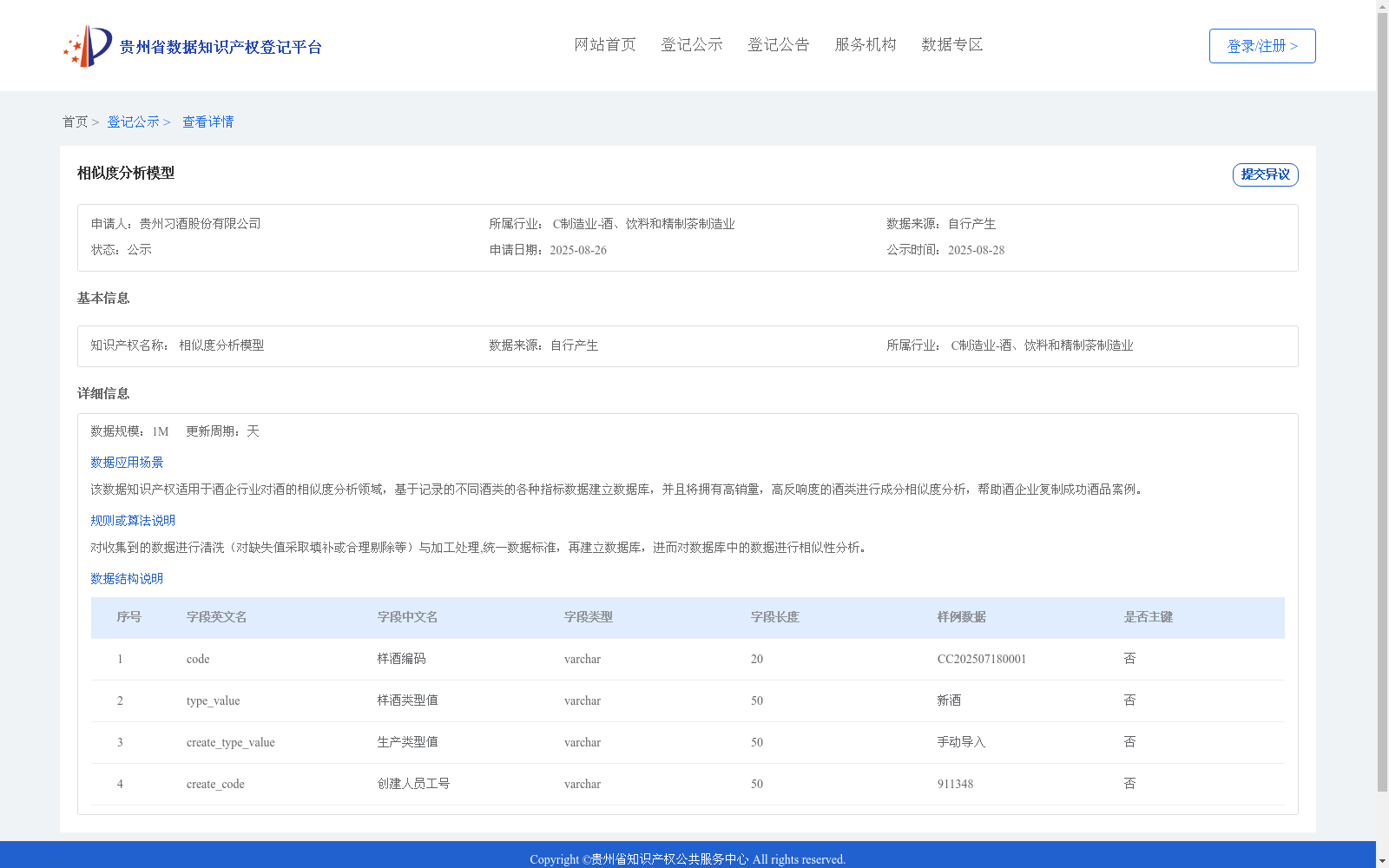
相似度分析模型
收藏贵州省数据知识产权登记平台2025-08-28 更新2025-08-29 收录
下载链接:
https://gzdipp.gzsis.cn:12020/noticeDetail?id=937&type=1
下载链接
链接失效反馈官方服务:
资源简介:
对收集到的数据进行清洗(对缺失值采取填补或合理剔除等)与加工处理,统一数据标准,再建立数据库,进而对数据库中的数据进行相似性分析。
The process involves first cleaning and preprocessing the collected data, such as imputing missing values or reasonably excluding them, unifying the data standards, then establishing a database, and finally conducting similarity analysis on the data within the database.
提供机构:
贵州习酒股份有限公司
创建时间:
2025-08-26
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是酒类制造业专用的相似度分析模型,通过1M规模的数据每日更新,对酒类成分指标进行标准化处理和相似性匹配。其核心价值在于帮助酒企通过数据分析复制成功产品案例,数据结构包含样酒编码、类型值等关键字段。
以上内容由遇见数据集搜集并总结生成


