ukrmedprotocols-2
收藏Hugging Face2025-12-13 更新2025-12-14 收录
下载链接:
https://huggingface.co/datasets/alexshynkarenk0/ukrmedprotocols-2
下载链接
链接失效反馈官方服务:
资源简介:
UkrMedProtocols-2是一个结构化的问答数据集,提取自乌克兰卫生部发布的官方公共临床标准,专注于神经学指南,用于临床AI和RAG应用。该数据集演示版本包含100个高质量的指令跟随问答对,而完整版本包含超过12,500个问答对,覆盖多个复杂的标准。完整版本的优势包括官方乌克兰神经学指南、临床详细答案、复杂医学推理、大规模和范围、以及适用于微调和RAG的清洁Alpaca格式。
UkrMedProtocols-2 is a structured question-answering (QA) dataset extracted from official public clinical standards released by the Ministry of Health of Ukraine, focusing on neurology guidelines and designed for clinical AI and Retrieval-Augmented Generation (RAG) applications. The demo version includes 100 high-quality instruction-following QA pairs, while the full version contains over 12,500 QA pairs covering multiple complex clinical standards. The advantages of the full version include official Ukrainian neurology guidelines, clinically detailed answers, complex medical reasoning, large scale and broad coverage, as well as a clean Alpaca format suitable for fine-tuning and RAG applications.
创建时间:
2025-12-10
原始信息汇总
数据集概述:UkrMedProtocols-2 — Ukrainian Clinical Standards Dataset (Demo)
基本信息
- 数据集名称:UkrMedProtocols-2 — Ukrainian Clinical Standards Dataset (Demo)
- 语言:乌克兰语 (uk)
- 许可证:Apache-2.0 (此演示版本)
- 标签:ukrainian, medical, healthcare, clinical-protocols, neurology, instruction-tuning, rag, qa, public-health, clinical-decision-support, low-resource, ukrainian-nlp
数据集描述
- 性质:一个从乌克兰卫生部发布的官方公共临床标准中提取的结构化问答数据集,专注于神经病学指南,用于临床人工智能和RAG应用。
- 版本说明:此存储库包含演示版本,包含来自完整UkrMedProtocols-2数据集的100个高质量指令遵循问答对。
- 完整版本:完整数据集规模显著更大,包含超过12,500个问答对,涵盖多个复杂的标准,对于构建可靠、专业的乌克兰医疗AI至关重要。
- 内容特点:
- 官方乌克兰神经病学指南:来自真实卫生部临床标准的逐字内容,为AI使用而结构化。
- 临床详细答案:涵盖诊断标准、多学科护理路径、质量指标、患者沟通和管理协议。
- 复杂医学推理:包括对症状、风险因素、复杂护理协调和鉴别诊断的细致描述。
- 格式与兼容性:干净的Alpaca格式,兼容Axolotl、Unsloth、Llama-Factory和临床AI系统。
