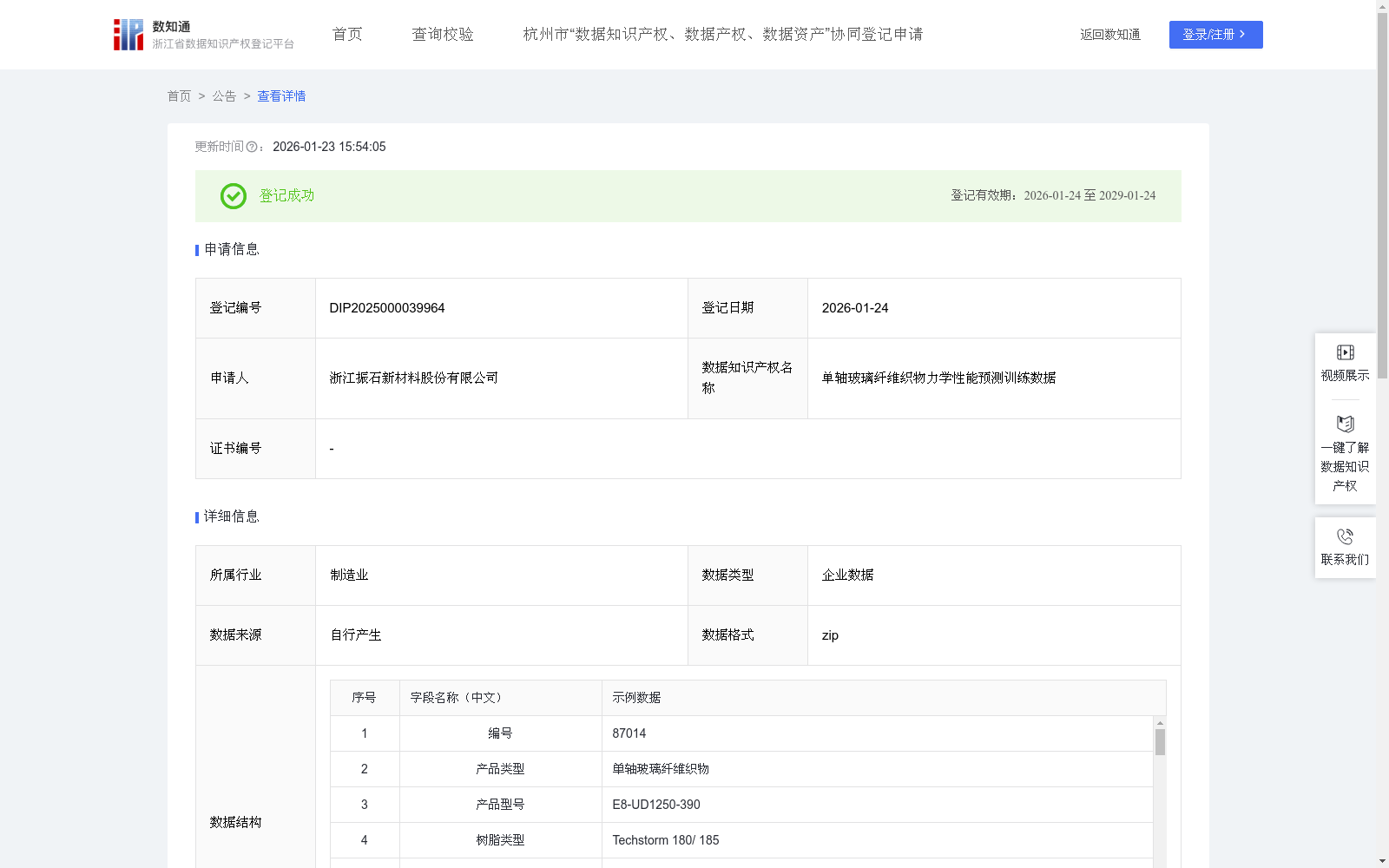
单轴玻璃纤维织物力学性能预测训练数据
收藏浙江省数据知识产权登记平台2026-01-23 更新2026-01-24 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8424307
下载链接
链接失效反馈官方服务:
资源简介:
本数据集收录超15万条玻璃纤维织物测试数据,且全部数据已完成存证,涵盖产品配方、工艺参数、特征属性及力学性能等关键工业数据。经标准化清洗与整合,形成完整的“工艺-性能”数据映射体系,具有覆盖全、质量高、关联性强的特点。具体应用场景包括但不限于:
一、 助力企业研发与生产
在研发阶段,利用数据规律快速筛选配方,节省成本、缩短周期;在生产阶段,支持实时监控与工艺调整,提升产品稳定性和一致性,为企业决策提供直接依据。
二、 用于训练智能模型与行业应用
数据集经过系统处理,标准规范、结构清晰,可为机器学习与人工智能模型提供高质量训练数据,以优化工艺、预测性能等,具有重要的行业应用价值。1.数据采集
(1)采集内容:①单轴玻璃纤维织物产品的基础信息(产品名称、产品型号);②产品配方(树脂类型、产品结构参数、纤维质量含量、纤维体积含量);③工艺参数(纱线方向以及纱线方向对应的原料规格、物料代码、单位面积克重-下限、单位面积克重-中心值、单位面积克重-上限);④产品特征参数(结构层次、方向、面积重量、公差、材料类型、涂层类型、特数值、丝径、树脂兼容性、缝合面积重量、缝合材料、缝合图案、绒向、总面积重量、总公差、卷宽公差、卷长公差、追踪纱线、织物厚度、保质期、存储条件);⑤力学性能(拉伸强度、拉伸模量、拉伸应变、拉伸泊松比、压缩强度、压缩模量、压缩应变、V剪切强度、V剪切模量)。
2.数据清洗与结构化
对于表格数据(如Excel和CSV文件),用工具读取并统一字段命名;对于PDF文件,通过文字识别提取内容;对于图片格式的数据(如JPEG),识别其中的表格区域并解析数值。接着,把所有数据转换成标准的JSON格式,把分类数据转换为数值,数值数据进行标准化处理,最终形成特征矩阵,方便后续分析。
