splash-art-gacha-collection-10k
收藏Hugging Face2025-01-02 更新2025-01-03 收录
下载链接:
https://huggingface.co/datasets/mrzjy/splash-art-gacha-collection-10k
下载链接
链接失效反馈官方服务:
资源简介:
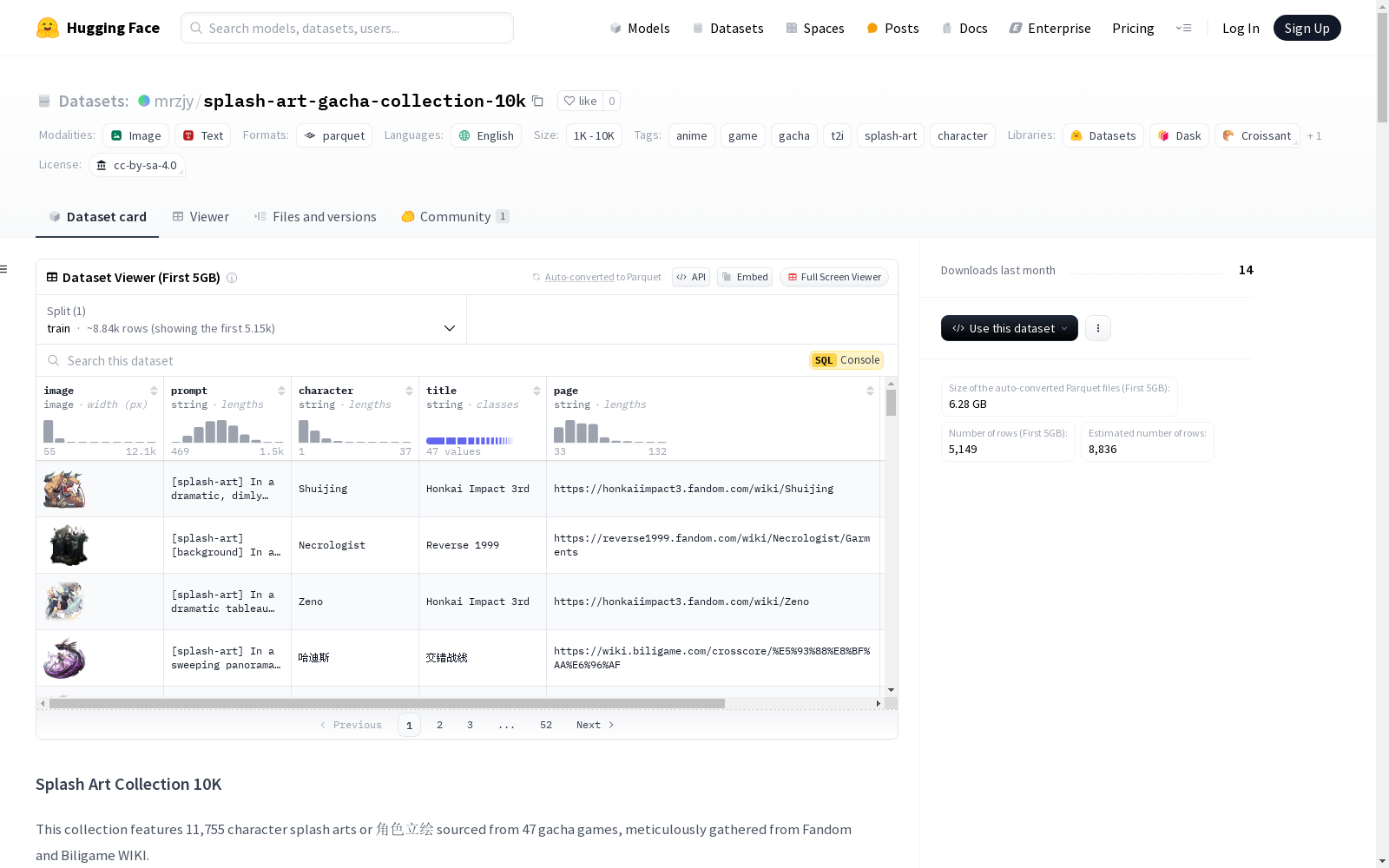
该数据集包含来自47款抽卡游戏的11,755张角色立绘,适合用于微调T2I模型以生成角色立绘。数据集中包含不同风格的高质量和低质量立绘,用户可以根据需要选择适合的图像进行训练。数据集的结构包括图像、提示文本、角色名称、标题、页面链接和额外信息等字段。
This dataset comprises 11,755 character illustrations sourced from 47 gacha games, and is suitable for fine-tuning Text-to-Image (T2I) models to generate character illustrations. The dataset includes high-quality and low-quality illustrations across diverse styles, allowing users to select appropriate images for training based on their specific needs. The structure of the dataset contains fields such as images, prompt texts, character names, titles, page links, and additional information.
