ParaRev
收藏arXiv2025-01-09 更新2025-01-11 收录
下载链接:
https://huggingface.co/datasets/taln-ls2n/pararev
下载链接
链接失效反馈官方服务:
资源简介:
ParaRev是由南特大学、南特中央理工学院等机构创建的科学文本修订数据集,包含48,203个修订段落的对,其中641个段落经过手动注释。该数据集旨在支持段落级别的文本修订任务,提供详细的修订指令,帮助模型进行更全面的修改。数据集的内容来源于CASIMIR语料库,经过筛选保留了具有实质性修订的段落。数据集的创建过程包括段落选择、修订分类和指令生成,最终用于评估自动化修订模型的效果。该数据集的应用领域主要集中在科学写作辅助工具的开发,旨在提高科学文本的清晰度和结构质量。
ParaRev is a scientific text revision dataset created by institutions such as the University of Nantes and École Centrale de Nantes. It contains 48,203 pairs of revised paragraphs, with 641 of these paragraphs manually annotated. This dataset is designed to support paragraph-level text revision tasks, providing detailed revision instructions to assist models in conducting more comprehensive modifications. The content of the dataset is sourced from the CASIMIR corpus, and only paragraphs with substantive revisions are retained after screening. The creation process of the dataset includes paragraph selection, revision classification and instruction generation, and it is ultimately used to evaluate the performance of automated revision models. The main application field of this dataset focuses on the development of scientific writing assistance tools, aiming to improve the clarity and structural quality of scientific texts.
提供机构:
南特大学, 南特中央理工学院, 法国国家科学研究中心, LS2N实验室
创建时间:
2025-01-09
原始信息汇总
数据集概述
数据集名称
pararev
数据集许可证
- 许可证类型: Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)
- 许可证链接: https://creativecommons.org/licenses/by-nc-sa/4.0/
搜集汇总
数据集介绍
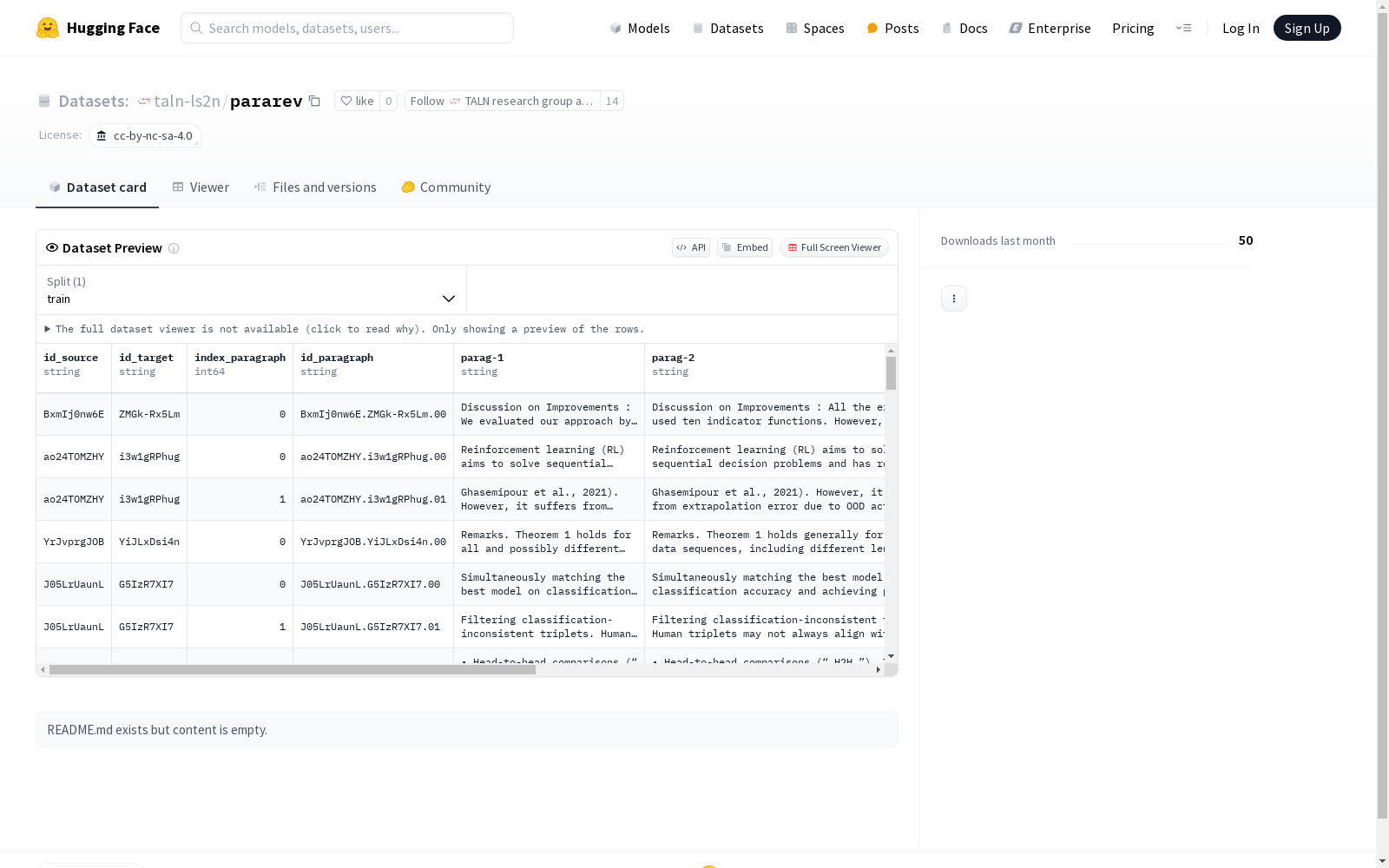
构建方式
