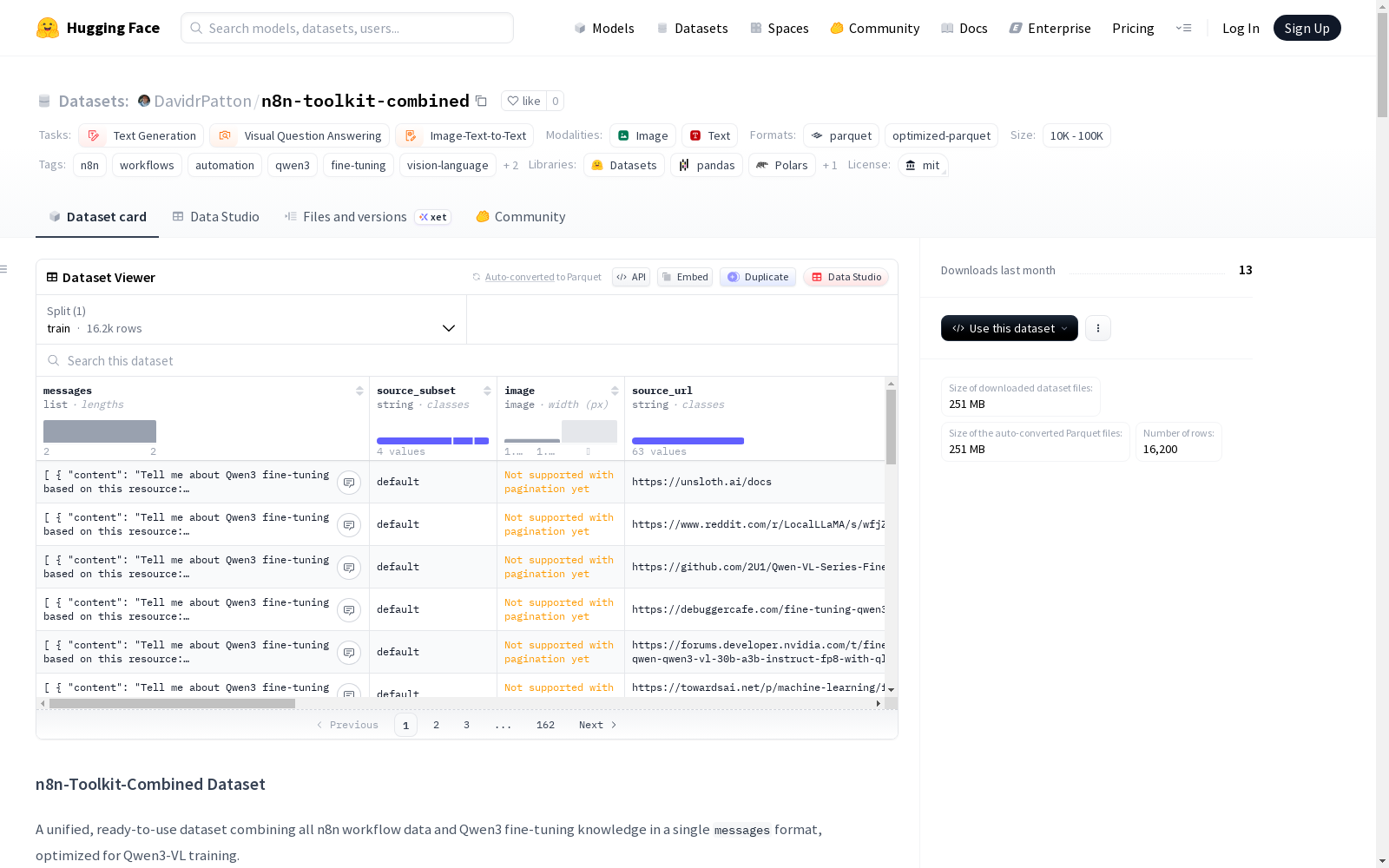
n8n-toolkit-combined
收藏资源简介:
n8n-Toolkit-Combined数据集是一个统一且即用的数据集,结合了所有n8n工作流数据和Qwen3微调知识,采用'messages'格式,专为Qwen3-VL训练优化。数据集包含16,178个示例,其中2,274个视觉示例带有图像和工作流JSON,90个Qwen3微调示例包含全面知识。所有数据均采用统一的'messages'格式,便于直接用于训练。数据集还提供了详细的统计信息、使用方法、数据模式、数据质量评估以及训练建议。
n8n-Toolkit-Combined 数据集概述
数据集基本信息
- 数据集名称: n8n-Toolkit-Combined
- 维护者: David Patton
- 托管地址: https://huggingface.co/datasets/DavidrPatton/n8n-toolkit-combined
- 许可证: MIT License
- 任务类别: 文本生成、视觉问答、图像文本到文本
- 标签: n8n、workflows、automation、qwen3、fine-tuning、vision-language、multimodal、combined
- 数据规模: 10K<n<100K
- 最新更新: 2025-01-05
数据集摘要
一个统一、即用的数据集,将所有n8n工作流数据和Qwen3微调知识合并为单一的messages格式,专为Qwen3-VL训练优化。
核心内容
- 总样本数: 16,178个对话格式示例
- 视觉样本: 2,274个带图像和工作流JSON的示例
- Qwen3微调知识样本: 90个综合知识示例
- 数据格式: 所有数据均为可直接用于训练的
messages格式
数据构成与统计
子集分布
| 子集 | 示例数量 | 描述 |
|---|---|---|
sharegpt |
10,827 | 对话式n8n工作流数据 |
thinking |
2,987 | 思维链推理示例 |
vision |
2,274 | 图像 + JSON对(全部包含图像) |
default |
90 | Qwen3微调知识 |
| 总计 | 16,178 | 统一格式的所有示例 |
视觉示例详情
- 图像数量: 2,274个工作流截图
- 图像格式: PNG,RGB模式,1878x983像素
- JSON覆盖率: 100%(所有图像均有匹配的工作流JSON)
- 格式增强: 采用结构化提示以优化训练
数据结构与特征
统一模式
所有示例均使用与Qwen3-VL及其他指令调优模型兼容的标准messages格式。
完整特征列表
python { "messages": [{"role": "string", "content": "string"}], # 必需 "source_subset": "string", # default, sharegpt, thinking, vision "image": Image | None, # 视觉示例的PIL图像 "source_url": "string", "source_title": "string", "topic": "string", "scraped_at": "string", "id": "string", # 用于视觉示例 "description": "string", # 用于视觉示例 "workflow_json": "string", # 用于视觉示例 "node_count": int, # 用于视觉示例 "source": "string", "category": "string", "domain": "string", "complexity": "string", "instruction": "string", "input": "string", "output": "string", "prompt": "string", # 用于thinking示例 "json": "string", # 用于thinking示例 "thinking": "string", # 用于thinking示例 }
