eval_exp5-79999_5shot_3exp
收藏Hugging Face2025-07-19 更新2025-07-20 收录
下载链接:
https://huggingface.co/datasets/pt-eval/eval_exp5-79999_5shot_3exp
下载链接
链接失效反馈官方服务:
资源简介:
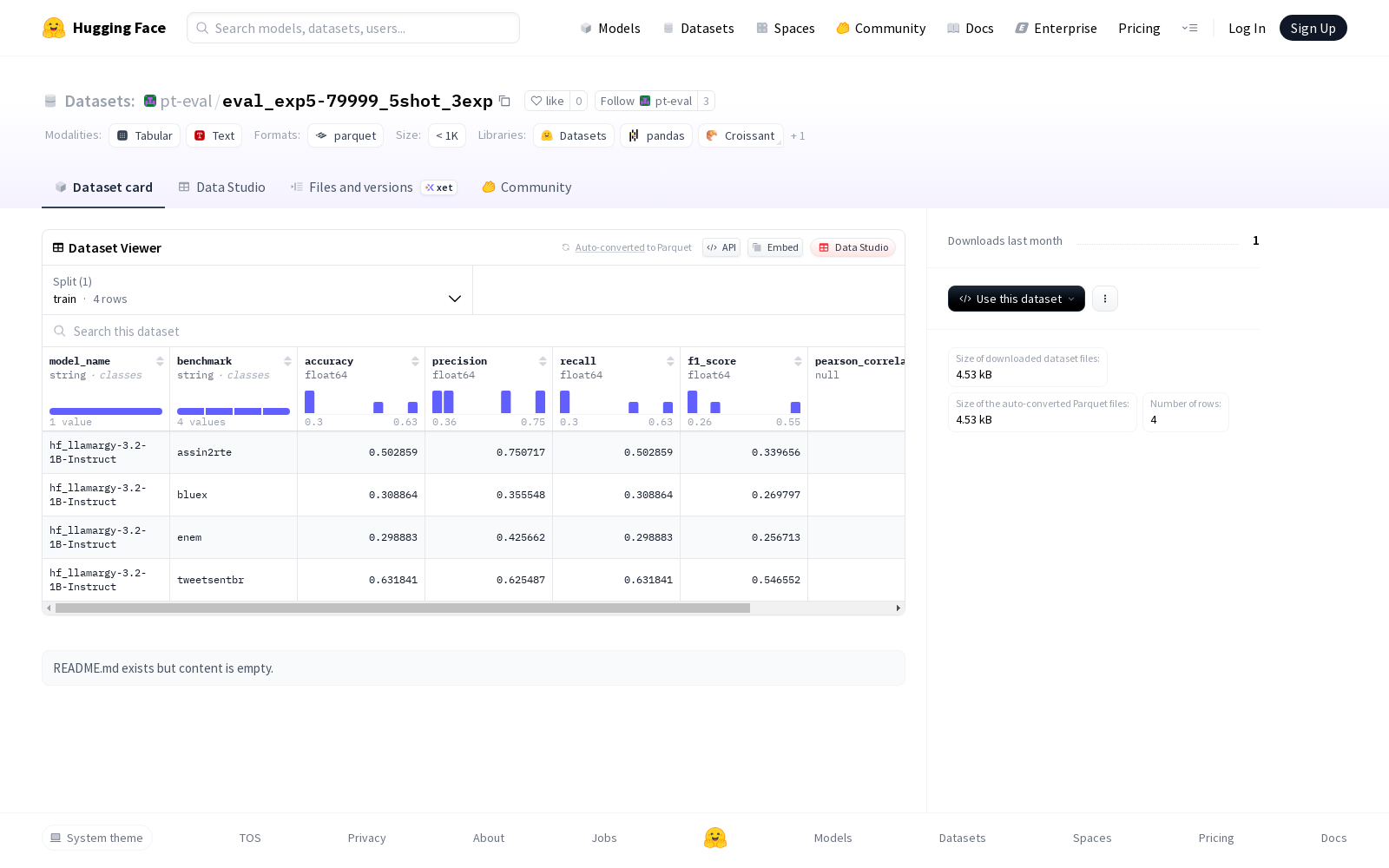
该数据集包含模型性能相关的指标数据,如模型名称、基准、准确度、精确度、召回率、F1分数、未解析率等。数据集分为训练集,包含若干示例,用于训练机器学习模型。数据集以特定的文件格式存储,可以通过指定的路径访问。
This dataset contains indicator data related to model performance, such as model name, benchmark, accuracy, precision, recall, F1-score, unparsed rate, and other relevant metrics. The dataset is divided into a training set which includes multiple examples for training machine learning models. It is stored in a specific file format and can be accessed via a designated path.
