UBC-NLP/alexandria
收藏Hugging Face2026-05-04 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/UBC-NLP/alexandria
下载链接
链接失效反馈官方服务:
资源简介:
Alexandria是一个多领域英语↔方言阿拉伯语机器翻译数据集,旨在支持文化包容性、方言感知的自然语言处理和大型语言模型评估。该数据集包含13个阿拉伯国家的多轮对话,覆盖11个社会重要领域,如医疗、教育、农业、商业等。数据集提供了丰富的元数据,包括方言、领域、人物角色和性别配置。Alexandria旨在支持阿拉伯语机器翻译、方言阿拉伯语生成、对话感知翻译以及跨地区阿拉伯语变体的大型语言模型评估。
Alexandria is a multi-domain English↔Dialectal Arabic machine translation dataset designed for culturally inclusive, dialect-aware NLP and LLM evaluation. It pairs English multi-turn conversations with human-translated dialectal Arabic from 13 Arab countries, enriched with sub-dialect metadata, domain labels, persona roles, and speaker→addressee gender configurations. The dataset is built to support both training and benchmarking for Arabic machine translation, dialectal Arabic generation, conversation-aware translation, and LLM evaluation across regional Arabic varieties.
提供机构:
UBC-NLP
搜集汇总
数据集介绍
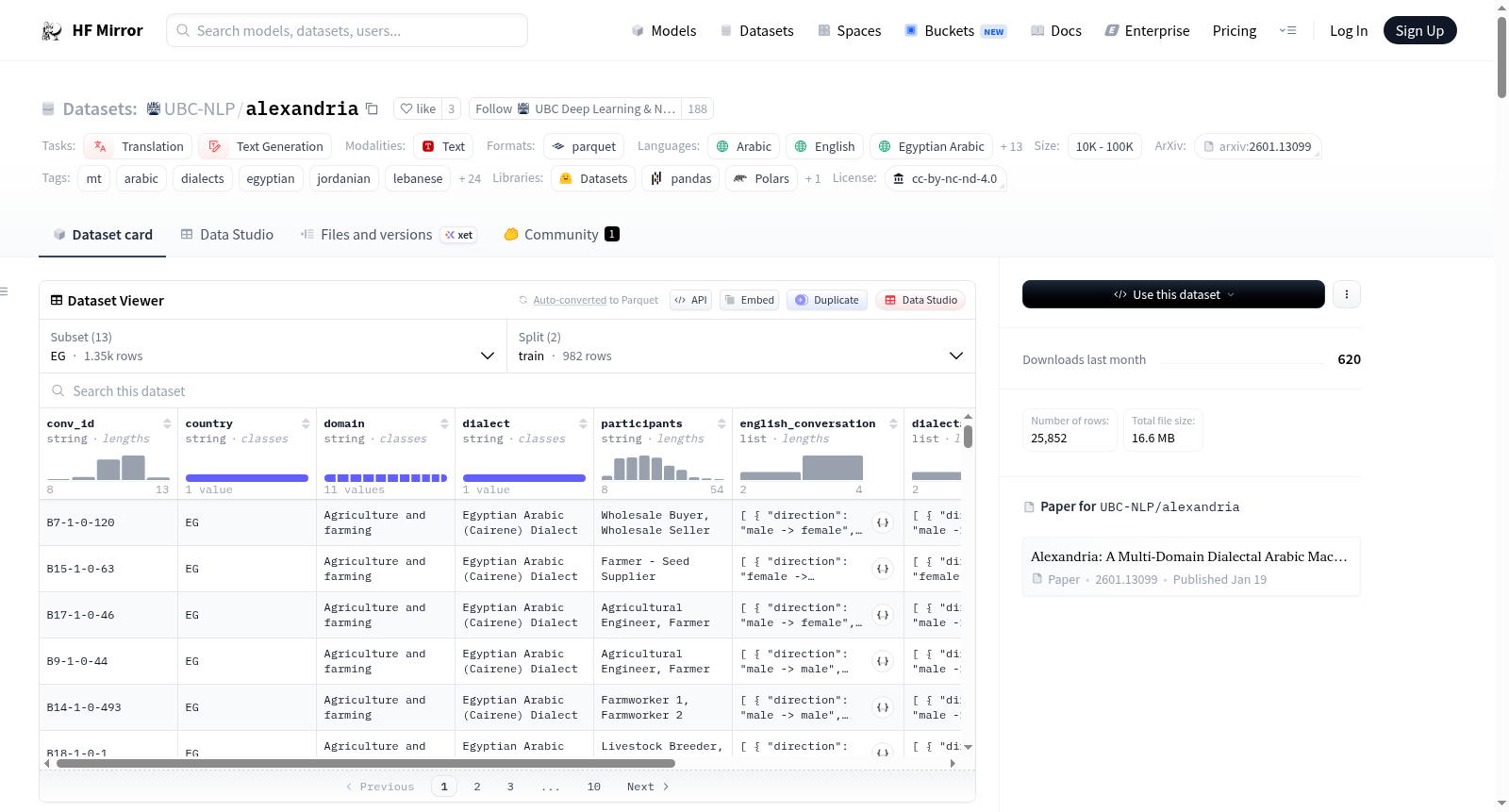
构建方式
Alexandria数据集旨在弥合阿拉伯语高度 diglossic 现象带来的自然语言处理鸿沟,即日常沟通多依赖区域方言而非现代标准阿拉伯语(MSA)。该数据集以社区驱动方式构建,由55位来自13个阿拉伯国家的母语贡献者参与,首先生成英语多轮对话,随后由本地母语者将其翻译为对应的阿拉伯方言,并经由评审者校订以保障翻译质量与方言地道性。在此基础上,数据集融入了基于城市级别的细粒度次方言元数据、11个社会重要领域标签(如医疗、教育、农业等)、角色身份信息以及说话人与受话人两两间性别配置,从而构建了一个平行、轮次对齐的多轮对话平行语料库。
使用方法
用户可通过Hugging Face的datasets库便捷加载Alexandria数据集。首先,使用`load_dataset('UBC-NLP/alexandria', name='COUNTRY_CODE', split='train')`方式指定特定国家子集(如'MA'表示摩洛哥)与数据切分(训练集或测试集),即可获取包含对话ID、国家、方言、领域、参与者、英语对话及方言对话等字段的结构化数据。每个对话样例如同字典,通过`english_conversation`与`dialectal_conversation`键访问平行轮次列表,其中每个轮次包含方向(说话人至受话人)、说话人标识、文本内容及轮次顺序。该数据集适用于训练英语至阿拉伯方言的机器翻译模型、评估多语言大语言模型在方言翻译上的性能,以及开展上下文感知和对话级别的翻译研究。
背景与挑战
背景概述
