Bacon935/MathNet
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/Bacon935/MathNet
下载链接
链接失效反馈官方服务:
资源简介:
---
pretty_name: "MathNet v0 — Olympiad Math Reasoning & Retrieval"
license: cc-by-4.0
repository: https://github.com/ShadeAlsha/MathNet
contact_email: shaden@mit.edu
homepage: https://mathnet.mit.edu
task_categories:
- question-answering
- text-generation
- image-to-text
language:
- en
- pt
- es
- fr
- it
- sr
- sl
- de
- zh
- ro
- ko
- nl
- ru
- mn
- mk
- pl
- hu
tags:
- mathematics
- olympiad
- reasoning
- competition-math
- multimodal
- retrieval
- benchmark
- evaluation
- tables
- iclr-2026
- v0
size_categories:
- 10K<n<100K
configs:
- config_name: all
data_files:
- split: train
path: data/all/train-*.parquet
default: true
- config_name: Argentina
data_files:
- split: train
path: data/Argentina/train-*.parquet
- config_name: Asia_Pacific_Mathematics_Olympiad_APMO
data_files:
- split: train
path: data/Asia_Pacific_Mathematics_Olympiad_APMO/train-*.parquet
- config_name: Austria
data_files:
- split: train
path: data/Austria/train-*.parquet
- config_name: Balkan_Mathematical_Olympiad
data_files:
- split: train
path: data/Balkan_Mathematical_Olympiad/train-*.parquet
- config_name: Baltic_Way
data_files:
- split: train
path: data/Baltic_Way/train-*.parquet
- config_name: Belarus
data_files:
- split: train
path: data/Belarus/train-*.parquet
- config_name: Benelux_Mathematical_Olympiad
data_files:
- split: train
path: data/Benelux_Mathematical_Olympiad/train-*.parquet
- config_name: Brazil
data_files:
- split: train
path: data/Brazil/train-*.parquet
- config_name: Bulgaria
data_files:
- split: train
path: data/Bulgaria/train-*.parquet
- config_name: Canada
data_files:
- split: train
path: data/Canada/train-*.parquet
- config_name: China
data_files:
- split: train
path: data/China/train-*.parquet
- config_name: Croatia
data_files:
- split: train
path: data/Croatia/train-*.parquet
- config_name: Czech-Polish-Slovak_Mathematical_Match
data_files:
- split: train
path: data/Czech-Polish-Slovak_Mathematical_Match/train-*.parquet
- config_name: Czech_Republic
data_files:
- split: train
path: data/Czech_Republic/train-*.parquet
- config_name: Estonia
data_files:
- split: train
path: data/Estonia/train-*.parquet
- config_name: European_Girls'_Mathematical_Olympiad_EGMO
data_files:
- split: train
path: data/European_Girls'_Mathematical_Olympiad_EGMO/train-*.parquet
- config_name: France
data_files:
- split: train
path: data/France/train-*.parquet
- config_name: Germany
data_files:
- split: train
path: data/Germany/train-*.parquet
- config_name: Greece
data_files:
- split: train
path: data/Greece/train-*.parquet
- config_name: Hong_Kong
data_files:
- split: train
path: data/Hong_Kong/train-*.parquet
- config_name: IMO
data_files:
- split: train
path: data/IMO/train-*.parquet
- config_name: Ibero-American_Mathematical_Olympiad
data_files:
- split: train
path: data/Ibero-American_Mathematical_Olympiad/train-*.parquet
- config_name: India
data_files:
- split: train
path: data/India/train-*.parquet
- config_name: Iran
data_files:
- split: train
path: data/Iran/train-*.parquet
- config_name: Ireland
data_files:
- split: train
path: data/Ireland/train-*.parquet
- config_name: Italy
data_files:
- split: train
path: data/Italy/train-*.parquet
- config_name: JBMO
data_files:
- split: train
path: data/JBMO/train-*.parquet
- config_name: Japan
data_files:
- split: train
path: data/Japan/train-*.parquet
- config_name: Mexico
data_files:
- split: train
path: data/Mexico/train-*.parquet
- config_name: Middle_European_Mathematical_Olympiad_MEMO
data_files:
- split: train
path: data/Middle_European_Mathematical_Olympiad_MEMO/train-*.parquet
- config_name: Moldova
