TreeCorpus
收藏Hugging Face2025-04-08 更新2025-04-09 收录
下载链接:
https://huggingface.co/datasets/akkiisfrommars/TreeCorpus
下载链接
链接失效反馈官方服务:
资源简介:
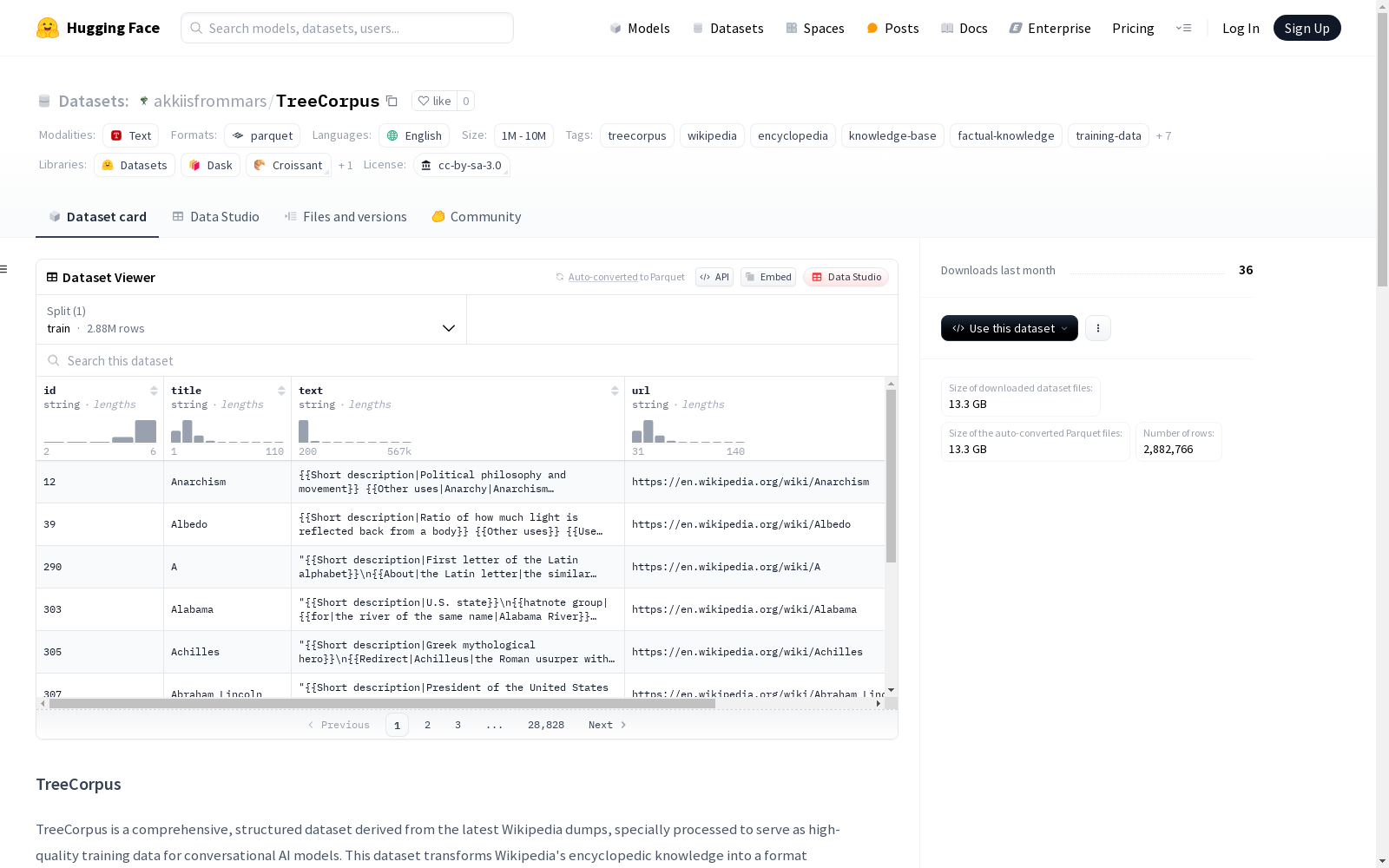
TreeCorpus是一个从最新维基百科快照中派生出来的综合结构化数据集,专为对话AI模型提供高质量训练数据。该数据集将维基百科的百科全书知识转化为优化后的自然语言理解和生成任务格式。每个条目都包括文章ID、标题、清洁文本内容、源URL和时间戳。数据集涵盖了近300万篇文章,内容经过精心处理,去除了标记、模板、引用等非内容元素,同时保留了信息价值。它还具备对话优化性,支持对话系统、会话代理和知识感知语言模型的训练。
TreeCorpus is a comprehensive structured dataset derived from the latest Wikipedia snapshot, designed to provide high-quality training data for conversational AI models. This dataset transforms the encyclopedic knowledge from Wikipedia into optimized formats for natural language understanding and generation tasks. Each entry includes article ID, title, cleaned text content, source URL, and timestamp. The dataset covers nearly 3 million articles, whose content has been meticulously processed to remove non-content elements such as markup, templates, and citations while preserving informational value. It also features conversational optimization, supporting the training of dialogue systems, conversational agents, and knowledge-aware language models.