许可信息
- 演示版本:可在此演示版本上根据MIT许可证自由使用、修改和微调模型。
- 完整版本:完整的UkrMedProtocols-2数据集不是开源的,根据单独的商业/研究许可证分发。
- 源内容:作为乌克兰卫生部的官方文件,源内容属于公共领域。
获取完整版本
- 获取方式:需购买完整企业版。
- 价格:€150。
- 购买链接:https://www.patreon.com/posts/ukrmedprotocols-145554506
- 联系方式:发送电子邮件至 founder@davidlab.tech 以安排许可协议。
搜集汇总
数据集介绍
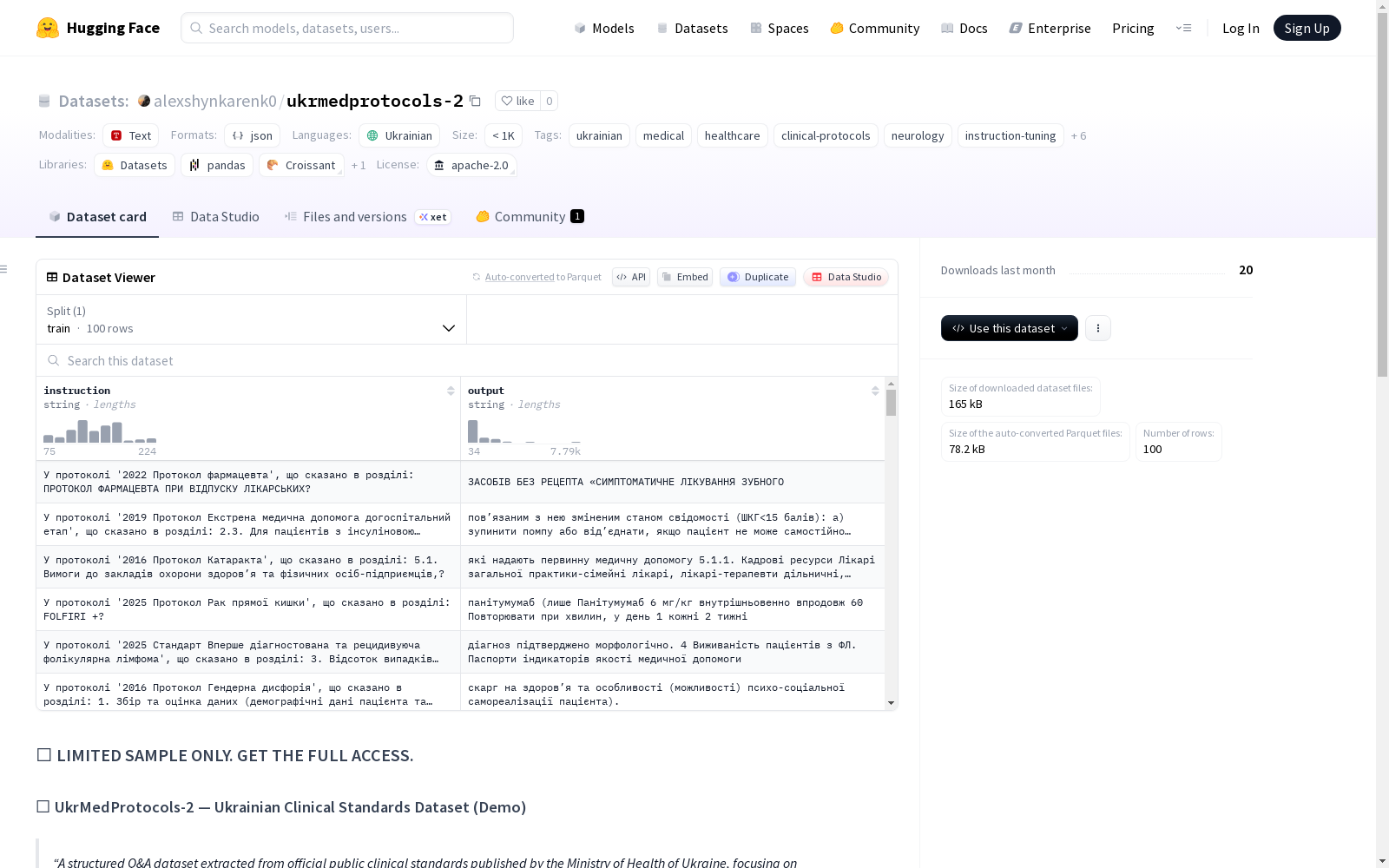
构建方式
在医学信息学领域,构建高质量的专业数据集对于推动临床决策支持系统的发展至关重要。UkrMedProtocols-2数据集基于乌克兰卫生部发布的官方神经学临床标准文档,通过系统化的抽取与结构化处理,将原始指南文本转化为问答对形式。其构建过程严格遵循内容保真原则,确保每对问答均直接源自权威医疗文献,涵盖了诊断标准、多学科护理路径及管理协议等核心临床信息,从而为人工智能模型提供了可靠且规范的训练素材。
特点
该数据集在低资源语言医疗自然语言处理中展现出独特价值,其核心特点在于内容的权威性与专业性。所有问答对均提取自乌克兰官方的神经学临床指南,确保了信息的准确性和时效性。数据集不仅规模庞大,完整版包含超过12,500对高质量问答,而且内容深度覆盖了复杂的医疗推理场景,如症状的细微描述、风险因素分析以及鉴别诊断过程,为模型理解并处理临床专业知识提供了丰富的语境。
使用方法
针对临床人工智能与检索增强生成的应用需求,该数据集已预先处理为清晰的Alpaca格式,便于直接用于模型微调。研究人员可利用其进行指令遵循训练,或将其整合至检索增强生成系统中,以构建专注于乌克兰语医疗问答的专用模型。数据集的设计兼容主流训练框架,如Axolotl与Llama-Factory,用户可根据研究或开发目标,灵活地将其应用于模型性能优化与特定临床任务的支持。
背景与挑战
背景概述
在低资源语言自然语言处理领域,尤其是面向专业垂直领域的应用,高质量标注数据的稀缺性长期制约着相关技术的发展。UkrMedProtocols-2数据集应运而生,由DavidLab机构于近期创建,其核心目标是将乌克兰卫生部发布的官方神经病学临床指南转化为结构化、适用于指令微调与检索增强生成(RAG)的问答对。该数据集直接回应了乌克兰语医疗人工智能系统在临床决策支持、患者沟通及诊疗路径规划等场景中对权威、本土化知识源的迫切需求,为提升乌克兰语医疗NLP模型的领域专业性与可靠性奠定了关键的数据基础。
当前挑战
该数据集旨在解决的领域核心挑战,在于如何让AI模型精准理解并应用复杂、专业的临床指南知识,以支持神经病学领域的诊断、治疗决策及患者管理。这要求模型具备处理医学术语、多步骤推理及细微症状描述的能力。在构建过程中,挑战主要源于将非结构化的官方文档高质量地转化为结构化问答对,这涉及对冗长、法律化文本的精确语义解析、关键信息的提取与重组,以及在低资源语言环境下确保医学知识的准确性与完整性,整个过程需要深厚的医学与语言学交叉专业知识。
常用场景
经典使用场景
在乌克兰语医疗自然语言处理领域,UkrMedProtocols-2数据集为神经学临床指南的结构化问答任务提供了核心资源。其经典使用场景聚焦于指令微调与检索增强生成技术,通过模拟真实临床决策流程,训练模型理解并生成基于官方标准的专业回答,从而支持自动化医疗咨询系统的开发。
解决学术问题
该数据集有效应对了低资源语言环境下专业领域数据稀缺的学术挑战,为乌克兰语医疗AI研究提供了高质量标注语料。它解决了临床协议结构化解析、跨学科护理路径建模以及复杂症状描述生成等关键问题,推动了语言模型在专业领域的可靠性与准确性提升,对促进医疗公平性具有深远意义。
衍生相关工作
围绕该数据集衍生的经典工作主要包括乌克兰语专业领域大模型的指令微调框架,如基于Alpaca格式的适配器训练流程。相关研究进一步拓展至多模态临床信息系统、跨语言医疗知识迁移以及低资源环境下检索增强生成系统的优化,为区域性医疗人工智能生态奠定了技术基础。
以上内容由遇见数据集搜集并总结生成