data_files:
- split: train
path: data/Moldova/train-*.parquet
- config_name: Mongolia
data_files:
- split: train
path: data/Mongolia/train-*.parquet
- config_name: Netherlands
data_files:
- split: train
path: data/Netherlands/train-*.parquet
- config_name: New_Zealand
data_files:
- split: train
path: data/New_Zealand/train-*.parquet
- config_name: Nordic_Mathematical_Olympiad
data_files:
- split: train
path: data/Nordic_Mathematical_Olympiad/train-*.parquet
- config_name: North_Macedonia
data_files:
- split: train
path: data/North_Macedonia/train-*.parquet
- config_name: Philippines
data_files:
- split: train
path: data/Philippines/train-*.parquet
- config_name: Portuguese_Language_Countries_Olympiad_OMCPLP
data_files:
- split: train
path: data/Portuguese_Language_Countries_Olympiad_OMCPLP/train-*.parquet
- config_name: Romania
data_files:
- split: train
path: data/Romania/train-*.parquet
- config_name: Romanian_Master_of_Mathematics_RMM
data_files:
- split: train
path: data/Romanian_Master_of_Mathematics_RMM/train-*.parquet
- config_name: Russia
data_files:
- split: train
path: data/Russia/train-*.parquet
- config_name: Saudi_Arabia
data_files:
- split: train
path: data/Saudi_Arabia/train-*.parquet
- config_name: Serbia
data_files:
- split: train
path: data/Serbia/train-*.parquet
- config_name: Silk_Road_Mathematics_Competition
data_files:
- split: train
path: data/Silk_Road_Mathematics_Competition/train-*.parquet
- config_name: Singapore
data_files:
- split: train
path: data/Singapore/train-*.parquet
- config_name: Slovenia
data_files:
- split: train
path: data/Slovenia/train-*.parquet
- config_name: South_Africa
data_files:
- split: train
path: data/South_Africa/train-*.parquet
- config_name: South_Korea
data_files:
- split: train
path: data/South_Korea/train-*.parquet
- config_name: Soviet_Union
data_files:
- split: train
path: data/Soviet_Union/train-*.parquet
- config_name: Spain
data_files:
- split: train
path: data/Spain/train-*.parquet
- config_name: Switzerland
data_files:
- split: train
path: data/Switzerland/train-*.parquet
- config_name: Taiwan
data_files:
- split: train
path: data/Taiwan/train-*.parquet
- config_name: Thailand
data_files:
- split: train
path: data/Thailand/train-*.parquet
- config_name: Turkey
data_files:
- split: train
path: data/Turkey/train-*.parquet
- config_name: Ukraine
data_files:
- split: train
path: data/Ukraine/train-*.parquet
- config_name: United_States
data_files:
- split: train
path: data/United_States/train-*.parquet
- config_name: Vietnam
data_files:
- split: train
path: data/Vietnam/train-*.parquet
- config_name: Zhautykov_Olympiad
data_files:
- split: train
path: data/Zhautykov_Olympiad/train-*.parquet
---
<div align="center">
<img src="assets/title_w_logo_light.png" alt="MathNet" width="960"/>
<img src="assets/overview.png" alt="MathNet overview: large-scale multilingual data, high-quality solutions, diverse topics, and three evaluation tasks" width="100%"/>
<a href="https://arxiv.org/abs/2604.18584"><img alt="ICLR 2026" src="https://img.shields.io/badge/ICLR-2026-b31b1b"></a>
<a href="https://mathnet.mit.edu"><img alt="Website" src="https://img.shields.io/badge/website-mathnet.mit.edu-0d056f"></a>
</div>
[Quick Start](#quick-start) · [Overview](#overview) · [Tasks](#three-benchmark-tasks) · [Comparison](#how-mathnet-compares-to-existing-math-benchmarks) · [Dataset Stats](#dataset-at-a-glance) · [Data Sources](#data-sources) · [Pipeline](#data-pipeline) · [Schema](#schema) · [License](#license) · [Citation](#citation)
> **This is the official MathNet v0.** A larger version **v1** will be uploaded soon (more countires, problems and richer metadata). Schema is stable but field values may be revised in v1.
