GateNLP/broad_twitter_corpus
收藏Hugging Face2022-07-01 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/GateNLP/broad_twitter_corpus
下载链接
链接失效反馈官方服务:
资源简介:
Broad Twitter Corpus是一个包含推文的语料库,旨在代表广泛的社交媒体活动,特别是推文中的命名实体识别(NER)。该数据集包含来自英国、美国、澳大利亚、加拿大、爱尔兰和新西兰的英语推文,并标注了命名实体。数据集的结构包括数据实例、数据字段和数据分割。数据集的创建过程、注释过程、个人和敏感信息等方面的详细信息尚未提供。
Broad Twitter Corpus is a corpus containing tweets, which aims to represent a wide range of social media activities, especially for named entity recognition (NER) on tweets. This dataset includes English tweets from the United Kingdom, the United States, Australia, Canada, Ireland and New Zealand, with named entities annotated. The dataset is structured with data instances, data fields and data splits. Detailed information regarding the dataset's creation process, annotation process, personal and sensitive information and other relevant aspects has not been provided.
提供机构:
GateNLP
原始信息汇总
数据集概述
数据集名称
- 名称: Broad Twitter Corpus
- 别名: BTC
数据集基本信息
- 语言: 英语 (
bcp47:en) - 许可证: Creative Commons Attribution 4.0 International (CC BY 4.0)
- 多语言性: 单语种
- 大小: 100K<n<1M
- 源数据: 原始数据
- 任务类别: 词元分类
- 任务ID: 命名实体识别
- 论文代码ID: broad-twitter-corpus
数据集描述
- 摘要: Broad Twitter Corpus是一个包含多种时间、地点和社会用途的推文数据集,旨在代表广泛的活动,提供一个更能代表这种最难处理的社交媒体格式所使用的语言的数据集。此外,BTC还进行了命名实体的标注。
- 支持任务:
- 命名实体识别
- 数据结构:
- 文档数: 9,551
- 词元数: 165,739
- 人物实体数: 5,271
- 地点实体数: 3,114
- 组织实体数: 3,732
- 数据字段:
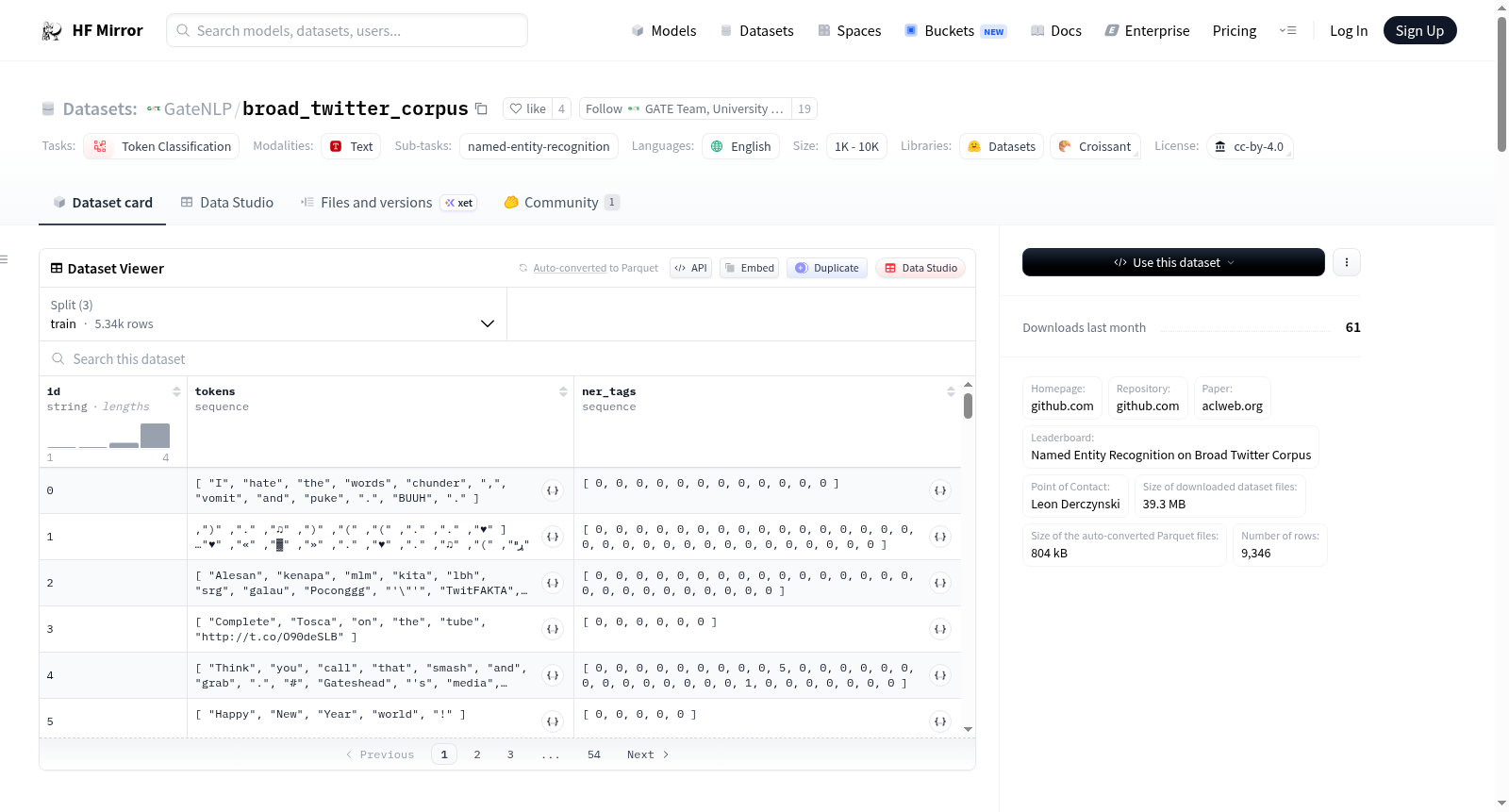
id: 字符串类型tokens: 字符串列表ner_tags: 整数列表,表示NER类别
- 数据分割:
- 测试集: 部分F
- 开发集: 部分H
- 训练集: 其他所有部分
数据集创建
-
许可证信息: Creative Commons Attribution 4.0 International (CC BY 4.0)
-
引用信息:
@inproceedings{derczynski2016broad, title={Broad twitter corpus: A diverse named entity recognition resource}, author={Derczynski, Leon and Bontcheva, Kalina and Roberts, Ian}, booktitle={Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers}, pages={1169--1179}, year={2016} }