3.特征工程与加权建模
基于随机森林多输出回归算法构建预测模型,自动学习20个输入特征与9个性能指标的非线性映射关系。通过特征重要性分析发现,树脂类型、纤维体积含量和纤维质量含量是决定产品质量的前三大关键因素。建立加权评分体系,为9项性能指标分配差异化权重,计算综合质量评分并划分四级等级:优秀(≥98)、良好[97-98)、合格[96-97)、不合格(<96)。对于不合格产品,通过归因分析定位问题根源,判定配方影响占比和工艺影响占比,并识别关键问题特征,给出针对性改进建议。
4.训练数据集构建
将处理后的15w+条样本数据按8:1:1比例划分为训练集、验证集和测试集。训练集包含特征矩阵X_train和目标矩阵y_train用于模型学习,验证集用于超参数调优和模型选择,测试集用于最终性能评估。所有数据经LabelEncoder编码和StandardScaler标准化处理确保模型收敛。同时保存预处理器、参考基准值、权重配置等元数据,封装为完整的模型资产包。模型在测试集上达到平均MAPE=2.64%的高精度预测,证明了从原始多源异构数据到智能决策系统的成功转化,形成可复用的数据知识产权成果。
提供机构:
浙江振石新材料股份有限公司
创建时间:
2025-12-26
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个专注于单轴玻璃纤维织物力学性能预测的训练数据集,收录了超过15万条涵盖产品配方、工艺参数、特征属性和力学性能的测试数据,形成了完整的‘工艺-性能’数据映射体系。数据集经过标准化清洗和整合,具有覆盖全面、质量高和关联性强的特点,可用于企业研发生产优化以及训练机器学习模型进行性能预测。基于随机森林算法构建的预测模型实现了高精度预测(平均MAPE为2.64%),并集成了加权评分体系对产品质量进行等级评估,为工业应用提供了可靠的数据支持。
以上内容由遇见数据集搜集并总结生成