---
## Quick start
```python
from datasets import load_dataset
# Default: all problems
ds = load_dataset("ShadenA/MathNet", split="train")
# Or a specific country / competition-body config
arg = load_dataset("ShadenA/MathNet", "Argentina", split="train")
apmo = load_dataset("ShadenA/MathNet", "Asia_Pacific_Mathematics_Olympiad_APMO", split="train")
row = ds[0]
print(row["competition"], row["country"])
print(row["problem_markdown"])
for img in row["images"]:
img.show() # PIL image — renders inline in the HF viewer
```
## Overview
Mathematical problem solving remains a challenging test of reasoning for large language and multimodal models, yet existing benchmarks are limited in size, language coverage, and task diversity. We introduce **MathNet**, a high-quality, large-scale, multimodal, and multilingual dataset of Olympiad-level math problems together with a benchmark for evaluating mathematical reasoning in generative models **and** mathematical retrieval in embedding-based systems.
MathNet spans **47 countries**, **17 languages**, and **two decades** of competitions, comprising **30,676 expert-authored problems with solutions** across diverse domains. Alongside the core dataset, we construct a retrieval benchmark of mathematically equivalent and structurally similar problem pairs curated by human experts.
---
## Three benchmark tasks
| | Task | What it measures |
|---|---|---|
| **I** | **Problem Solving** | Generative models on Olympiad problems, graded against expert solutions |
| **II** | **Math-Aware Retrieval** | Embedding models' ability to retrieve mathematically equivalent / structurally similar problems |
| **III** | **Retrieval-Augmented Problem Solving** | How retrieval quality affects reasoning when similar problems are given as context |
Even state-of-the-art reasoners remain challenged: **78.4% (Gemini-3.1-Pro)** and **69.3% (GPT-5)** on `MathNet-Solve-Test`. Embedding models struggle with equivalence retrieval (Recall@1 under 5% for all tested models), and RAG gains are highly sensitive to retrieval quality — expert retrieval lifts DeepSeek-V3.2-Speciale to **97.3%** on `MathNet-RAG`.
## How MathNet compares to existing math benchmarks
| Benchmark | Size | Languages | Multimodal | Source | Difficulty |
|---|---:|---|:-:|---|---|
| GSM8K | 8,500 | EN | — | Crowdsourced | Grade school |
| MATH | 12,500 | EN | — | Competitions/textbooks | High school |
| MATH-Vision | 3,040 | EN | ✓ | Math competitions | High school |
| OlympiadBench | 6,142 | EN, ZH | ✓ | Official websites | Olympiad |
| OlympicArena | 3,233 | EN, ZH | ✓ | Official websites | Olympiad |
| Omni-Math | 4,428 | EN | — | AoPS / contest pages | Olympiad |
| OlymMATH | 200 | EN, ZH | — | AoPS / official | Olympiad |
| MathArena | 162 | EN | ✓ | Newly released competitions | Olympiad |
| IMOBench | 460 | EN | — | IMO & national archives | Olympiad |
| **MathNet (ours)** | **30,676** | **17** (EN, ZH, ES, RU, FR, RO, + 11 more) | **✓** | **Official country booklets / international & national contests** | **Olympiad** |
## Dataset at a glance
<img src="assets/dataset_stats.png" alt="MathNet dataset statistics: contest types, solution length vs. prior benchmarks, problems per year, topic distribution, and language distribution" width="100%"/>
**What the figure shows.** *(a)* A mix of national, regional, TST, and international competitions. *(b)* MathNet solutions are **substantially longer** than those in prior math benchmarks — long-form proofs, not one-line answers. *(c)* Problems per year — the corpus has grown steadily since the early 2000s. *(d)* Coverage across geometry, algebra, combinatorics, number theory, and their sub-topics. *(e)* **74% English, 26% non-English** across **17 languages**; Portuguese, Spanish, French, Italian, Serbian, Slovenian, German, Chinese, Romanian, Korean, Dutch, Russian, Mongolian, Macedonian, Polish, and Hungarian all appear.
### Topic taxonomy (excerpt)
MathNet ships with a curated olympiad-style taxonomy. Top-level domains include:
- **Geometry** — plane (triangles, quadrilaterals, circles, concurrency/collinearity, transformations, Miquel/Simson/Brocard, geometric inequalities, combinatorial geometry, analytic methods), solid, differential, non-Euclidean
- **Algebra** — prealgebra, polynomials, inequalities, functional equations, sequences/series, linear algebra, abstract algebra
- **Number Theory** — divisibility, primes, modular arithmetic, Diophantine equations, quadratic residues, \(p\)-adic methods
- **Combinatorics** — counting, graph theory, extremal / pigeonhole, invariants/monovariants, games, coloring, generating functions
- **Calculus / Analysis** — limits, inequalities, real analysis, combinatorial analysis
- **Probability & Statistics** — discrete and continuous
Every problem carries a hierarchical topic path (e.g. `Geometry > Plane Geometry > Quadrilaterals > Cyclic quadrilaterals`) usable for stratified evaluation or curriculum construction.