ParaRev数据集的构建基于CASIMIR语料库,该语料库包含了科学文章的修订版本,并通过段落级别的ID进行对齐。为了确保数据集的高质量,研究者通过手工设计的启发式方法筛选出具有实质性修订的段落,而非仅进行微小语法修正的段落。最终,从原始的1,889,810个段落对中筛选出48,203个段落,构成了ParaRev数据集的核心部分。此外,研究者还开发了一个新的段落级修订分类法,涵盖了九种修订意图,并为每个段落对分配了修订标签。
特点
ParaRev数据集的特点在于其专注于段落级别的修订任务,而非传统的句子级别修订。该数据集包含了48,203个修订段落对,并提供了一个包含641个手动标注段落的评估子集。每个段落对都附有详细的修订指令,这些指令为模型提供了具体的修订指导,使得修订过程更加精确和有效。此外,数据集的修订分类法涵盖了多种修订意图,如重写、简洁化、内容扩展等,能够支持多样化的修订任务。
使用方法
ParaRev数据集的使用方法主要围绕段落级别的修订任务展开。研究者可以通过数据集提供的修订指令,指导模型对科学文本进行段落级别的修订。具体而言,用户可以将原始段落和修订指令输入到模型中,模型将根据指令生成修订后的段落。此外,数据集还支持对修订质量的评估,用户可以使用ROUGE-L、SARI和Bertscore等指标来衡量修订效果。通过这种方式,ParaRev数据集为科学写作辅助工具的开发提供了重要的数据支持。
背景与挑战
背景概述
ParaRev数据集由Léane Jourdan、Nicolas Hernandez、Richard Dufour等研究人员于2025年提出,旨在解决科学文本修订中的段落级修订问题。该数据集首次引入了带有详细修订指令的段落级修订任务,突破了传统句子级修订的局限。ParaRev基于CASIMIR语料库构建,包含48,203对修订段落,其中641个段落经过人工标注,涵盖了从轻微到重大修订的多种修订意图。该数据集的推出为科学写作辅助工具的发展提供了重要支持,尤其是在非母语研究者和年轻学者的写作过程中,显著提升了文本的清晰度和学术质量。
当前挑战
ParaRev数据集在构建和应用过程中面临多重挑战。首先,段落级修订任务要求模型能够处理更广泛的上下文信息,而不仅仅是局部句子修改,这对模型的上下文理解能力提出了更高要求。其次,数据集的构建过程中,如何从大量修订段落中筛选出具有实质性修改的段落是一个关键难题,研究人员通过手工设计的启发式方法解决了这一问题。此外,修订指令的标注过程复杂且耗时,尤其是在处理多意图修订时,标注者之间的共识度较低,需要通过超级标签来缓解标注不一致的问题。最后,现有的评估指标(如ROUGE-L和SARI)在段落级修订任务中的适用性有限,难以全面反映修订质量,亟需开发更精准的评估方法。
常用场景
经典使用场景
ParaRev数据集主要用于科学文本的段落级修订任务,特别是在自然语言处理(NLP)领域,研究者通过该数据集探索如何利用详细的修订指令来指导模型进行段落级别的文本优化。该数据集通过提供修订前后的段落对,并附有详细的修订指令,使得模型能够在更广泛的上下文中进行有效的文本修改,如句子合并、拆分或重组。
解决学术问题
ParaRev数据集解决了科学写作中段落级修订的难题,尤其是传统的句子级修订方法无法捕捉到更广泛的上下文信息。通过引入详细的修订指令,ParaRev使得模型能够进行更有意义的修改,显著提升了修订质量。这一数据集为自动化写作辅助工具的开发提供了新的思路,帮助研究者更好地理解如何通过个性化指令指导模型进行复杂的文本修订。
衍生相关工作
ParaRev数据集的发布推动了多个相关研究工作的进展。例如,基于该数据集的研究进一步探索了如何将段落级修订任务与大型语言模型(LLM)结合,提出了新的修订模型和评估方法。此外,ParaRev还启发了其他研究者在不同领域(如法律文本、技术文档)中应用类似的段落级修订方法,推动了自动化文本修订技术的多样化发展。
以上内容由遇见数据集搜集并总结生成


