FiveC/CoCoDoc-MT-20k
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/FiveC/CoCoDoc-MT-20k
下载链接
链接失效反馈官方服务:
资源简介:
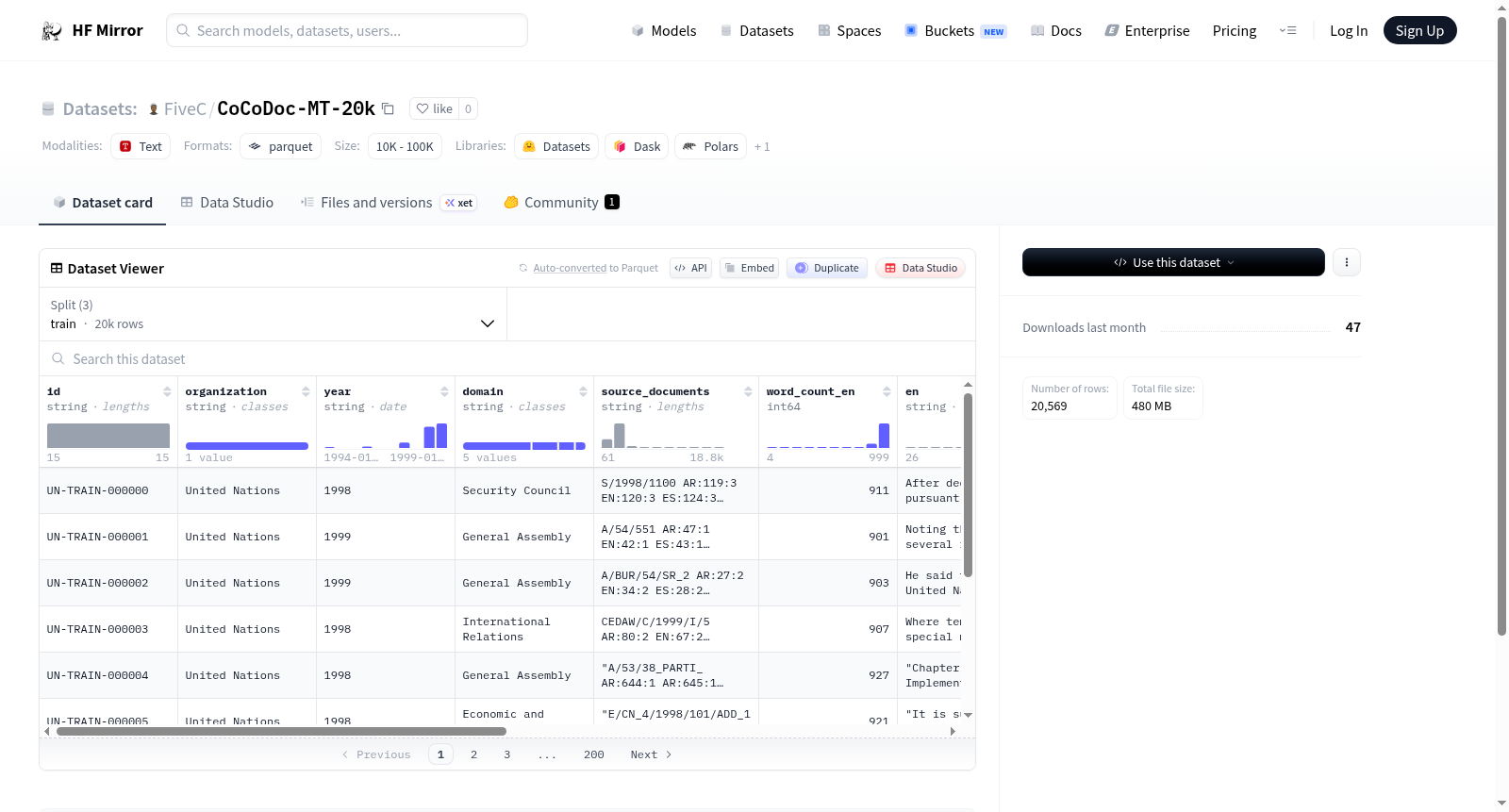
该数据集包含多语言翻译数据,涉及英语、法语、西班牙语、中文、俄语和阿拉伯语。数据集包含多个字段,如ID、组织、年份、领域、源文档、英语单词计数以及各语言的翻译文本。数据集分为训练集、验证集和测试集,分别包含20000、269和300个示例。
This dataset contains multilingual translation data involving English, French, Spanish, Chinese, Russian, and Arabic. The dataset includes various fields such as ID, organization, year, domain, source documents, English word count, and translated texts in multiple languages. The dataset is divided into train, validation, and test splits, containing 20,000, 269, and 300 examples respectively.