## Data sources
Each year, participating IMO countries contribute original problems for use in their national contests and team selection examinations. MathNet is built from **official problem booklets** collected from **47 countries spanning 1985–2025** — **1,595 PDF volumes** totalling more than **25,000 pages**. Unlike prior math benchmarks that rely on community platforms such as AoPS, every problem and solution in MathNet is authored and disseminated by national teams themselves, ensuring expert-level quality, stylistic consistency, and immunity from the noisy or informal annotations that plague crowd-sourced collections.
A meaningful portion of the collection — particularly older national booklets — was physically obtained and scanned by hand by our IMO expert co-authors, who have attended the International Mathematical Olympiad since 2006 and accumulated a personal archive of official competition materials over nearly two decades.
## Data pipeline
<img src="assets/pipeline.png" alt="MathNet data extraction and curation pipeline" width="100%"/>
Extracting aligned problem–solution pairs from a heterogeneous corpus of mathematical documents is non-trivial: some booklets separate problems and solutions into different sections, others interleave them; numbering schemes and naming conventions vary across countries and even within a single document. Regex-based heuristics break down at this scale, so we designed a multi-stage LLM pipeline.
**Stage 1 — Document ingestion & segmentation.** All booklets are converted to Markdown via `dots-ocr`, a multilingual document parsing framework designed for both digital typeset PDFs and scanned copies across many languages. `Gemini-2.5-Flash` then identifies problem and solution segments by outputting only their line numbers, and records authors, hints, remarks, source file, and page numbers for provenance.
**Stage 2 — Problem–solution extraction.** Given the line segments from Stage 1, `GPT-4.1` extracts the corresponding problem and solution in LaTeX-friendly Markdown, together with a surrounding text buffer to handle cases where content spans across context boundaries.
**Stage 3 — Extraction verification.** Each extracted pair passes three independent checks before being retained:
1. **Rule-based similarity check** — text similarity between the extraction and original OCR output ensures the LLM made only formatting changes and introduced no hallucinated content.
2. **GPT-4.1-as-judge** — GPT-4.1 compares page screenshots against the extracted pair to catch OCR errors, incorrect figure associations, and incomplete solutions.
3. **Human expert review** — low-confidence cases are manually reviewed by annotators. A pair is retained only if all three mechanisms agree.
Provenance (source booklet, authors where given) is preserved on every problem.
## What v0 contains
This is the **v0 drop** of MathNet — the first complete public release:
- **27,817 problems** across **58 country / regional-body configs**
- **5,148 problems with figures**, totalling **7,541 images** embedded inline as HF `Image()` features (they render in the viewer and decode to PIL on load)
- All image references in problem and solution markdown are rewritten to the uniform `` convention and the corresponding bytes ship in the `images` column in the same order
- Default `all` config opens with a curated head of ~120 country-diverse, figure-rich problems so the dataset viewer preview is visually representative; the remainder of `all` is shuffled
A more refined **v1** — larger, with improved extraction, deduplication, and metadata — will be uploaded by **Friday, April 24, 2026**.
## Schema
| Column | Type | Notes |
|---|---|---|
| `id` | string | Short 4-char base36 identifier, stable across rebuilds |
| `country` | string | Country or regional body of origin |
| `competition` | string | e.g. `IMO 2023`, `Cono Sur Mathematical Olympiad` |
| `problem_markdown` | string | Problem statement (Markdown + LaTeX) with `` refs |
| `solutions_markdown` | list<string> | Official / provided solutions, one entry per solution |
| `topics_flat` | list<string> | Hierarchical topic paths joined as `A > B > C` |
| `language` | string | Source booklet language |
| `booklet_source` | string | Upstream collection label |
| `images` | list<Image> | Inlined figure bytes, decoded to PIL; positions align with `attached_image_N.png` refs in the markdown |
| `problem_type` | string\|null | `proof only`, `answer only`, `proof and answer` — LLM-assisted |
| `final_answer` | string\|null | LLM-extracted final answer for answer-bearing problems |
> `problem_type` and `final_answer` are **LLM-assisted** and not fully human-audited in v0. Treat them as convenience annotations, not ground truth.
