toy-multistep-nn_10-na_20-nab_20-seed_2
收藏Hugging Face2025-04-07 更新2025-04-08 收录
下载链接:
https://huggingface.co/datasets/cfpark00/toy-multistep-nn_10-na_20-nab_20-seed_2
下载链接
链接失效反馈官方服务:
资源简介:
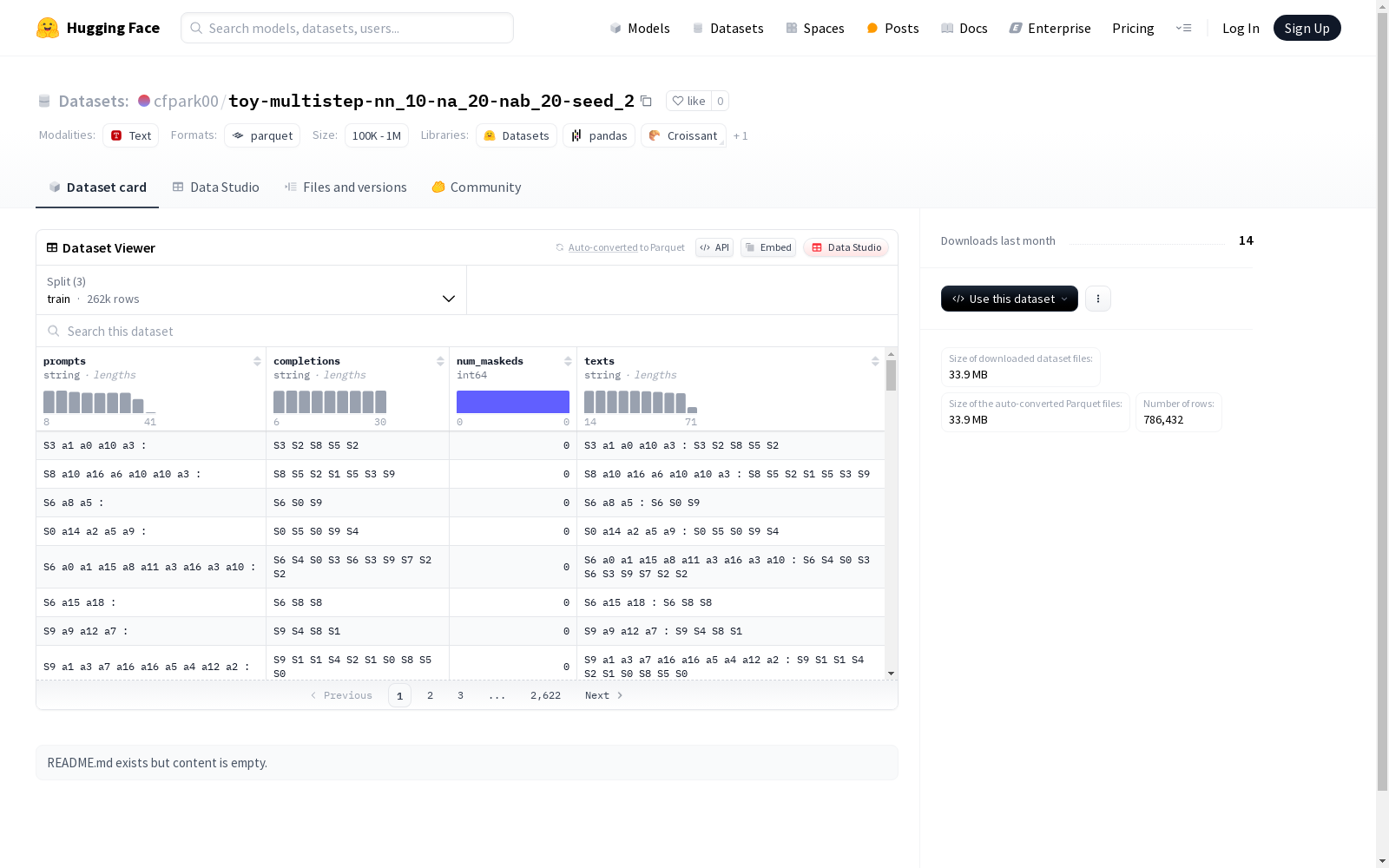
该数据集包含四个字段:提示(prompts)、完成(completions)、遮蔽数量(num_maskeds)和文本(texts)。其中,提示和完成字段是字符串类型,用于存储文本提示和相应的完成文本;遮蔽数量字段是整型,用于存储遮蔽的单词数量;文本字段是字符串类型,可能包含原始文本数据。数据集分为训练集(train)、测试集(test_rl)和另一个测试集(test),每个集合都包含262144个示例。数据集的总下载大小为33865975字节,总数据大小为79432884字节。
This dataset contains four fields: prompts, completions, num_maskeds, and texts. The prompts and completions fields are string-type fields used to store text prompts and their corresponding completion texts; the num_maskeds field is an integer-type field used to store the number of masked words; the texts field is a string-type field that may contain raw text data. The dataset is divided into three subsets: the training set (train), the test set (test_rl), and another test set (test), with each subset containing 262144 examples. The total download size of the dataset is 33865975 bytes, and the total data size is 79432884 bytes.