提供机构:
FiveC
搜集汇总
数据集介绍
构建方式
CoCoDoc-MT-20k数据集以多语言平行语料库为核心构建理念,汇聚了来自不同组织、跨越多个年份与领域的源文档。构建过程中,研究者精心筛选了涵盖英语、法语、西班牙语、中文、俄语及阿拉伯语六种语言的20,000条平行句子对,每条数据均标注了唯一标识符、来源机构、年份及所属领域。通过严格的对齐与校验流程,确保了多语言之间语义的一致性,最终形成了包含训练集、验证集与测试集的标准化数据划分。
特点
该数据集的突出特点是其多语言覆盖范围与领域多样性,覆盖六大语言,使研究人员能够探索跨语言翻译的共性规律。每个样本均保留原文及对应翻译,为文档级机器翻译研究提供了丰富素材。随附的词数统计与元数据(如年份、领域)增强了数据的可解释性,便于分析语言特征随时间或专业领域变化的趋势。20k规模的精心平衡,既保证了训练效率,又不失代表性,适合多语言神经机器翻译模型的快速迭代与评估。
使用方法
使用CoCoDoc-MT-20k数据集时,用户可通过Hugging Face Datasets库加载,直接获取划分好的训练、验证与测试集。数据以标准格式存储,可轻松接入PyTorch或TensorFlow框架进行模型训练。研究者可依据组织、年份或领域字段对数据进行自定义筛选,以构建特定子集。对于多语言翻译任务,建议利用其六语言平行特性,尝试零样本或低资源翻译场景;同时,借助文档级对齐的优势,探索上下文感知的翻译模型,提升译文连贯性与忠实度。
背景与挑战
背景概述
CoCoDoc-MT-20k是一个面向多语言文档级机器翻译的高质量平行语料库,由专业研究团队于近年构建。该数据集聚焦于组织与机构在报告、规章等正式文档语境下的翻译任务,涵盖英、法、西、中、俄、阿六种语言对,包含约2万训练样本及验证与测试集。其核心研究问题在于推动文档级机器翻译的发展,使模型能够捕捉跨句上下文依赖与术语一致性。该数据集的发布显著促进了多语言翻译系统的评估与训练,成为相关领域的重要基准资源。
当前挑战
该数据集所解决的领域挑战在于文档级机器翻译中的上下文连贯性与术语一致性难题,传统句子级翻译常导致语篇断裂或歧义。构建过程中面临多重挑战:筛选并标注跨机构、跨年度的正式文档,需处理多源异构文本的格式统一与对齐;确保六语言对的平行质量,需人工校验以消除翻译噪声;设计平衡的领域分布,避免单一主题偏差影响模型泛化能力;以及构建大规模、高质量的多语文档对,需兼顾数据规模与标注精度的权衡。
常用场景
经典使用场景
CoCoDoc-MT-20k是一个专为文档级机器翻译任务设计的高质量平行语料库,涵盖英语、法语、西班牙语、中文、俄语和阿拉伯语六种语言。该数据集精选自多领域、多组织的真实文档,包含2万训练样本及验证与测试集,为研究文档级翻译中的上下文一致性、篇章连贯性及指代消解等核心问题提供了理想基准。其经典使用场景包括训练和评估基于Transformer架构的文档翻译模型,以及探索如何利用跨句信息提升翻译质量,从而推动机器翻译从句子级向篇章级跃迁。
实际应用
在实际应用中,CoCoDoc-MT-20k为多语种文档翻译系统提供了重要的训练与测试资源,尤其适用于法律、技术文档和新闻报道等需要高度上下文连贯性的场景。基于该数据集训练的模型可直接部署于跨语言信息检索、多语种内容生成及本地化翻译平台,提升长文本翻译的流畅性与准确性。其在组织协作和年度报告处理中的应用,能有效降低人工翻译成本,加速全球化信息交流。
衍生相关工作
CoCoDoc-MT-20k衍生了一系列经典工作,包括基于文档级Transformer的上下文感知翻译模型、篇章对比学习框架以及跨句注意力机制优化研究。研究者借助该数据集提出了多种篇章一致性损失函数,如动态上下文缓存和篇章级微调策略,并开发了面向多语种的文档翻译评估基准。这些工作进一步催生了文档级双向翻译模型、零样本篇章翻译探索,以及结合预训练语言模型的篇章翻译统一范式,形成了该领域的重要研究脉络。
以上内容由遇见数据集搜集并总结生成