## Configs / splits
One config per **country or regional body** (58 total) plus a default `all` config unioning everything. Each config has a single `train` split — this is the public v0 release, not the train/test partitioning of `MathNet-Solve` (which is `train: 23,776`, `test: 6,400`, `test-hard: 500` in the paper release).
## Intended uses & limitations
**Good for.** Olympiad-level reasoning evaluation, multilingual math evaluation, figure-grounded multimodal math, topic-stratified analysis, retrieval benchmarks over mathematical structure, and **RL training** — the large pool of expert-written solutions provides dense rewards for verifiable-answer problems, while the math-aware similarity pairs open a new axis: rewarding a model for retrieving a structurally equivalent problem is a natural, automatically verifiable signal that does not require a closed-form answer.
**Caveats.**
- **Not contamination-clean.** Olympiad problems are indexed widely; assume leakage when evaluating pretrained models.
- **v0 field values may be revised in v1** (improved extraction / dedup / metadata).
- **LLM-assisted metadata is imperfect.**
## License
With the kind support of IMO President Gregor Dolinar, we reached out to the leaders of all participating countries and obtained their permission to share this dataset publicly. Where a country or contest organization asserts its own copyright, that copyright is retained and takes precedence — see `competition`, `country`, and `booklet_source` on each row. For all remaining problems where no explicit copyright was asserted, the dataset is released under **[Creative Commons Attribution 4.0 International (CC BY 4.0)](https://creativecommons.org/licenses/by/4.0/)**.
In short: use freely, cite the paper, and respect any explicit rights claimed by the original national team.
If you are a rightsholder with a concern, please open an issue or email [shaden@mit.edu](mailto:shaden@mit.edu).
## Citation
```bibtex
@inproceedings{alshammari2026mathnet,
title = {MathNet: A Global Multimodal Benchmark for Mathematical
Reasoning and Retrieval},
author = {Alshammari, Shaden and Wen, Kevin and Zainal, Abrar and
Hamilton, Mark and Safaei, Navid and Albarakati, Sultan and
Freeman, William T. and Torralba, Antonio},
booktitle = {International Conference on Learning Representations},
year = {2026},
url = {https://mathnet.mit.edu}
}
```
## Links
- 🌐 **Website & paper:** <https://mathnet.mit.edu>
- 🔭 **Browse all 30K problems:** <https://mathnet.mit.edu/explorer.html>
- ✉️ **Contact:** [shaden@mit.edu](mailto:shaden@mit.edu)
<p align="center"><sub>© 2026 Massachusetts Institute of Technology · MathNet · ICLR 2026</sub></p>
MathNet v0 is a high-quality, large-scale, multimodal, and multilingual dataset of Olympiad-level math problems designed to evaluate mathematical reasoning in generative models and mathematical retrieval in embedding-based systems. The dataset comprises 30,676 expert-authored problems with solutions across 47 countries and 17 languages, covering diverse domains such as geometry, algebra, number theory, and combinatorics. It also includes a retrieval benchmark of mathematically equivalent and structurally similar problem pairs curated by human experts. This initial public release (v0) contains 27,817 problems, with 5,148 problems including figures (totaling 7,541 images). The dataset supports multiple tasks, including problem solving, math-aware retrieval, and retrieval-augmented problem solving.
