FareedKhan/1k_stories_100_genre
收藏Hugging Face2023-12-08 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/FareedKhan/1k_stories_100_genre
下载链接
链接失效反馈官方服务:
资源简介:
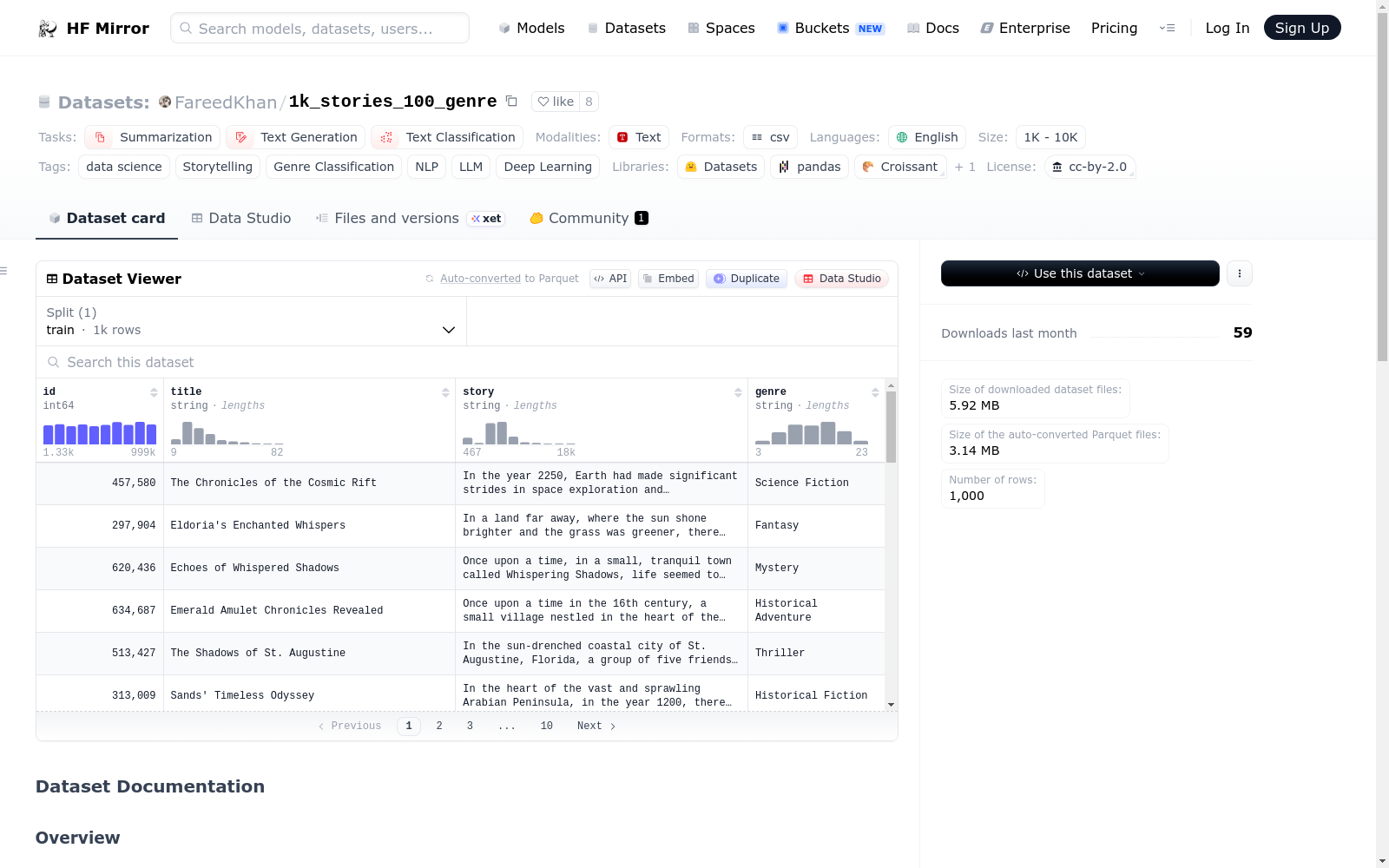
该数据集包含1000个故事,涵盖100种不同的体裁。每个故事以表格形式表示,包含唯一ID、标题、故事内容和体裁。数据集的格式包括id(唯一标识符)、title(故事标题)、story(故事内容)和genre(故事体裁)。示例数据框展示了这些字段的具体内容。标题的平均字数为6个单词,故事的平均字数为960个单词。
该数据集包含1000个故事,涵盖100种不同的体裁。每个故事以表格形式表示,包含唯一ID、标题、故事内容和体裁。数据集的格式包括id(唯一标识符)、title(故事标题)、story(故事内容)和genre(故事体裁)。示例数据框展示了这些字段的具体内容。标题的平均字数为6个单词,故事的平均字数为960个单词。
提供机构:
FareedKhan
原始信息汇总
数据集文档
概述
该数据集包含1000个故事,跨越100个不同类型。每个故事以数据框的表格格式表示。数据集包括唯一ID、标题和每个故事的内容。
类型列表
所有类型的列表可以在genres.txt文件中找到。
python with open(story_genres.pkl, rb) as f: story_genres = pickle.load(f)
类型列表示例:
python genres = [Sci-Fi, Comedy, ...]
数据框格式
数据集的结构如下:
- id: 每个数据框的唯一标识符。
- title: 故事的标题。
- story: 故事的内容。
- genre: 故事的类型。
示例数据框
| id | title | story | genre |
|---|---|---|---|
| 25235 | The Unseen Miracle | It was a stormy night in ... | Horror |
| ... | ... | ... | ... |
平均字数长度
- 标题:6个单词
- 故事:960个单词
许可证
该数据集在cc-by-2.0许可证下发布。
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个多类型故事集合,包含1000个故事,每个故事都有独特的标题、内容和明确的类型标签。数据集结构化为表格形式,便于进行数据分析和机器学习任务,适用于文本分类、自然语言处理等领域的研究。
以上内容由遇见数据集搜集并总结生成