创建时间:
2024-12-31
原始信息汇总
Splash Art Collection 10K 数据集概述
数据集基本信息
- 许可证: CC BY-SA 4.0
- 语言: 英语
- 标签: 动漫、游戏、扭蛋、T2I、角色立绘
- 规模: 10K < n < 100K
数据集内容
- 数据来源: 47款扭蛋游戏的角色立绘,主要来自Fandom和Biligame WIKI。
- 数据量: 11,755张角色立绘。
- 适用场景: 适用于微调T2I模型,生成角色立绘。
数据结构
- image: PIL.Image对象,表示不同尺寸的图像。
- prompt: 文本到图像(T2I)生成提示。
- character: 图像中角色的名称。
- title: 与角色相关的标题(如游戏名称)。
- page: 角色页面的参考链接。
- extra: 额外的信息或元数据(JSON字符串)。
数据筛选
- 筛选标准: 图像是否描绘全身角色,使用Qwen2-VL-7B-Instruct进行分类,非全身角色的图像被排除。
数据更新
- 2025.01.02: 数据集首次发布。
- 2025.xx.xx: 计划在不进行额外筛选的情况下,对整个数据集进行FLUX-dev模型的微调。
数据展示
- 展示: 包含多个游戏的示例图像,所有图像均调整为256x256尺寸。
- 分布: 包含标题分布的统计图。
获取T2I提示的步骤
- 图像分类: 将图像分为有背景和无背景两类。
- 生成详细描述: 使用Qwen2-VL-72B-Instruct生成高度详细的图像描述。
- 生成T2I提示: 使用GPT-4o-Mini生成T2I提示,根据背景情况在提示前添加"[splash-art]"或"[splash-art][background]"。
使用示例
python from datasets import load_dataset import json
ds = load_dataset(mrzjy/splash-art-gacha-collection-10k)
for s in ds["train"]: print(s) extra = json.loads(s["extra"]) break
附录
- Qwen2-VL描述生成提示: 包含有背景和无背景图像的详细描述生成提示。
- GPT-4o-Mini T2I提示生成提示: 包含有背景和无背景图像的T2I提示生成提示。
搜集汇总
数据集介绍
构建方式
该数据集从47款抽卡游戏中精心收集了11,755张角色立绘,主要来源为Fandom和Biligame WIKI。数据集的构建过程包括对图像进行筛选,确保每张图像都展示全身角色,并通过Qwen2-VL-7B-Instruct模型进行分类。此外,文本到图像(T2I)提示的生成采用了多步骤方法,首先将图像分为有背景和无背景两类,随后使用Qwen2-VL-72B-Instruct模型生成详细的图像描述,最后通过GPT-4o-Mini模型生成最终的T2I提示。
特点
该数据集涵盖了多种风格的高质量和低质量角色立绘,适用于文本到图像生成模型的微调。数据集中的每张图像都附带了详细的元数据,包括角色名称、游戏标题、参考链接以及额外的JSON格式信息。这些信息不仅为图像提供了丰富的上下文,还为研究人员和开发者提供了灵活的选择空间,以满足不同的训练需求。
使用方法
使用该数据集时,可以通过Hugging Face的`load_dataset`函数加载数据。数据集中的每个样本包含图像、T2I提示、角色名称、游戏标题、参考链接以及额外的JSON格式信息。开发者可以通过解析`extra`字段获取更多背景信息,从而更好地利用这些数据进行模型训练或分析。此外,数据集的结构设计使得用户可以轻松地筛选和选择适合其需求的图像,进一步提升了数据的使用效率。
背景与挑战
背景概述
Splash Art Gacha Collection 10K数据集于2025年首次发布,由多个研究团队共同构建,旨在为文本到图像生成模型(T2I)提供高质量的动漫角色立绘数据。该数据集包含来自47款抽卡游戏的11,755张角色立绘,涵盖了多种风格和质量的图像,主要应用于动漫角色立绘生成领域。数据集的构建基于Fandom和Biligame WIKI的公开资源,通过精细的筛选和标注,确保了数据的多样性和实用性。该数据集的发布为动漫游戏领域的图像生成研究提供了重要的数据支持,推动了T2I模型在角色立绘生成中的应用。
当前挑战
Splash Art Gacha Collection 10K数据集在构建过程中面临多重挑战。首先,数据筛选的准确性至关重要,尽管使用了Qwen2-VL-7B-Instruct模型进行全角色立绘的筛选,但仍存在误判的可能性。其次,文本到图像提示的生成过程复杂,涉及多步模型处理,包括图像分类、详细描述生成以及最终的提示优化,每一步都可能引入误差。此外,数据集中包含的图像质量参差不齐,如何在训练过程中有效利用这些数据,避免低质量图像对模型性能的负面影响,也是一个亟待解决的问题。这些挑战不仅影响了数据集的构建效率,也对后续模型的训练和应用提出了更高的要求。
常用场景
经典使用场景
在动漫与游戏角色设计领域,`splash-art-gacha-collection-10k`数据集为研究者提供了丰富的角色立绘资源。该数据集包含来自47款抽卡游戏的11,755张角色立绘,涵盖了多种风格与质量,适用于文本到图像生成模型的微调。通过结合`image`和`prompt`字段,研究者可以训练出能够生成高质量角色立绘的模型,为游戏开发与动漫创作提供技术支持。
衍生相关工作
基于`splash-art-gacha-collection-10k`数据集,研究者们开展了一系列相关研究。例如,利用该数据集微调的FLUX-dev模型在角色立绘生成任务中表现出色,成为该领域的经典工作之一。此外,结合Qwen2-VL和GPT-4o-Mini的提示生成方法也为文本到图像生成模型的优化提供了新的思路,推动了生成式人工智能技术的发展。
数据集最近研究
最新研究方向
在动漫与游戏领域,角色立绘的生成技术正逐渐成为研究热点。Splash Art Collection 10K数据集为这一领域提供了丰富的资源,涵盖了来自47款抽卡游戏的11,755张角色立绘。该数据集的最新研究方向聚焦于利用文本到图像(T2I)生成模型进行角色立绘的精细化生成。通过结合图像与文本提示,研究者能够训练出更具表现力和艺术感的生成模型。此外,该数据集还支持对不同风格和质量的立绘进行筛选和优化,为个性化生成提供了可能。这一研究方向不仅推动了动漫游戏美术设计的技术进步,也为相关产业的自动化创作工具开发提供了重要支持。
以上内容由遇见数据集搜集并总结生成