提供机构:
Bacon935
搜集汇总
数据集介绍
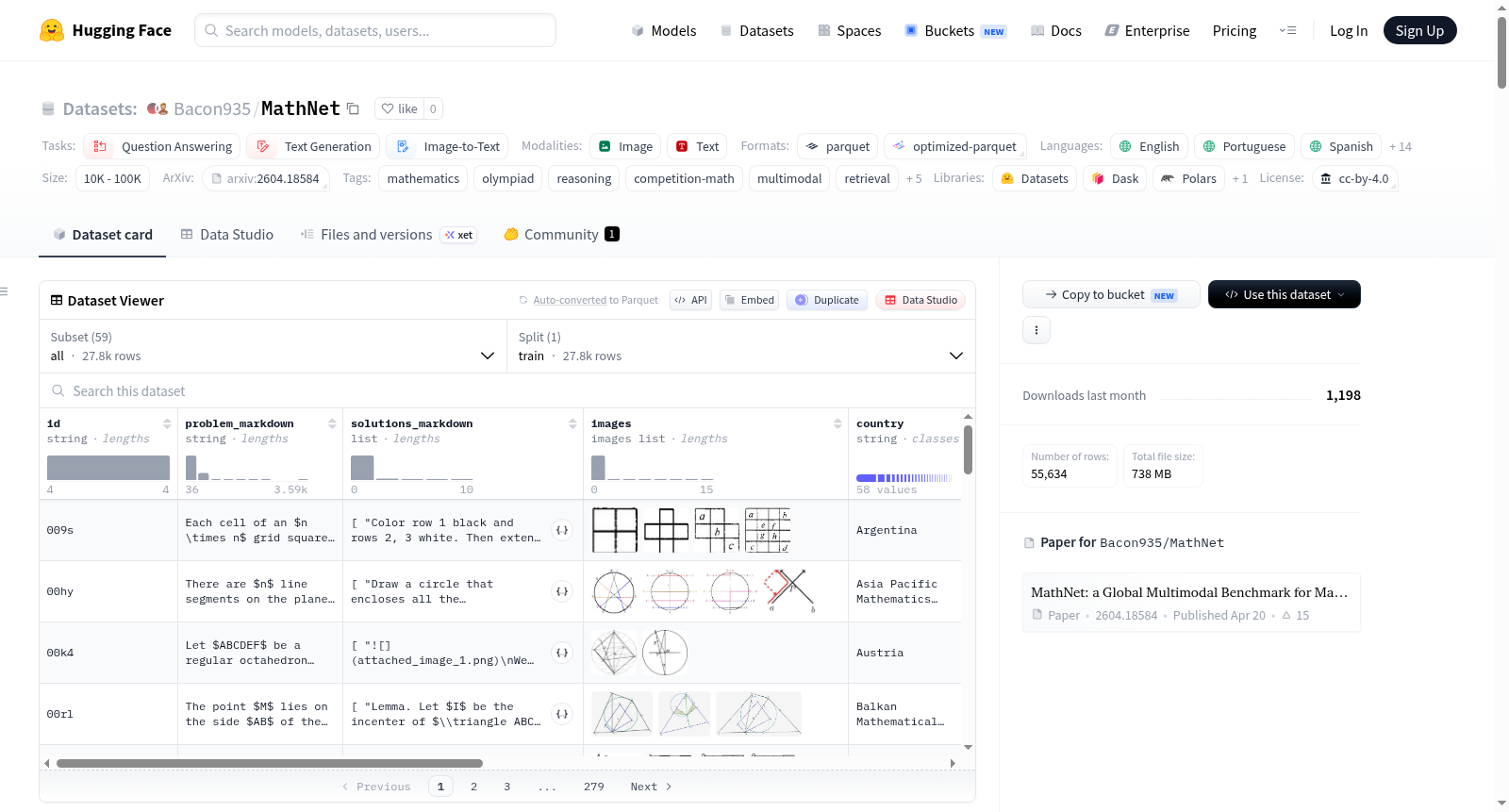
构建方式
在数学推理数据集构建领域,MathNet另辟蹊径,依托于国际数学奥林匹克(IMO)这一权威竞赛体系进行数据采集。数据集构建团队与各参赛国领队建立合作,系统收集了来自47个国家、横跨1985至2025年的1,595份官方竞赛手册,累计超过25,000页。这些手册中的问题与解答均由国家代表队专家撰写,确保了数据的专业性与权威性。针对手册格式异构、语言多样、年份跨度大的挑战,团队设计了一套三阶段LLM流水线:首先利用多语言文档解析框架将PDF转为Markdown,再由Gemini识别问题与解答段落,随后由GPT-4.1进行精细化内容提取,最后通过规则校验、GPT-4.1评判及人工审核三重验证机制确保数据质量。
特点
MathNet以其卓越的综合性在同类数据集中独树一帜。数据集体量宏大,包含30,676个奥林匹克级数学问题及专家编写的完整解答,覆盖平面几何、代数、数论、组合数学等核心领域。多模态特性是其另一亮点,其中5,148个问题配有7,541张图表,以标准化内嵌图片格式呈现。语言多样性的突破尤为显著,语种横跨英文、中文、俄语等17种语言,非英文内容占比达26%,远超现有基准。数据集中每个问题均携带分层主题标签,支持按知识领域进行细粒度评估。相较于其他基准,MathNet的解答以长篇证明为主,对模型的深度推理能力提出了更高要求。
使用方法
MathNet的使用方式灵活多样,通过HuggingFace datasets库即可便捷加载。研究人员可选择一键加载全部数据,也可按国家或竞赛名称指定特定配置,例如单独加载阿根廷赛题或亚太数学奥林匹克赛题。数据集为三大评测任务度身定制:在解题任务中,评估生成模型对奥林匹克问题的求解能力;在数学感知检索任务中,衡量嵌入模型召回数学等价问题的准确率;在检索增强解题任务中,则考察检索质量对推理效果的影响。数据集中每个样本均包含问题陈述、官方解答、主题标签、来源语言及原始手册出处等结构化字段,便于进行多维度分析与实验复现。
背景与挑战
背景概述
MathNet数据集由MIT研究人员Shaden Alshaikh等人于2026年构建,旨在解决大型语言与多模态模型在奥林匹克级数学推理中面临的评测瓶颈。现有数学基准如GSM8K、MATH等受限于规模、语言覆盖单一及任务维度匮乏,难以全面衡量模型的深层推理能力。MathNet依托国际数学奥林匹克(IMO)官方渠道,汇聚47个国家、17种语言、横跨1985至2025年的30,676道专家编写题目与解答,其数据来源为各国官方试题手册,经人工扫描与多阶段LLM管道提取,确保了内容的权威性与学术严谨性。该数据集已被ICLR 2026收录,为数学推理与检索研究提供了迄今为止规模最大、语言最多样化的评测平台。
