IndicTTS_Malayalam
收藏Hugging Face2025-01-25 更新2025-02-10 收录
下载链接:
https://huggingface.co/datasets/SPRINGLab/IndicTTS_Malayalam
下载链接
链接失效反馈官方服务:
资源简介:
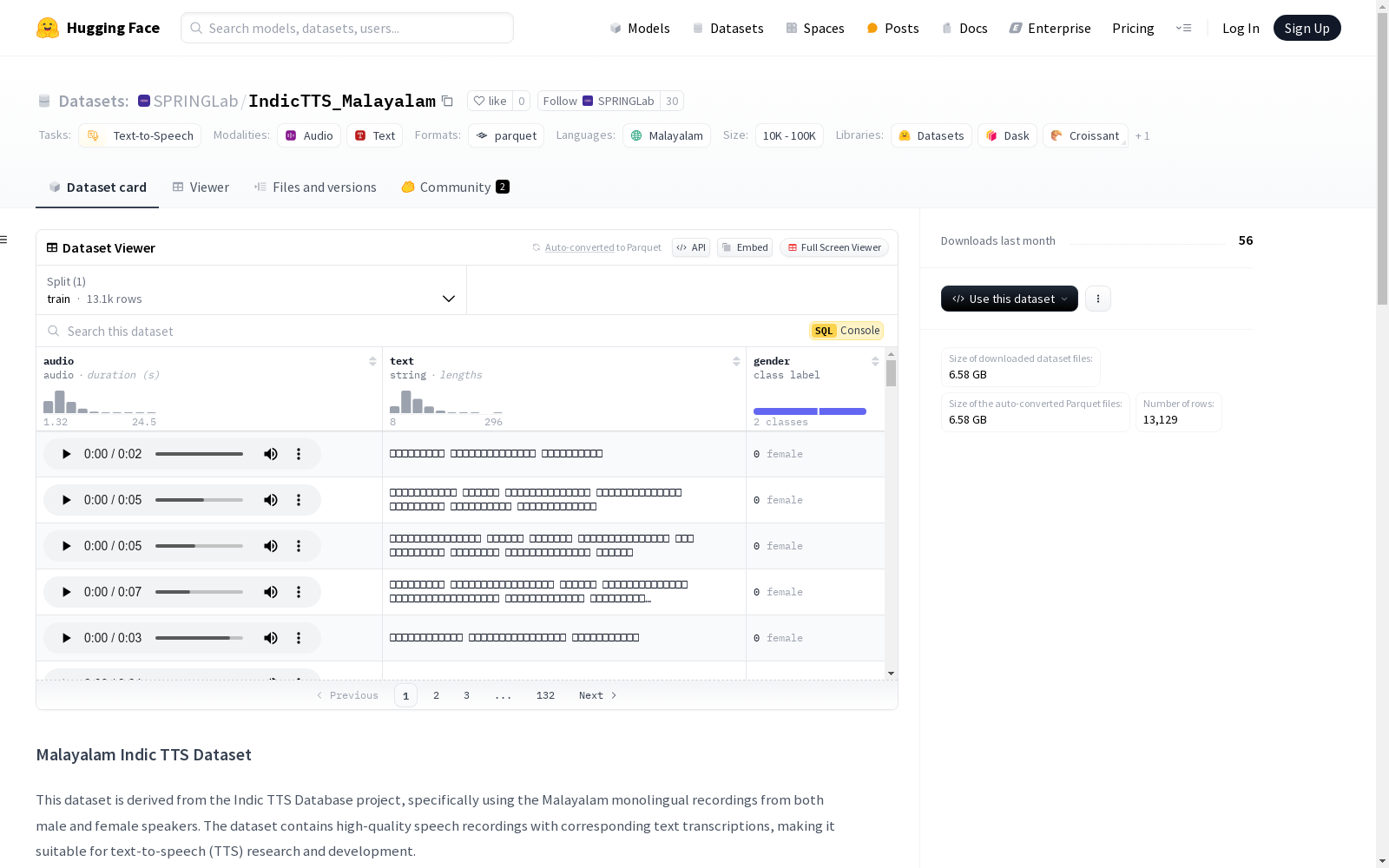
该数据集来源于Indic TTS数据库项目,特别是使用马拉雅拉姆语的单语录音,包括男性和女性说话者。数据集包含高质量的语音录音和相应的文本转录,适用于文本到语音(TTS)的研究和开发。数据集的语言是马拉雅拉姆语,总时长约为17.89小时(男性:9.7小时,女性:8.19小时),音频格式为WAV,采样率为48000Hz,包含2位说话者(1男1女)。录音质量达到工作室级别,所有音频文件都有相应的文本转录。数据集来源于印度理工学院马德拉斯分校的语音技术联盟开发的Indic TTS数据库,该数据库涵盖了印度的13种主要语言,包含10,000多条单语和英语录音的句子/话语。
This dataset is derived from the Indic TTS Database Project, specifically utilizing monolingual Malayalam recordings from both male and female speakers. It contains high-quality speech recordings and their corresponding text transcriptions, tailored for research and development of text-to-speech (TTS) systems. The dataset is entirely in Malayalam, with a total duration of approximately 17.89 hours (9.7 hours for male speakers, 8.19 hours for female speakers). The audio format is WAV with a sampling rate of 48000 Hz, and it includes 2 speakers (1 male and 1 female). All recordings are of studio-grade quality, and every audio file has a matching text transcription. This dataset originates from the Indic TTS Database developed by the Speech Technology Consortium at the Indian Institute of Technology Madras, which covers 13 major Indian languages and contains over 10,000 sentences/utterances from monolingual and English recordings.
