VEATIC
收藏arXiv2023-09-15 更新2024-06-21 收录
下载链接:
https://veatic.github.io
下载链接
链接失效反馈官方服务:
资源简介:
VEATIC数据集是由加州大学伯克利分校创建的一个大型视频数据集,专注于情感和情境中的情感追踪。该数据集包含124个视频片段,来自好莱坞电影、纪录片和家庭视频,每个视频帧都有实时注释的连续情感和唤醒评级。VEATIC旨在克服现有数据集的局限性,通过包含面部特征和情境因素,为心理学和计算机视觉研究提供丰富的资源。数据集的创建过程中,招募了大量的注释者(总共192人)以减少注释偏差,并提出了一个新的计算机视觉任务,即通过视频帧中的情境和角色信息自动推断所选角色的情感。VEATIC的应用领域包括情感识别算法的开发和社交认知的研究,旨在解决情感识别中的情境依赖性问题。
The VEATIC dataset is a large-scale video dataset developed by the University of California, Berkeley, focusing on emotion tracking within affective states and contextual scenarios. It includes 124 video clips sourced from Hollywood films, documentaries, and home videos, with each video frame paired with real-time annotated continuous emotion and arousal ratings. VEATIC aims to overcome the limitations of existing datasets, serving as a rich resource for psychological and computer vision research by incorporating facial features and contextual factors. During the dataset's creation process, a large pool of annotators (totaling 192 individuals) was recruited to mitigate annotation bias, and a novel computer vision task was proposed: automatically inferring the emotions of selected characters based on contextual and character information within video frames. The application domains of VEATIC include the development of emotion recognition algorithms and social cognition research, targeting the resolution of the contextual dependency issue in emotion recognition.
提供机构:
加州大学伯克利分校
创建时间:
2023-09-13
搜集汇总
数据集介绍
构建方式
在情感计算领域,传统数据集往往局限于面部表情的孤立分析,忽略了环境背景对情感感知的深刻影响。VEATIC数据集的构建突破了这一局限,其采集过程精心设计了多源视频素材与实时连续标注机制。研究团队从YouTube平台筛选了124段视频片段,涵盖好莱坞电影、纪录片及家庭录像三类来源,确保场景与情感的多样性。标注过程中,192名参与者通过二维效价-唤醒度网格对目标人物进行实时连续情感追踪,每帧均获得连续数值评分。为控制标注偏差,实验采用维度平衡设计,并设置注意力监测机制,最终形成包含257,601帧的精密标注体系。
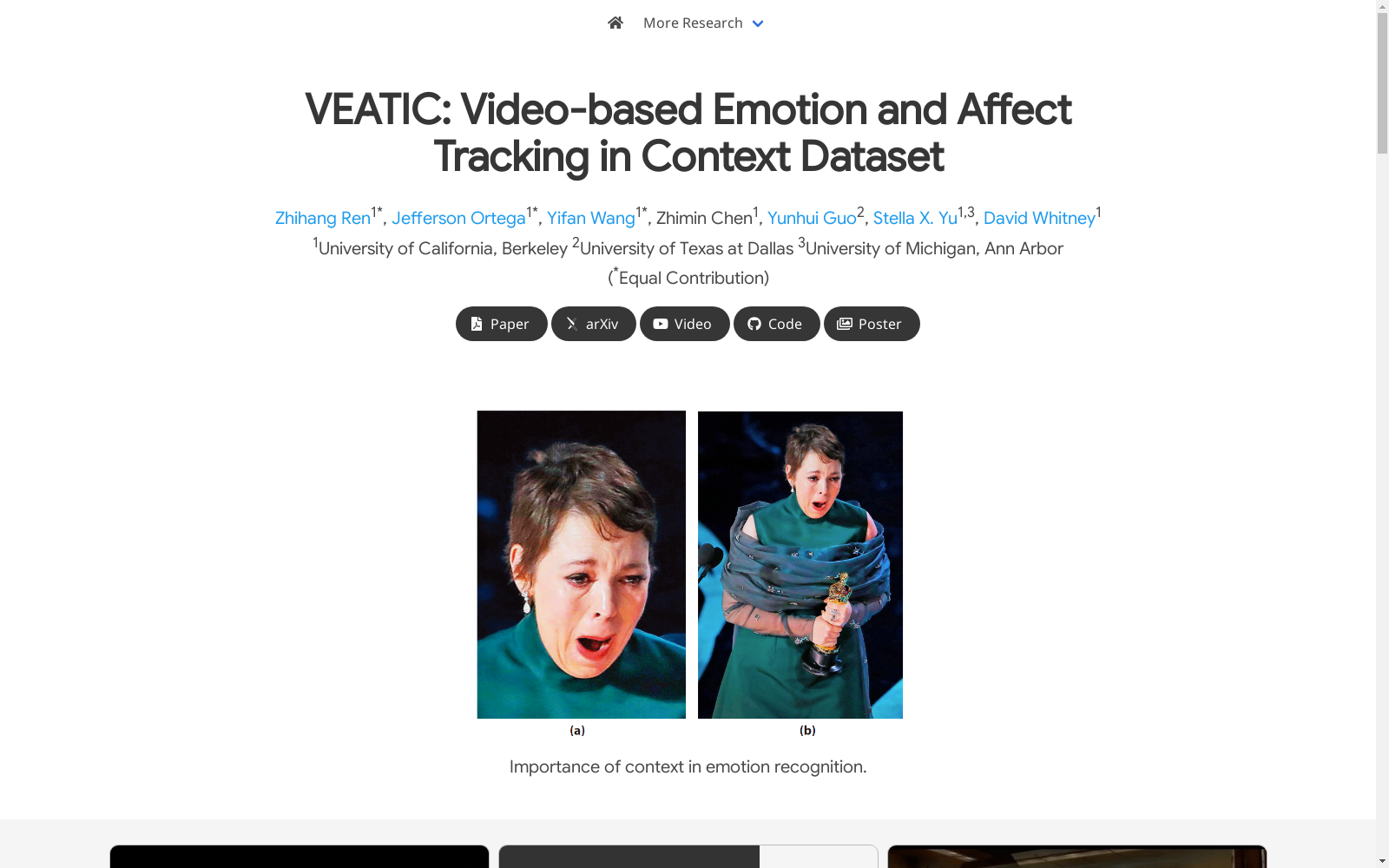
特点