当前挑战
MathNet所应对的核心领域挑战在于现有基准难以评估模型在高度抽象、多步推理的奥林匹克级数学问题上的表现,尤其是在多语言与多模态环境下,模型常因符号理解偏差或表象相似性误导而错失本质等价关系。构建过程中面临的挑战包括:从1,595卷、逾25,000页异构PDF中精准提取问题-解答对,面对各国编号与排版差异,传统正则方法全面失效;需设计专有OCR与LLM协同管道完成文档分割、内容提取及三重校验(规则相似性、GPT-4.1图像比对、人工专家审核),以滤除OCR误差与幻觉;同时解决泛领域版权许可问题,经IMO主席沟通协调获得各国授权。
常用场景
经典使用场景
在数学推理与多模态理解领域,MathNet数据集的核心经典用途之一在于评估和推动大规模语言模型与多模态模型在奥林匹克级数学问题上的表现能力。该数据集涵盖了47个国家、17种语言及跨越二十余年的竞赛题目,提供了超过30,000道专家级别的问题与详细解答。因此,研究者常利用MathNet构建统一的评估框架,以衡量模型在复杂数学推理任务中的鲁棒性与泛化能力,尤其是在涉及图形、表格和公式等非纯文本信息的多模态场景中。
解决学术问题
MathNet数据集显著解决了现有数学推理基准规模有限、语言覆盖度匮乏以及任务类型单一等学术瓶颈。通过整合海量官方竞赛材料并确保每道题目的核心解法均由专家撰写,该数据集能够有效服务于模型在长链条逻辑推演和结构性证明中的能力检验。其存在推动了科研界对于模型从简单答案生成向深层推理机制的关注,更加深刻地揭示了即使当前最先进的推理模型在面对复杂的数学证明题时仍存在的显著不足,从而激发了新一轮的算法创新。
衍生相关工作
围绕MathNet数据集,学术界已衍生出多项具有深远影响的经典工作,其中包括构建精确的数学结构检索基准和检索增强型问题解决任务。具体而言,研究者提出了面向嵌入模型的等值性和结构相似性检索任务,挑战模型在海量数学题库中进行精确匹配的能力;同时还定义了检索增强求解任务,以探究上下文相关题目对模型推理表现的影响。这些衍生工作不仅验证了专家级检索能大幅提升模型解题成功率,也揭示了当前语义嵌入模型在数学等价性问题上的深刻局限,从而催生了一系列针对数学语义空间的表示学习与评估新方法。
以上内容由遇见数据集搜集并总结生成


