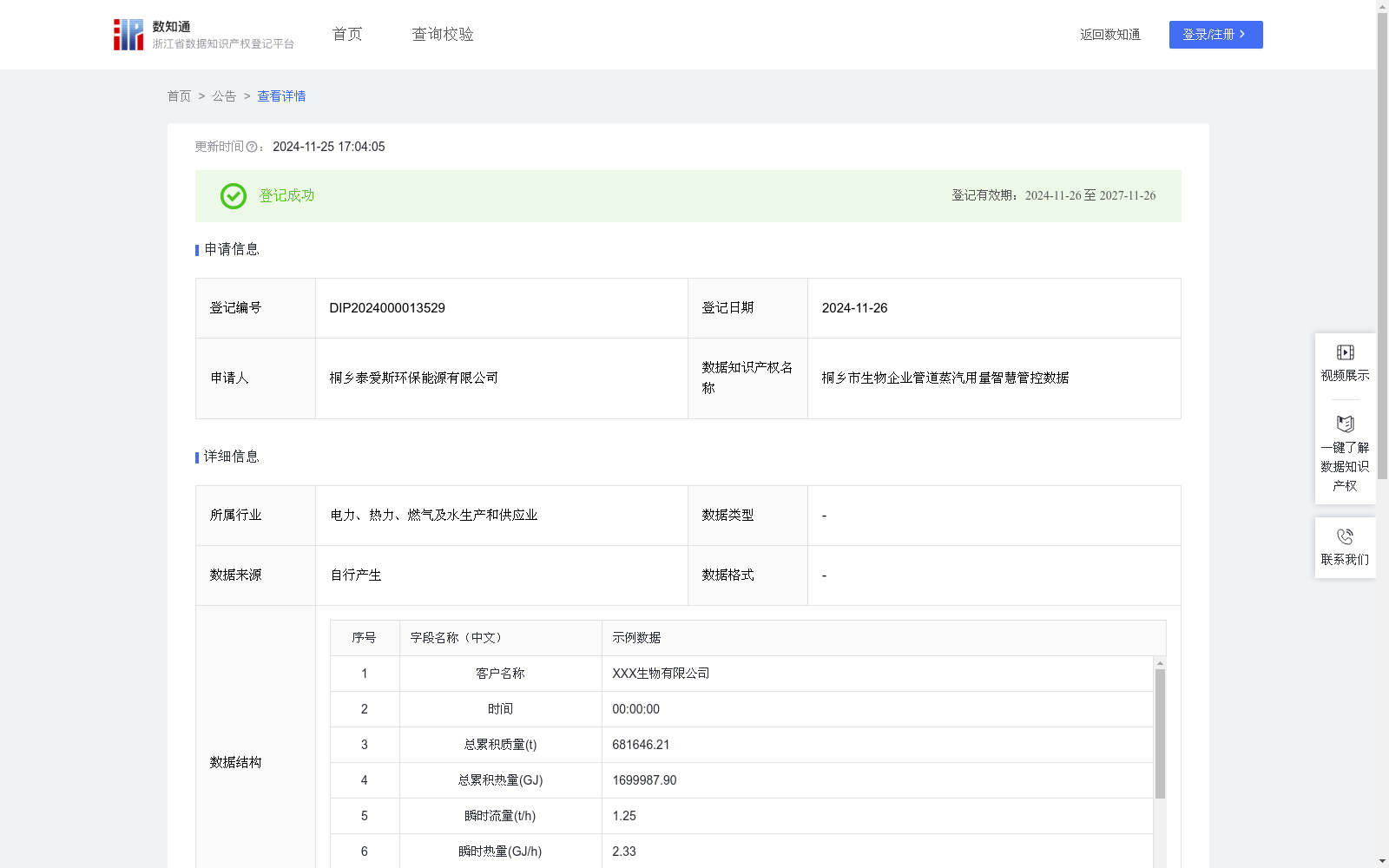
桐乡市生物企业管道蒸汽用量智慧管控数据
收藏资源简介:
通过收集和分析生物企业管道蒸汽用量的时间、总累积质量、总累积热量、瞬时流量、瞬时热量、瞬时温度、瞬时压力、密度、输入电流等相关数据,了解生物企业对用热量的需求,以及对客户的用热量影响分析,能够更准确地预测其生产过程中的用热量,以便更好地进行能源管理和成本控制,利于生物类企业自我管控。将该模型应用于生物企业实际生产中,每天根据当天的生产计划和设备运行参数,预测当天的蒸汽用量。企业可以根据预测结果合理安排能源供应,优化生产调度,降低能源成本。同时,通过对蒸汽用量的实时监测和分析,及时发现能源浪费和设备故障等问题,提高能源利用效率和生产效益,实现绿色生产,对生物业类的企业生产过程有指导作用。科研机构可以利用生物企业的管道蒸汽用量智慧管控数据,开展能源管理技术的研究和创新。通过对大量数据的分析和挖掘,科研机构可以深入了解生物企业的蒸汽用量规律和节能潜力,研发出针对生物行业的能源管理技术和设备。选用卷积神经网络模型进行构建。步骤1:数据进行收集处理,整理为一个形状为(n_samples, 9)的numpy数组,管道蒸汽用量的时间、总累积质量、总累积热量、瞬时流量、瞬时热量、瞬时温度、瞬时压力、密度、输入电流分别为9个特征,再进行标准化处理,使得每个特征的均值为0,标准差为1。步骤2:利用python创建模型,添加一维卷积层、最大池化层,添加第二个卷积层、最大池化层,将卷积层的输出展平,添加全连接层,最后添加输出层,模型核心为使用一维卷积层来提取特征,然后通过最大池化层降低特征维度,将卷积层的输出展平后连接全连接层,最后输出一个预测值。步骤3:对模型进行编译,划分训练集、验证集和测试集,最后对输入数据进行形状调整,以适应卷积层的输入要求,再训练该模型。步骤4:测试和评估模型性能,绘制训练和验证损失曲线,观察训练过程,防止过拟合。步骤5:卷积神经网络模型输出预测蒸汽流量值和最高临界值为13.71t/h,当预测蒸汽流量值>13.71t/h,管道状态显示“管道异常”,当0≤预测蒸汽流量值≤13.71t/h,显示“管道正常”。
Relevant data including time, total cumulative mass, total cumulative heat, instantaneous flow rate, instantaneous heat, instantaneous temperature, instantaneous pressure, density, and input current related to pipeline steam usage in biological enterprises are collected and analyzed, to understand the heat demand of such enterprises and evaluate the impact of their heat consumption on customers. This facilitates more accurate prediction of heat consumption during their production processes, supporting better energy management and cost control, and aiding self-management of biological enterprises. This model is applied to the actual production of biological enterprises, where daily steam usage can be predicted based on the day's production plan and equipment operating parameters. Enterprises can reasonably arrange energy supply, optimize production scheduling, and reduce energy costs according to the prediction results. Meanwhile, through real-time monitoring and analysis of steam usage, problems such as energy waste and equipment failures can be detected in a timely manner, improving energy utilization efficiency and production benefits, achieving green production, and providing guidance for the production processes of biological enterprises. Research