杂的语法结构和丰富的方言变种对意图识别准确率形成显著压力,多轮对话中工具调用的上下文一致性维护也考验模型的语言理解深度。数据构建过程中,合成数据真实性验证成为关键瓶颈,需要平衡生成效率与语义合理性;同时,商业知识库的专业术语对齐、多任务评估指标的协同优化等工程问题,都对数据集的可靠性和泛化能力提出了更高要求。
常用场景
经典使用场景
在客户体验管理领域,CXM_Arena_French数据集为法语环境下的多任务评估提供了标准化基准。其核心价值体现在对知识库优化场景的支撑,研究者通过对比分析相似性与矛盾性语句对,能够系统评估模型在法语语义理解与逻辑推理方面的性能。该数据集特别适用于检验跨语言模型在商业知识库清洗、信息一致性校验等关键任务中的泛化能力。
实际应用
在实际商业部署中,企业可利用该数据集优化法语区智能客服系统。特别是其多轮对话与工具调用模块,能够指导开发符合欧盟语言规范的对话式AI,显著提升电商支持、银行咨询等场景的自动化服务覆盖率。数据集内含的质检标准更为跨国企业建立统一的服务质量监控体系提供了量化依据。
衍生相关工作
基于该数据集衍生的研究已推动多项法语NLP技术创新,包括基于E5嵌入的跨语言检索方案、融合业务规则的多意图分类框架等。其基准测试方法论更被Adapted to French等后续工作广泛引用,成为评估法语商业对话系统的事实标准,持续促进学术界与产业界的知识迁移。
以上内容由遇见数据集搜集并总结生成


