Line-Insertions
收藏Hugging Face2024-09-17 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/MarineLives/Line-Insertions
下载链接
链接失效反馈官方服务:
资源简介:
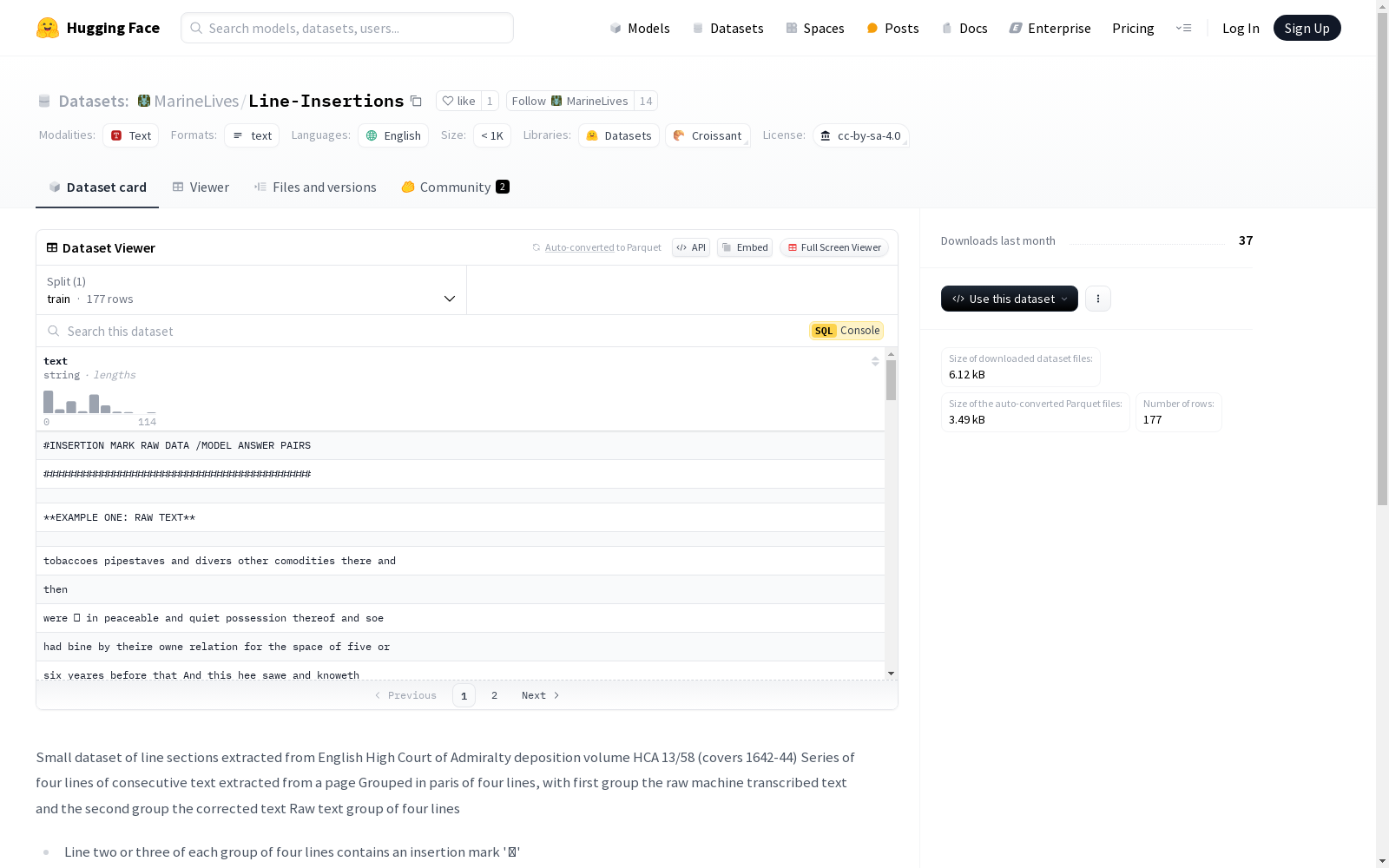
该数据集包含从英国高等海事法院的宣誓书卷HCA 13/58(涵盖1642-44年)中提取的行片段。数据集由连续的四行文本组成,分为两组:第一组是机器转录的原始文本,第二组是经过校正的文本。原始文本组中的第二或第三行包含插入标记'⁁',其上方或下方的行包含应插入的文本。校正后的文本组减少到三行,并在插入标记处插入文本。在某些情况下,还会进行额外的文本更改,以纠正HRT错误并扩展英语和拉丁语的缩写和缩略语,以确保准确的GroundTruth。
This dataset comprises line segments extracted from Volume HCA 13/58 of sworn testimony from the High Court of Admiralty, United Kingdom, spanning the years 1642–1644. Each segment consists of four consecutive lines of text, divided into two groups: the first group holds the raw machine-transcribed text, while the second group contains the corrected version. The second or third line of the raw text group features the insertion marker '⁁', with the line directly above or below this marker containing the text intended for insertion. The corrected text group is condensed to three lines, with the designated text inserted at the position of the original insertion marker. In certain instances, additional text edits are also implemented to rectify HRT errors and expand abbreviations and contractions in both English and Latin, so as to ensure accurate ground truth.