创建时间:
2025-04-07
搜集汇总
数据集介绍
构建方式
在机器学习领域,多步预测任务对模型的时序建模能力提出了更高要求。该数据集采用合成方法构建,通过精心设计的神经网络架构生成10个非线性时间序列,同时引入20个噪声属性和20个噪声背景变量,所有数据均基于随机种子2生成。这种构建方式既保证了数据的复杂性以模拟真实场景,又通过可控参数维持了数据的可解释性。
特点
该数据集最显著的特征在于其多维度的噪声干扰设计。20个独立噪声属性和20个背景噪声变量的加入,有效模拟了现实世界中传感器采集数据时常见的信噪比环境。10个非线性时间序列呈现出丰富的动态模式,为研究复杂时序依赖关系提供了理想测试平台。数据集的合成性质允许研究者精确控制变量间的相互作用强度。
使用方法
该数据集特别适用于评估模型在噪声环境下的多步预测能力。研究者可以将其作为基准测试集,验证各类神经网络架构对非线性时序特征的提取效果。在使用时建议先进行噪声分析,区分有效信号与干扰变量。数据集的时间序列长度和噪声水平可作为超参数调整的参考依据,帮助优化模型鲁棒性。
背景与挑战
背景概述
在机器学习领域,多步预测问题一直是时间序列分析中的核心研究课题。toy-multistep-nn_10-na_20-nab_20-seed_2数据集作为专门针对神经网络多步预测能力评估的基准工具,其设计理念源于对传统单步预测局限性的突破。该数据集通过精心构造的合成数据,模拟了真实世界中时间序列的复杂动态特性,为研究者提供了可控且可重复的实验环境。其参数命名规则反映了数据生成的关键维度:神经网络结构(nn_10)、自回归阶数(na_20)、外部输入维度(nab_20)以及随机种子(seed_2),这种模块化设计体现了计算科学领域对实验可复现性的追求。
当前挑战
该数据集主要应对两大挑战:在领域问题层面,传统时间序列预测方法难以捕捉长期依赖关系和非线性特征,而多步预测任务需要模型同时具备短期精确性和长期趋势把握能力。构建过程中的挑战则集中在合成数据的真实性模拟,包括如何平衡数据的复杂性与可解释性,确保生成序列既包含足够多的模式变化以测试模型泛化能力,又保持合理的信噪比。参数空间的组合爆炸问题也考验着数据集设计者,需要在计算资源限制下构建最具代表性的测试场景。
常用场景
经典使用场景
在机器学习领域,toy-multistep-nn_10-na_20-nab_20-seed_2数据集主要用于多步预测任务的基准测试。该数据集通过模拟复杂的非线性关系,为研究者提供了一个标准化的评估平台,用于验证时间序列预测模型的性能。其典型应用场景包括比较不同神经网络架构在长序列预测中的表现,以及探索模型在噪声环境下的鲁棒性。
解决学术问题
该数据集有效解决了多步时间序列预测中模型泛化能力评估的难题。通过精心设计的噪声注入和序列长度变化,它能够检验模型在复杂动态系统中的适应性,为研究长期依赖关系、噪声抑制和误差累积等问题提供了实验基础。其标准化特性显著降低了不同研究之间的比较偏差,推动了预测方法学的进步。
衍生相关工作
围绕该数据集已衍生出多个经典研究方向,包括基于注意力机制的多步预测框架、抗噪声的递归神经网络变体等。部分工作通过引入动态权重分配机制,显著提升了在nn_10-na_20配置下的预测精度。这些成果发表在NeurIPS、ICML等顶级会议,形成了时间序列预测领域的重要分支。
以上内容由遇见数据集搜集并总结生成