VEATIC数据集的核心特征在于其首创的上下文感知连续情感标注范式。与既往仅关注面部区域的数据集不同,该数据集完整保留了视频中的场景信息、人物互动及背景动态,模拟真实世界情感感知的多模态输入。数据标注采用心理学经典的环状情感模型,以连续数值记录效价与唤醒度的动态变化,突破了传统离散分类的局限。值得注意的是,数据集包含多段相同视频对不同人物的独立标注,为研究互动情境下的情感分化提供了独特视角。其标注者规模达192人,显著降低了个人偏差对共识评分的影响,标注一致性指标达到μ=0.248的高信度水平。
使用方法
该数据集为上下文感知的情感计算研究提供了标准化的评估基准。使用者可基于完全信息帧(包含人物与背景)训练模型,亦可分别使用人物裁剪帧或纯背景帧进行消融实验,以量化上下文信息的贡献度。基准模型采用CNN特征提取与视觉Transformer时序处理的架构,损失函数融合均方误差与一致性相关系数,在70%-30%的时序分割方案下进行训练验证。评估体系包含一致性相关系数、皮尔逊相关系数、均方根误差及符号一致率四类指标,全面衡量模型在连续情感维度上的预测性能。数据集特别适用于开发需要融合时空上下文信息的情感追踪算法,为心理学实验设计与计算机视觉模型泛化能力评估提供重要支撑。
背景与挑战
背景概述
在情感计算与计算机视觉交叉领域,人类情感识别一直是核心研究议题。传统数据集多聚焦于孤立的面部表情分析,忽略了场景上下文对情感感知的关键影响,导致模型难以泛化至真实世界场景。为突破此局限,加州大学伯克利分校等机构的研究团队于2023年推出了VEATIC数据集。该数据集首次大规模整合了视频中的上下文信息与连续情感维度标注,包含124段来自好莱坞电影、纪录片及家庭视频的片段,并通过192名标注者实现了每帧效价与唤醒度的实时标注。VEATIC的创立标志着情感识别研究从静态、孤立的表情分析迈向动态、情境融合的新范式,为心理学机制探索与计算机视觉模型开发提供了前所未有的数据基础。
当前挑战
VEATIC数据集致力于解决情境化情感识别这一复杂问题,其核心挑战在于如何精准建模动态视频中人物情感与丰富上下文(如场景、互动、背景信息)间的多模态关联。具体而言,领域问题的挑战体现为:模型需同时解析面部特征、肢体语言、人际交互及环境线索,并理解这些要素随时间演变的协同作用,以连续维度预测效价与唤醒度。在数据构建过程中,研究团队面临多重困难:一是确保大规模实时标注的连续性与一致性,需设计特殊界面防止标注者疲劳并监控标注质量;二是处理视频源的高度多样性(如光照变化、拍摄角度、剪辑风格),保证数据代表性;三是协调多标注者间的主观差异,通过统计学方法筛选异常标注,以构建可靠的情感共识基准。
常用场景
经典使用场景
在情感计算与计算机视觉领域,VEATIC数据集为基于上下文的情感识别研究提供了经典范例。该数据集通过整合好莱坞电影、纪录片及家庭录像等多种真实场景视频,并辅以连续效价与唤醒度标注,构建了首个大规模上下文感知视频情感数据库。其核心应用场景在于训练和评估能够同时利用人物特征与场景上下文信息进行连续情感预测的计算模型,为探索人类情感感知的复杂机制提供了前所未有的数据基础。
衍生相关工作
VEATIC数据集的发布催生并衔接了多项情感计算领域的相关研究。其构建理念延续并拓展了早期如CAER、EMOTIC等上下文感知数据集的工作,但通过视频模态和连续标注实现了重要突破。该数据集提出的新任务——结合人物与上下文信息进行连续情感预测,为后续研究设立了明确的基准。其采用的基于CNN特征提取与视觉Transformer处理时序信息的基线模型架构,也为后续探索更复杂的多模态融合、注意力机制以及时序建模方法提供了启发和比较基础。
数据集最近研究
最新研究方向
在情感计算与计算机视觉领域,VEATIC数据集的推出标志着情感识别研究从孤立的面部表情分析转向了融合上下文信息的综合建模。该数据集通过引入好莱坞电影、纪录片和家庭视频中的连续效价与唤醒度标注,为探索时空背景在情感感知中的作用提供了丰富资源。前沿研究聚焦于开发多模态神经网络架构,结合视觉Transformer与卷积网络,以同时利用角色特征与场景上下文进行实时情感追踪。这一方向不仅推动了心理学中情感机制的理论深化,也为机器人、虚拟人等AI系统的自然交互奠定了技术基础,成为当前跨学科研究的热点。
相关研究论文
- 1VEATIC: Video-based Emotion and Affect Tracking in Context Dataset加州大学伯克利分校 · 2023年
以上内容由遇见数据集搜集并总结生成