数据集使用注意事项
- 数据集的社交影响、偏见讨论及其他已知限制: 需要更多信息
- 数据集的贡献者: Leon Derczynski (@leondz)
搜集汇总
数据集介绍
构建方式
在社交媒体自然语言处理领域,Broad Twitter Corpus的构建体现了对数据多样性的深刻考量。该数据集通过分层抽样策略,从不同时间、地域及社交用途中采集了9551条英文推文,涵盖了英国、美国、澳大利亚等多个英语国家的内容。数据标注过程融合了专家与众包的双重机制,针对人名、地名及机构名三类实体进行了精细的序列标注,最终形成了包含165739个词元的大规模语料库,旨在克服推特文本中非正式语言与噪声带来的处理挑战。
特点
该数据集的核心特征在于其广泛的社会语言覆盖与结构化的标注体系。语料囊括了从日常交流到新闻事件、社会名流乃至突发灾难等多种语境下的推文,确保了语言风格的多元性。标注体系采用经典的BIO格式,区分了PER、LOC、ORG三类实体的边界与内部结构,为命名实体识别任务提供了清晰的标准。数据划分依据推文的来源与主题分为六个独立章节,其中F章节与H章节分别作为测试集与开发集,其余部分构成训练集,这种设计有助于评估模型在不同社会语言场景下的泛化能力。
使用方法
研究者可通过HuggingFace平台直接加载GateNLP/broad_twitter_corpus数据集,利用其预定义的训练、开发与测试划分进行模型训练与评估。数据以JSON格式存储,每条记录包含推文ID、词元列表及对应的NER标签序列,用户可轻松转换为CoNLL格式以适配主流工具。该数据集适用于命名实体识别模型的开发,尤其在社交媒体文本的实体抽取研究中具有重要价值,其分层结构允许针对特定偏差进行分析,为探索社会语言变异对NLP性能的影响提供了实证基础。
背景与挑战
背景概述
社交媒体文本分析在自然语言处理领域占据重要地位,其中推特(Twitter)作为信息传播的典型平台,其语言风格独特且充满挑战。Broad Twitter Corpus(BTC)由Leon Derczynski、Kalina Bontcheva和Ian Roberts等研究人员于2016年创建,旨在解决推特文本中命名实体识别(NER)的难题。该数据集通过分层采集策略,覆盖了不同时间、地域和社会用途的推文,力求全面反映社交媒体语言的多样性。其发布不仅丰富了命名实体识别的研究资源,还为处理非正式、动态性强的文本提供了重要基准,推动了社交媒体自然语言处理技术的发展。
当前挑战
Broad Twitter Corpus面临的挑战主要体现在两个方面。在领域问题层面,推特文本包含大量非标准语言、缩写、俚语和动态新词,这给命名实体识别带来了语义模糊性和上下文依赖性的难题,传统模型难以准确捕捉实体边界和类别。在构建过程中,数据采集需平衡时间、地点和社会用途的多样性,以避免样本偏差;同时,标注工作依赖专家与众包结合,但推特中实体表达的灵活性和噪声干扰,使得标注一致性与质量控制成为显著挑战,影响了数据集的可靠性与泛化能力。
常用场景
经典使用场景
在社交媒体自然语言处理领域,Broad Twitter Corpus作为一项关键资源,其经典使用场景集中于命名实体识别任务。该数据集通过精心设计的采样策略,覆盖了不同时间、地域及社交用途的推文,为研究者提供了高度多样化的文本样本。这种设计使得模型能够学习并适应社交媒体中非正式、动态变化的语言表达,从而在实体识别任务上展现出更强的泛化能力。
解决学术问题
该数据集有效解决了社交媒体文本中命名实体识别面临的若干核心学术挑战。传统实体识别模型在规范文本上表现优异,却难以应对推文中普遍存在的拼写变异、俚语使用及语境模糊等问题。Broad Twitter Corpus通过提供大规模、多样化且经过精细标注的推文数据,为开发鲁棒性更强的实体识别算法奠定了实证基础,推动了社交媒体信息抽取技术的理论进展。
衍生相关工作
该数据集的发布催生了一系列经典研究工作,尤其在社交媒体命名实体识别领域。后续研究不仅围绕提升模型在推文上的识别精度展开,还深入探讨了跨领域迁移学习、少样本学习以及噪声标签处理等前沿方向。这些工作进一步扩展了数据集的学术价值,并推动了诸如BERT、RoBERTa等预训练语言模型在社交媒体文本上的适配与优化。
以上内容由遇见数据集搜集并总结生成