institutions can leverage the intelligent management and control data of pipeline steam usage from biological enterprises to conduct research and innovation on energy management technologies. Through analysis and mining of large-scale data, research institutions can gain in-depth insights into the steam usage patterns and energy-saving potential of biological enterprises, and develop energy management technologies and equipment tailored specifically for the biological industry. A Convolutional Neural Network (CNN) model is selected for construction. Step 1: Data collection and processing: organize the data into a numpy array with the shape of (n_samples, 9), where the 9 features correspond to time, total cumulative mass, total cumulative heat, instantaneous flow rate, instantaneous heat, instantaneous temperature, instantaneous pressure, density, and input current of pipeline steam usage, respectively. Then perform standardization processing to make the mean value of each feature 0 and the standard deviation 1. Step 2: Create the model using Python: add a 1D convolutional layer, a max pooling layer, a second convolutional layer and a second max pooling layer, flatten the output of the convolutional layers, add a fully connected layer, and finally add an output layer. The core of the model is to use 1D convolutional layers to extract features, reduce feature dimensions via max pooling layers, flatten the output of the convolutional layers, connect to the fully connected layer, and finally output a predicted value. Step 3: Compile the model, split the dataset into training, validation and test sets, adjust the shape of the input data to meet the input requirements of the convolutional layers, and then train the model. Step 4: Test and evaluate the model performance, plot the training and validation loss curves, observe the training process, and prevent overfitting. Step 5: The CNN model outputs the predicted steam flow value, with the upper critical threshold set at 13.71 t/h. When the predicted steam flow value exceeds 13.71 t/h, the pipeline status is displayed as "Abnormal Pipeline"; when 0 ≤ predicted steam flow value ≤ 13.71 t/h, the status is displayed as "Normal Pipeline".