创建时间:
2024-09-15
原始信息汇总
MarineLives/Line-Insertions 数据集概述
语言
- 英语 (en)
许可证
- CC BY-SA 4.0
数据集描述
- 数据集包含从英国高等海事法院的宣誓书卷HCA 13/58(涵盖1642-44年)中提取的行片段。
- 每组数据由四行连续文本组成,分为两组:原始机器转录文本和修正后的文本。
- 原始文本组:
- 每组四行中的第二或第三行包含插入标记 ⁁。
- 插入标记上方或下方的行包含应插入的文本。
- 修正后的文本组:
- 减少到三行,文本在插入标记处插入。
- 在某些情况下,进行额外的文本更改,以纠正HRT错误并扩展英语和拉丁语的缩写和缩略语,以确保准确的GroundTruth。
数据结构示例
-
EXAMPLE SIX: RAW TEXT
the said parties and Benedicte Stafforde the Englishe master of for that voyage the Sta Cara ⁁ and the said shippe was laden with bayes Cloth and wynes and iron and pitch when shee came to Sta
-
EXAMPLE SIX: CORRECTION
the said parties and Benedicte Stafforde the Englishe master of the Santa Clara for that voyage and the said shippe was laden with bayes Cloth and wynes and iron and pitch when shee came to Santa
搜集汇总
数据集介绍
构建方式
Line-Insertions数据集构建于英国高等海事法院的证词卷宗HCA 13/58,涵盖了1642年至1644年的历史文献。该数据集通过从文献页面中提取连续的四行文本,并将其分为两组:一组为机器转录的原始文本,另一组为经过校正的文本。原始文本组中,每四行中的第二或第三行包含插入标记'⁁',标记上方或下方的文本为应插入的内容。校正文本组则将原始文本缩减为三行,并在插入标记处插入相应文本,同时修正了机器转录的错误,并扩展了英文和拉丁文的缩写与缩略语,以确保文本的准确性。
特点
Line-Insertions数据集的特点在于其独特的文本结构和对历史文献的精确校正。每四行文本被分为原始文本和校正文本两组,原始文本组中的插入标记'⁁'指示了文本的插入位置,校正文本组则通过插入和修正操作,确保了文本的准确性和可读性。此外,数据集还包含了机器转录错误的修正以及对英文和拉丁文缩写与缩略语的扩展,进一步提升了文本的质量和可用性。
使用方法
Line-Insertions数据集的使用方法主要围绕文本校正和历史文献研究展开。研究人员可以通过对比原始文本和校正文本,分析机器转录的误差模式,并探索历史文献中的语言特征。此外,该数据集还可用于训练和评估自然语言处理模型,特别是在文本校正和插入标记处理方面。通过使用该数据集,研究人员能够更好地理解历史文献的转录过程,并提升相关领域的研究水平。
背景与挑战
背景概述
Line-Insertions数据集源自英国高等海事法院的证词卷宗HCA 13/58,时间跨度为1642年至1644年。该数据集由一系列连续的四行文本片段组成,每组四行文本分为两部分:原始机器转录文本和修正后的文本。原始文本中,每组的第二或第三行包含插入标记'⁁',标记上方或下方的文本是需要插入的内容。修正后的文本则将这些插入内容整合,形成三行文本,并修正了手写识别错误及扩展了英文和拉丁文的缩写与缩略语,以确保数据的准确性。该数据集的创建旨在为历史文献的数字化和文本修正提供研究基础,对历史语言学、文本数字化处理等领域具有重要影响。
当前挑战
Line-Insertions数据集在解决历史文献数字化和文本修正问题时面临多重挑战。首先,原始文本中的插入标记和手写识别错误增加了文本解析的复杂性,需要精确的算法来识别和处理这些标记。其次,由于文本涉及多种语言(如英文和拉丁文)及其缩写形式,修正过程中需兼顾语言学的准确性。此外,数据集的构建依赖于对历史文献的深入理解,这对研究人员的专业背景提出了较高要求。这些挑战不仅考验了文本处理技术的鲁棒性,也为相关领域的研究提供了新的探索方向。
常用场景
经典使用场景
Line-Insertions数据集主要用于历史文献的数字化和文本校对研究。通过提供原始文本及其校正版本,该数据集为研究者提供了一个理想的平台,用于开发和测试自动文本校正算法。特别是在处理包含插入标记的文本时,数据集的结构化设计使得研究者能够精确地分析文本校正的准确性和效率。
衍生相关工作
基于Line-Insertions数据集,研究者已经开发了多种文本校正和自然语言处理工具。这些工具不仅提高了文本校正的自动化水平,还为历史文献的数字化提供了新的解决方案。例如,一些研究利用该数据集训练深度学习模型,以实现更高效的文本校正和插入标记识别。这些工作极大地推动了历史文献数字化领域的发展。
数据集最近研究
最新研究方向
在历史语言学与文本修复领域,Line-Insertions数据集为研究早期英语文本的转录与修正提供了宝贵的资源。近年来,研究者们利用该数据集探索了机器转录文本的自动修正技术,特别是在处理历史文献中的插入标记和缩写扩展方面取得了显著进展。这一研究方向不仅提升了历史文本的数字化准确性,还为自然语言处理技术在古籍保护中的应用开辟了新路径。此外,该数据集还被用于训练和评估深度学习模型,以自动识别和修正文本中的错误,从而推动了文本修复技术的智能化发展。
以上内容由遇见数据集搜集并总结生成