创建时间:
2025-07-19
原始信息汇总
数据集概述
基本信息
- 数据集名称: pt-eval/eval_exp5-79999_5shot_3exp
- 下载大小: 4527字节
- 数据集大小: 329字节
数据集结构
-
特征:
model_name: 字符串类型benchmark: 字符串类型accuracy: 浮点数类型precision: 浮点数类型recall: 浮点数类型f1_score: 浮点数类型pearson_correlation: 空值类型non_parsed_rate: 浮点数类型
-
数据划分:
train:- 字节数: 329
- 样本数: 4
配置信息
- 配置名称: default
- 数据文件:
- 划分: train
- 路径: data/train-*
搜集汇总
数据集介绍
构建方式
在人工智能模型评估领域,eval_exp5-79999_5shot_3exp数据集通过系统化实验设计构建而成。该数据集采集了多个模型在基准测试中的性能指标,采用结构化数据记录方式,涵盖准确率、精确度、召回率和F1分数等核心评估维度。数据来源于严格控制下的模型测试过程,确保每项指标的可追溯性和计算一致性,为模型性能分析提供可靠的数据基础。
特点
本数据集最显著的特征在于其多维度的评估指标体系,不仅包含传统的分类性能指标,还特别记录了模型解析失败率这一实用参数。数据集采用紧凑的表格形式组织,每个样本对应一个模型在特定基准测试中的完整评估结果。虽然数据规模较小,但字段设计精炼且具有高度一致性,所有数值型指标均采用标准化计算方式,便于进行横向对比分析。
使用方法
研究人员可通过加载该数据集直接获取模型性能对比数据,适用于机器学习模型的快速评估和基准测试。使用时应重点关注各指标间的关联性分析,如准确率与F1分数的协同变化趋势。数据集支持直接导入常见的数据分析框架,用户可基于提供的指标进行可视化分析或构建模型性能雷达图,为模型优化提供量化依据。需要注意的是,使用时应考虑数据样本量限制,建议结合其他数据集进行综合分析。
背景与挑战
背景概述
eval_exp5-79999_5shot_3exp数据集诞生于人工智能模型评估领域快速发展的背景下,由研究团队为系统化测试少样本学习能力而构建。该数据集聚焦于多维度性能度量,涵盖准确率、精确度、召回率及F1分数等关键指标,旨在为生成式模型与分类模型提供标准化评估框架。其设计反映了当前对模型鲁棒性与泛化能力的高标准需求,通过对不同benchmark的集成,推动了模型评估方法论的科学化与精细化发展。
当前挑战
该数据集核心挑战在于解决少样本学习场景下模型性能评估的标准化问题,需应对高方差指标稳定性和跨任务泛化能力量化等难点。构建过程中面临多模态指标对齐与数据稀疏性处理的技术难题,例如非解析率(non_parsed_rate)的精确计量要求复杂的异常值处理机制,而缺失的皮尔逊相关性字段则需通过多源数据融合来保证评估体系的完整性。
常用场景
经典使用场景
在自然语言处理模型的系统性评估领域,eval_exp5-79999_5shot_3exp数据集通过提供多维度性能指标,成为验证模型在少样本学习环境下泛化能力的经典工具。研究者通常借助该数据集对比不同模型在相同基准测试中的表现,特别关注其在小样本情境下的准确率、F1值等核心指标,从而客观评估模型的实际推理能力与稳定性。
解决学术问题
该数据集有效解决了少样本学习场景下模型评估标准不统一的问题,通过整合准确率、精确率、召回率和F1分数等多项指标,为学术研究提供了可量化的性能对比框架。其意义在于建立了标准化评估范式,使得研究者能够跨模型比较小样本学习效果,推动了对模型泛化机制和样本效率的深入探索。
衍生相关工作
基于该数据集的评估范式,衍生出多项经典研究工作,包括小样本学习框架FSL-Metric、跨任务泛化评估工具ChainEval等。这些工作进一步扩展了评估维度,引入了动态难度调整和领域适应性测试,推动了评估方法学从单一指标向多维度、场景化的方向发展。
以上内容由遇见数据集搜集并总结生成


