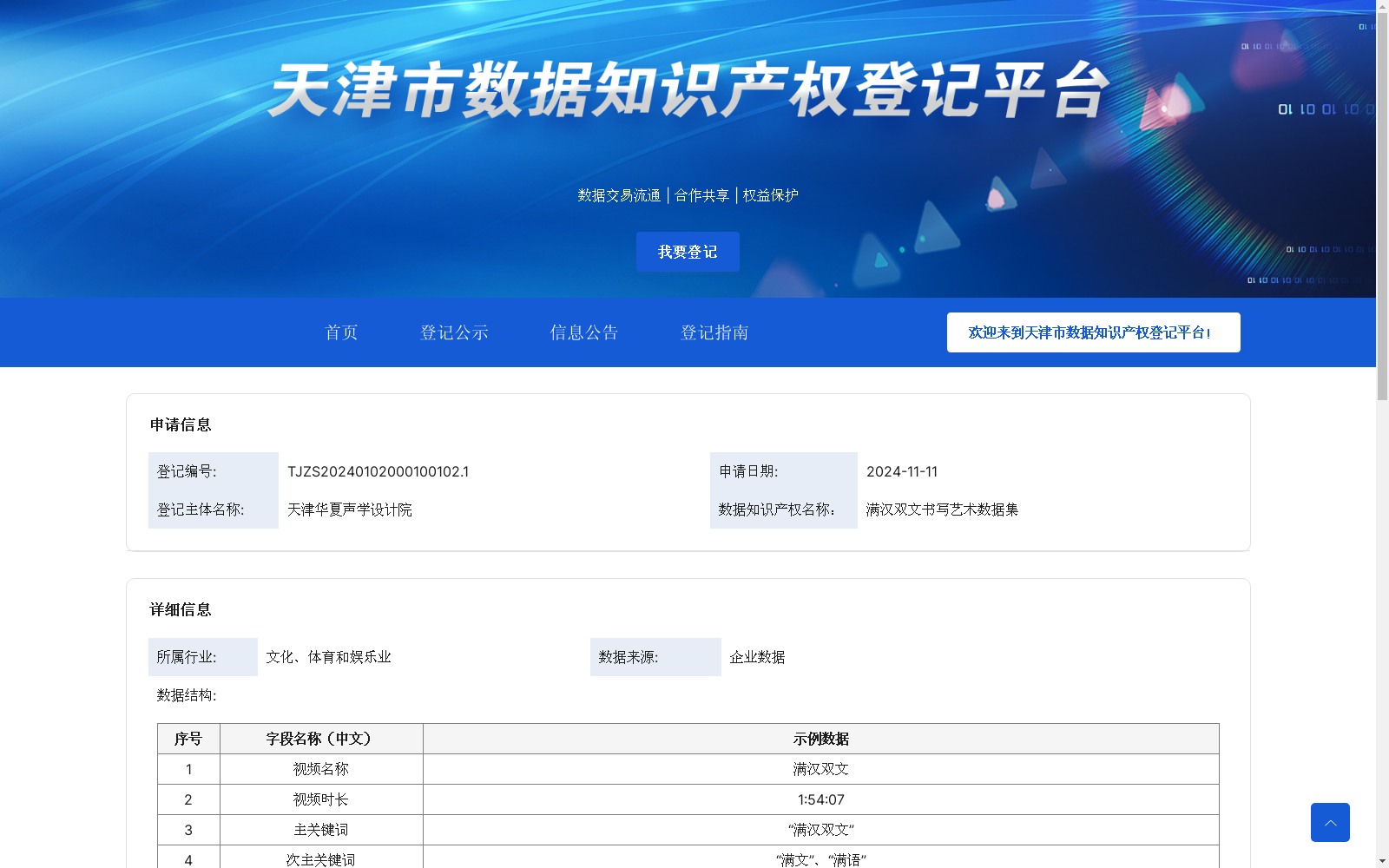
满汉双文书写艺术数据集
收藏资源简介:
1、先获取视频的标题、描述、时长以及音频中的文字信息,使用自然语言处理技术提取关键词作为视频的标签,存储在特定的数据字段中。 2、对输入视频进行帧提取操作,针对每个视频帧,分别进行图像特征提取和音频特征提取。图像特征提取过程中,考虑帧宽度和帧高度等因素,以获取更准确的图像特征向量。音频特征提取时,结合音频采样频率和频道等信息,得到音频特征向量。 3、采用双流网络算法进行处理。构建两个并行的卷积神经网络(CNN),一个专门处理视频的图像特征向量,另一个处理音频特征向量。在两个网络的末端,将图像和音频特征进行融合。输入视频经过帧提取后,对每个视频帧进行图像特征提取和音频特征提取,得到视频的图像和音频特征向量。通过全连接层和 softmax 函数输出视频所属的类别标签以及相应的概率值并分类。 4、输入音频经过特征提取得到特征向量,在这个过程中,可以根据需要进行特征选择或降维处理,去除冗余信息。特征选择或降维时可考虑音频采样频率、频道等因素。 音频特征向量作为输入层的输入,经过隐藏层的神经元计算,通过激活函数传递信号,最后在输出层输出音频所属的类别
1. First, obtain the title, description, duration of the video, and the text information from the audio. Extract keywords as video tags using natural language processing (NLP) techniques, and store them in specific data fields. 2. Perform frame extraction on the input video, and conduct image feature extraction and audio feature extraction for each video frame respectively. During image feature extraction, factors such as frame width and frame height are considered to obtain more accurate image feature vectors. When extracting audio features, combine information such as audio sampling frequency and channels to obtain audio feature vectors. 3. Adopt a two-stream network algorithm for processing. Construct two parallel convolutional neural networks (CNNs), one dedicated to processing the image feature vectors of the video, and the other for processing audio feature vectors. At the end of the two networks, fuse the image and audio features. After the input video undergoes frame extraction, perform image and audio feature extraction on each video frame to obtain the image and audio feature vectors of the video. Output the category label to which the video belongs and the corresponding probability values through fully connected layers and the softmax function for classification. 4. The input audio undergoes feature extraction to obtain feature vectors. During this process, feature selection or dimensionality reduction processing can be performed as needed to remove redundant information. Factors such as audio sampling frequency and channels can be considered during feature selection or dimensionality reduction. The audio feature vector is used as the input of the input layer, and signals are transmitted through activation functions after calculation by neurons in the hidden layer, and finally the category to which the audio belongs is output at the output layer.