数据质量
质量增强
- 错误条目移除: 所有403、401及"Error scraping"条目已被过滤
- 视觉示例增强: 采用结构化提示以优化图像-文本对
- 100%图像+JSON覆盖率: 每个视觉示例均包含图像和工作流JSON
- 统一模式: 所有子集已转换为一致的
messages格式 - 元数据保留: 所有原始字段均被保留以支持筛选
质量指标
- 视觉示例: 2,274个带图像的示例(覆盖率100%)
- 图像+JSON对: 2,274个(覆盖率100%)
- Qwen3示例: 90个综合知识条目
- 错误条目: 0个(已全部移除)
使用说明
加载数据集
python from datasets import load_dataset dataset = load_dataset("DavidrPatton/n8n-toolkit-combined", token="your_token")
按子集筛选
python
获取仅视觉示例
vision_examples = [ex for ex in train if ex[source_subset] == vision]
获取Qwen3微调示例
qwen3_examples = [ex for ex in train if ex[source_subset] == default and qwen3 in ex.get(topic, ).lower()]
访问图像
python for example in train: if example[source_subset] == vision and example[image] is not None: image = example[image] # PIL Image对象 workflow_json = example[workflow_json] # JSON字符串
训练建议
针对Qwen3-VL训练
- 筛选
source_subset == vision以获取视觉-语言示例 - 每个示例均包含请求工作流分析的结构化提示
- 图像质量高且格式正确
- 所有工作流JSON均完整且经过验证
针对指令调优
- 使用所有示例进行通用指令调优
- 按
source_subset筛选以满足特定训练需求 default子集中的Qwen3知识可用于微调专业知识
针对推理任务
- 筛选
source_subset == thinking以获取思维链示例 - 示例包含逐步推理和JSON输出
重要注意事项
- 图像查看器限制: HuggingFace数据集查看器对图像显示"Not supported with pagination yet",这仅是查看器限制,图像在数据集中完全存储且可通过代码访问。
- 图像查看方法:
- 使用原始的
n8n-Toolkit视觉子集(所有图像可见) - 通过代码访问(图像完全可访问)
- 筛选仅视觉示例
- 使用原始的
与原始数据集的比较
| 特性 | n8n-Toolkit | n8n-toolkit-combined |
|---|---|---|
| 格式 | 多种模式 | 统一的messages格式 |
| 子集 | 4个独立子集 | 单个train分割 |
| 图像 | 在查看器中可见 | 查看器有限制(但可访问) |
| 使用 | 按子集加载 | 一次性加载全部 |
| 训练 | 需要转换 | 可直接使用 |
引用
bibtex @dataset{n8n_toolkit_combined_2025, title={n8n-Toolkit-Combined: Unified Dataset for n8n Workflow Understanding and Qwen3 Fine-Tuning}, author={Patton, David}, year={2025}, url={https://huggingface.co/datasets/DavidrPatton/n8n-toolkit-combined} }
相关数据集
- DavidrPatton/n8n-Toolkit: https://huggingface.co/datasets/DavidrPatton/n8n-Toolkit(包含独立子集的原始数据集)