创建时间:
2025-04-03
搜集汇总
数据集介绍
构建方式
TreeCorpus数据集通过系统化的知识抽取流程构建而成,其核心来源于维基百科最新的数据快照。构建过程采用专业化的多阶段处理管道:首先获取维基百科的原始XML数据,经过深度解析提取有效文章内容;随后运用先进的文本清洗技术去除标记语言、模板及非内容元素,同时保留完整的知识结构;最终将处理后的数据规范化为包含唯一标识符、标题、纯净文本等元信息的标准化格式,并严格过滤重定向页面和存根条目,确保数据质量。
特点
该数据集最显著的特征在于其结构化的知识呈现方式与对话优化的设计理念。26GB的体量涵盖近300万篇经过深度清洗的英文条目,每篇均附带完整的元数据体系。文本内容经过特殊处理,在去除维基百科特有标记的同时,完整保留了原始知识密度,特别适合需要事实性基础的对话系统训练。数据覆盖范围横跨人类知识的各个领域,且通过定期更新机制保持与维基百科的同步,为语言模型提供了时效性良好的知识基底。
使用方法
TreeCorpus主要服务于知识密集型自然语言处理任务的应用场景。研究人员可直接将其作为预训练语料注入大型语言模型,增强模型的事实性知识储备;在对话系统开发中,该数据集能有效支撑知识驱动的应答生成模块;对于问答系统构建者而言,结构化元数据与纯净文本的结合为精准答案检索提供了理想素材。使用时应遵循CC BY-SA 3.0许可协议,同时注明数据来源维基百科及本数据集。
背景与挑战
背景概述
TreeCorpus数据集作为自然语言处理领域的重要资源,诞生于人工智能对结构化知识需求的背景下,由专业团队基于维基百科最新数据构建而成。该数据集将维基百科的海量百科全书内容转化为适合对话式AI模型训练的优化格式,涵盖了近300万篇英文文章,总规模达26.27GB。其核心价值在于为知识密集型语言理解与生成任务提供高质量的训练数据,显著提升了对话系统在事实性知识获取与表达方面的能力。该数据集的创建标志着大规模知识库与语言模型训练结合的里程碑,对推动知识增强型人工智能的发展具有深远影响。
当前挑战
TreeCorpus数据集面临的主要挑战体现在两个维度:在领域问题层面,如何准确捕捉维基百科中复杂的知识结构并转化为适合语言模型学习的表示形式,这涉及到知识粒度划分与语义连贯性保持的平衡问题;在构建过程层面,原始维基百科数据包含大量非内容元素如标记语言、模板和参考文献,实现自动化清洗的同时保持信息的完整性与准确性需要设计复杂的处理流程。此外,确保知识时效性需要建立持续更新机制,这对数据维护提出了长期挑战。
常用场景
经典使用场景
在自然语言处理领域,TreeCorpus数据集以其结构化的维基百科知识库特性,成为训练大规模语言模型的黄金标准。该数据集通过精心处理的文本内容,为对话系统提供了丰富的知识背景,使得模型能够生成更具事实依据的响应。研究者们频繁将其应用于开放域问答系统的开发,因其覆盖了从科学技术到人文历史的广泛主题,为模型提供了全面的知识支撑。
衍生相关工作
该数据集催生了多项里程碑式研究,如基于知识增强的对话生成框架KnowGPT,其核心训练数据便来源于TreeCorpus。在问答系统方向,著名的OpenBookQA项目通过融合该数据集与推理技术,实现了复杂问题的多跳推理能力。近期发布的WikiBERT模型则创新性地利用数据集中的标题-文本结构,提出了新型的知识感知预训练范式。
数据集最近研究
最新研究方向
随着大规模语言模型在知识密集型任务中的广泛应用,TreeCorpus作为结构化维基百科知识库的代表性数据集,正日益成为对话系统与知识增强型AI研究的核心资源。当前研究聚焦于如何利用其层次化知识结构提升模型的事实一致性,特别是在多轮对话场景中解决幻觉问题。2023年Meta发布的Llama 2系列模型即采用了类似TreeCorpus的知识增强训练策略,显示出结构化知识注入对模型推理能力的显著提升。该数据集在知识图谱补全与动态知识更新方向的研究也备受关注,研究者们正探索如何结合其时间戳特征构建时序知识表示。在医疗、法律等专业领域问答系统中,基于TreeCorpus的领域知识微调方法已成为解决专业术语理解瓶颈的有效途径。
以上内容由遇见数据集搜集并总结生成