创建时间:
2025-01-24
搜集汇总
数据集介绍
构建方式
IndicTTS_Malayalam数据集是由印度理工学院马德拉斯分校的语音技术联盟构建的Indic TTS数据库项目的一部分,选取了马来语的单语录音,涵盖了男女两位本地说话者的声音。该数据集包含了高质量的语音录音及其对应的文本转录,为文本到语音的研究与开发提供了丰富的资源。
特点
该数据集以马来语为语言,包含约17.89小时的录音时长,男女说话者分别贡献了9.7小时和8.19小时。音频格式为WAV,采样率为48000Hz,录音质量达到工作室水平。每条音频文件均配有文本转录,确保了数据集的可用性和准确性。
使用方法
使用该数据集前,需仔细阅读并同意Indic TTS的使用许可。数据集可以从HuggingFace平台下载,并按照提供的配置文件进行数据加载和预处理。在研究和应用中使用此数据集时,应按照要求进行引用,以尊重原始数据集的贡献者及版权。
背景与挑战
背景概述
IndicTTS_Malayalam数据集,源自印度理工学院马德拉斯分校的语音技术联盟所开发的Indic TTS数据库项目,专注于马拉雅拉姆语的单语录音。该数据集包含男女两位母语为马拉雅拉姆语的说话者的高质量语音录音及其对应的文本转录,适用于文本到语音(TTS)的研究与开发。该项目由Speech Technology Consortium at IIT Madras负责,旨在为印度主要语言构建语音数据库,IndicTTS_Malayalam作为其中的一部分,对TTS技术在印度语言中的应用与发展具有重要影响。
当前挑战
在研究领域中,该数据集面临的挑战包括如何准确捕捉马拉雅拉姆语的语音特点,以实现自然流畅的TTS转换。此外,在构建过程中,确保录音的质量与一致性,以及文本转录的准确性,也是一大挑战。数据集的规模限制在1K到10K之间,可能会对模型的泛化能力提出挑战。在使用该数据集时,还需严格遵守原始Indic TTS的许可条款,以确保合法合规的使用。
常用场景
经典使用场景
在语音合成研究领域,IndicTTS_Malayalam数据集以其高质量的对应对 male 和 female 说话人的 Malayalam 言语录音及文本转录,成为文本到语音(TTS)模型训练与评估的宝贵资源。该数据集支持研究者深入探索语音合成系统的性能,特别是在保持语言自然度和表达丰富性方面。
衍生相关工作
基于IndicTTS_Malayalam数据集,学术界和工业界已开展了一系列相关工作,包括但不限于改进语音合成算法、构建多语言语音识别系统、以及开发面向特定语言群体的教育应用,推动了语音和语言处理技术的进步。
数据集最近研究
最新研究方向
在文本转语音(TTS)研究领域,IndicTTS_Malayalam数据集的推出为印度语言的高质量语音合成提供了重要资源。该数据集包含来自男女两位母语为Malayalam的说话者的录音,为TTS系统的训练和评估提供了丰富的语料。近期研究聚焦于利用此类数据集进一步优化声学模型和声码器,以提高语音合成的自然度和准确性。此外,通过分析不同性别说话者的语音特征,研究者能够开发出更加个性化的TTS系统,满足特定语言和文化背景的需求。IndicTTS_Malayalam数据集的应用不仅推动了语音合成技术的进步,也为印度语言的教育和技术普及带来了积极影响。
以上内容由遇见数据集搜集并总结生成