阿拉伯语作为一种高度diglossic的语言,日常交流大多依赖地区方言,而非现代标准阿拉伯语(MSA),这给自然语言处理领域带来了独特挑战。为此,Alexandria数据集于近年由UBC-NLP团队主导,携手来自13个阿拉伯国家的55位社区贡献者共同创建。该数据集聚焦于英语与方言阿拉伯语之间的机器翻译,覆盖13个阿拉伯国家、11个社会重要领域(如医疗、教育、农业)及107K条基于多轮对话的样本,旨在构建一个文化包容、方言感知的翻译基准与评估资源。Alexandria的发布填补了现有语料库在方言多样性、对话层级标注及城市粒度元数据方面的空白,对推动阿拉伯语机器翻译与大语言模型的方言鲁棒性评估具有重要影响力。
当前挑战
Alexandria着力应对两大核心挑战。其一,领域问题层面,现有阿拉伯语机器翻译系统多偏重于现代标准阿拉伯语,在方言多样性、对话语境及文化包容性上存在显著短板,难以支撑真实场景下的跨方言交流;Alexandria通过构建覆盖13国方言与11领域、融合性别与角色元数据的对话级平行语料,为方言感知翻译与评估提供了基准。其二,构建过程中,团队面临方言标注的精细化难题:需确保每个方言变体(如埃及、黎巴嫩、摩洛哥方言)的翻译准确性与地道性,同时协调55位来自不同国家的贡献者按统一标准完成生成、翻译与审核,克服地域分散、方言差异巨大及元数据一致性的挑战,最终产出城市锚定、多维度标注的高质量资源。
常用场景
经典使用场景
Alexandria数据集专为英语至方言阿拉伯语的机器翻译任务而设计,其核心应用场景聚焦于多轮对话的跨语言转换。该数据集涵盖了来自13个阿拉伯国家的11个社会关键领域,诸如医疗、教育、农业和旅游业等,提供了丰富的对话级平行语料。研究者可利用其精细的元数据,包括国家、城市级方言标签、对话主题以及发言人与受话人的性别配置,来训练和评估能够理解并生成地道阿拉伯方言的翻译系统。这种对话式、上下文敏感的翻译任务,构成了该数据集最经典且核心的使用范式。
解决学术问题
该数据集致力于解决阿拉伯语自然语言处理领域中长期存在的两大核心学术难题:高度方言多样性与语域混杂性。现有的机器翻译系统多侧重于现代标准阿拉伯语,难以应对实际交流中普遍存在的方言变体。Alexandria通过提供大规模、人工翻译且带有城市级别细粒度方言标签的对话语料,为构建方言感知的翻译模型提供了关键资源。它使得学界能够系统性地研究并量化不同阿拉伯方言之间的语义鸿沟,以及性别、社会角色和对话语境对翻译质量的影响,从而推动实现更具包容性和文化鲁棒性的阿拉伯语机器翻译。
实际应用
在实际应用层面,Alexandria数据集为构建面向阿拉伯世界用户的智能交互系统提供了坚实基础。例如,在跨国电商平台的客户服务系统中,该数据集可助力翻译模型准确理解并回应来自埃及、摩洛哥或沙特阿拉伯等不同地区用户的方言咨询,从而显著提升服务效率与用户满意度。在医疗健康领域,它能够支持跨方言的医患沟通翻译,确保诊断信息和医嘱在不同方言背景的患者间准确传递。同样,在旅游、法律咨询及远程教育等场景中,Alexandria数据集支持的方言翻译能力,能够打破语言隔阂,促进文化间的有效沟通与信息共享。
数据集最近研究
最新研究方向
当前,阿拉伯语自然语言处理领域正经历从标准阿拉伯语向方言化、文化包容性转向的深刻变革。Alexandria数据集应运而生,它以覆盖13个阿拉伯国家的多轮对话为核心,精准捕捉了方言多样性、城市级细粒度标签以及性别感知的会话语境,填补了现有资源在会话层级翻译、方言鲁棒性评估与跨领域迁移学习上的关键空白。该数据集不仅为英语与方言阿拉伯语之间的机器翻译提供了大规模、社区驱动的训练基准,更推动了阿拉伯语大语言模型向地域化、文化敏感性的前沿探索。其对社会热点领域(如医疗、教育、法律)的全面覆盖,使得模型在真实场景下的方言理解与生成能力得以系统性评估,为构建真正接地气的阿拉伯语对话系统奠定了里程碑式的基础。
以上内容由遇见数据集搜集并总结生成


